騰訊互娛面經詳解
先來嘮嘮
 圖片
圖片
今天刷脈脈的時候, 發現百度副總裁璩靜一個人竟然占了前三的兩個熱榜, 對于她的離職你怎么看?
言歸正傳, 本文的重點還是分享面經