150B token從頭訓練,普林斯頓Meta發布完全可微MoE架構Lory
不同于大多數模型使用字母縮略起名,論文作者在腳注中解釋道,Lory是一種羽毛有彩虹顏色的鸚鵡,和「軟MoE」的精神非常相似。

論文的作者團隊也可以稱之為「明星陣容」。
 論文地址:https://arxiv.org/abs/2405.03133
論文地址:https://arxiv.org/abs/2405.03133
主要作者之一陳丹琦是普林斯頓大學計算機科學系的助理教授,也是普林斯頓NLP小組共同領導人之一。她本科畢業于清華大學姚班,2018年在斯坦福大學獲得博士學位,導師是大名鼎鼎的Christopher Manning。
斯坦福教授、NLP領域泰斗Dan Jurafsky曾這樣評價她:「她在發現重要的研究問題上很有品位。她已經對該領域產生了非凡的影響,并且她的影響只會越來越大。」

Mike Lewis是Meta AI的一名研究科學家,他領導了Meta剛發布的大語言模型Llama 3的預訓練工作。

他此前曾發表過多項有影響力的研究成果,包括Bart、Roberta、top-k采樣等。
本文的第一作者是普林斯頓大學五年級博士生鐘澤軒,導師是陳丹琪教授。

鐘澤軒碩士畢業于伊利諾伊大學香檳分校,本科畢業于北京大學計算機系,曾在Meta AI和微軟亞洲研究院實習,這項研究就是他在Meta實習期間完成的。
發布后,論文作者也在推特上提供了全文解讀。

引入的關鍵技術包含兩個方面,一是用因果分段路由策略取代token級別的路由,可以在保持語言模型自回歸屬性的同時實現高效的專家合并。
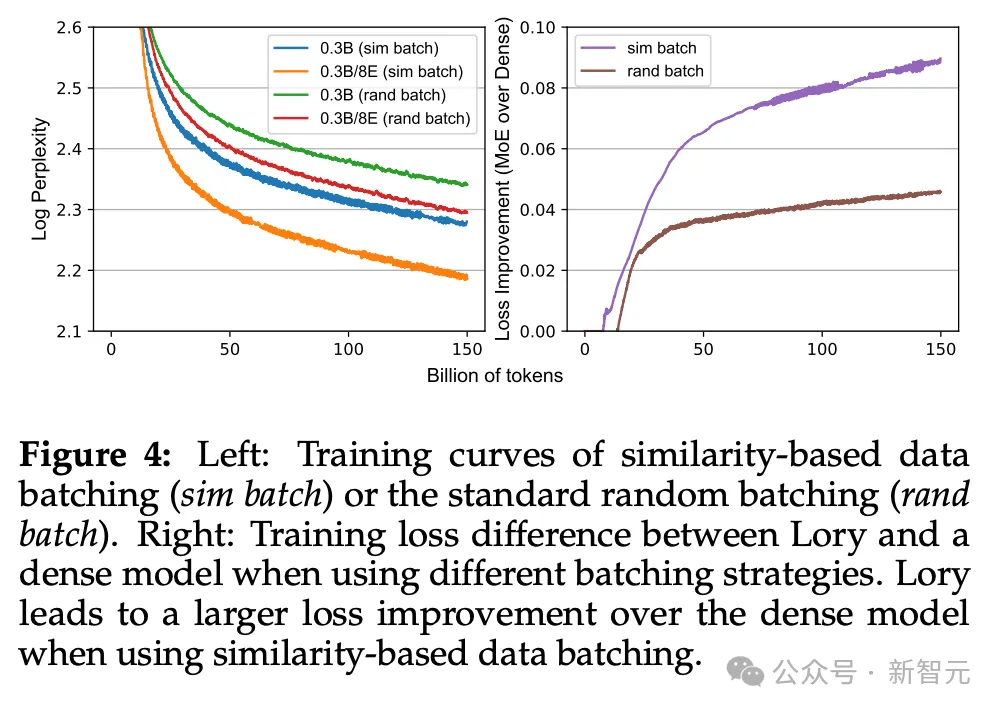
二是提出了基于相似性的數據批處理方法,如果僅僅是把隨機選擇的文本拼接在一起訓練會導致低水平的專家模型,而將相似的文本進行分組可以使模型更加專業化。

基于這些方法,作者使用150B token的數據從頭訓練了一系列的Lory模型,活躍參數有0.3B和1.5B兩個級別,含有最多32個專家。
與稠密模型相比,Lory的訓練過程更為高效,可以用少2.5倍的步數實現相同的損失值。
研究團隊使用上下文學習的方法評估Lory的能力,發現模型在常識推理、閱讀理解、閉卷問答、文本分類等下游任務上都取得了很好的效果。
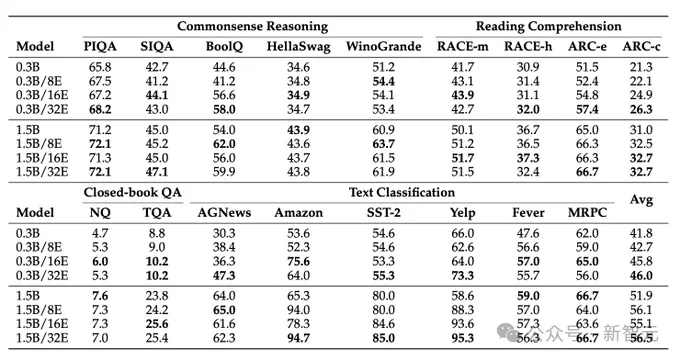
可以觀察到,使用更多專家可以改進模型的表現。
相比目前MoE領域的SOTA模型Expert Choice(EC),Lory模型也表現出了有競爭力的性能。

2023年12月,一家名為Mistral AI的法國創業公司發布了一款性能媲美甚至優于GPT-3.5和Llama 2 70B的模型Mixtral 8x7B。
Mixtral使用了一種稀疏的MoE網絡,不僅表現出了強大的性能,而且十分高效,推理速度相比Llama 2 70B提高了6倍,于是讓MoE得到了開源社區的廣泛關注。
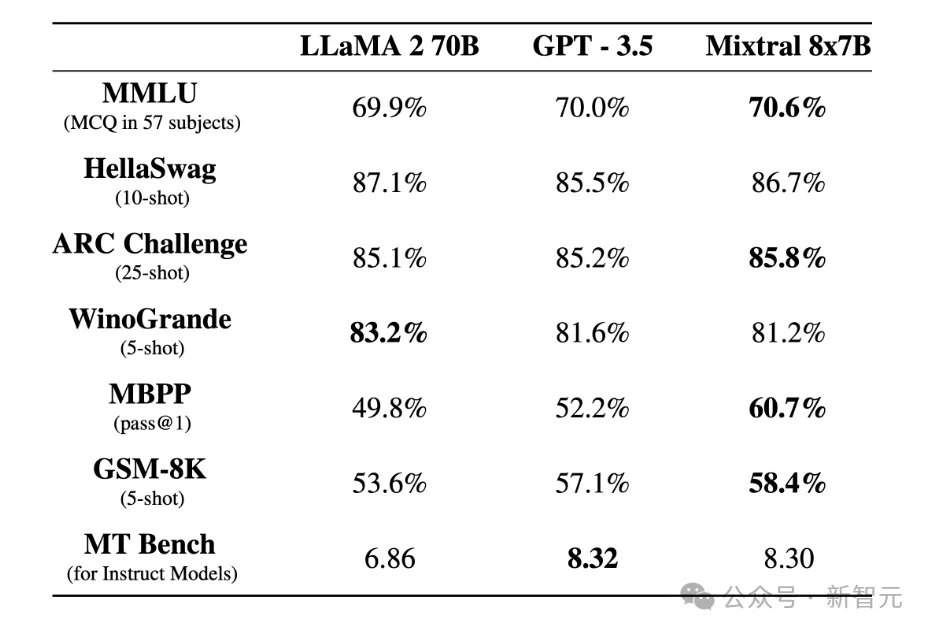
甚至有人猜測,GPT-4可能也使用了MoE技術實現了超過一萬億參數的超大模型。
對于Transformer架構的語言模型,MoE主要有兩個元素:
一是使用參數更為稀疏的MoE層代替密集的前饋網絡層(FFN),其中每個專家都是一個獨立的神經網絡,甚至可以是MoE本身,從而形成層級式的MoE結構。
二是使用門控網絡或路由機制決定token被發送到哪個專家,其中token的路由機制是決定MoE模型表現的關鍵點。
因果分段路由
雖然MoE的這種機制有助于高效擴展模型規模,但訓練路由網絡的過程會引入離散化、不可微的學習目標。2023年發布的SMEAR模型就已經開始探索解決方案,使用專家合并方法構建完全可微的MoE模型。

論文地址:https://arxiv.org/abs/2306.03745
然而,SMEAR使用的方法是將所有專家進行軟合并,取其加權平均值,這適用于文本分類任務,但很難應用到自回歸語言模型上。
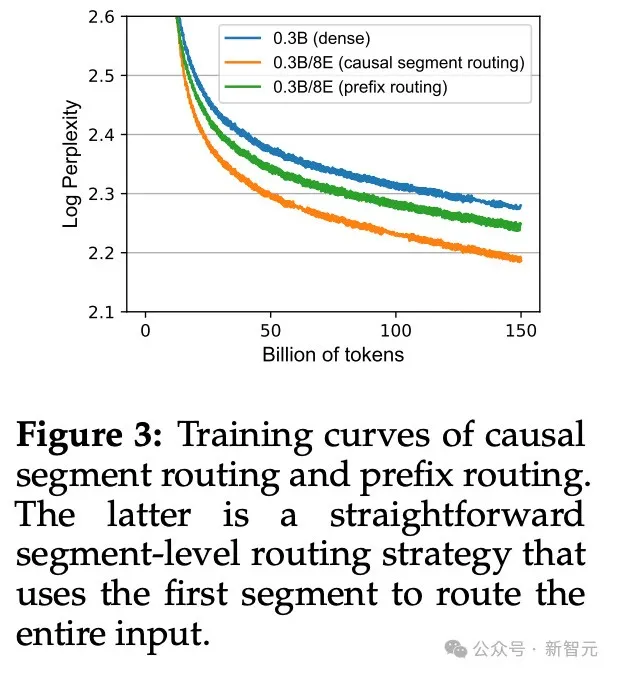
于是,作者提出了使用分段路由的方法,對每一段語句而非每個token進行專家合并,有效減少了合并操作的數量。
如果僅僅使用當前語段進行路由,很可能導致語言模型遺漏跨語段的信息,所以論文提出采用類似于自回歸的因果分段路由。
在為當前語段合并專家時,需要考慮前一個語段的信息,從而決定每個專家的路由權重。

消融實驗的結果也證明,與因果分段路由的策略相比,單純使用前綴進行路由會導致語言模型性能降低。
基于相似性的數據批處理
預訓練語言模型的標準做法是將數據集中的文檔隨機拼接在一起,構造出固定長度的訓練樣本。
對于MoE模型而言,這種方法存在問題,相鄰段的token可能來自非常不同且毫不相關的文檔,可能會損害專家模型的專業化程度。
因此,受到ICLR 2024中一篇論文的啟發,作者在Lory中采用了類似的技術,依次連接相似的文檔來構造訓練樣本,使專家模型更「專注」地研究不同的領域或主題。

論文地址:https://arxiv.org/abs/2310.10638
實驗表明,無論是隨機批處理還是基于相似度批處理,Lory模型的效果都優于稠密模型,但使用基于相似度的方法可以得到更大的loss提升。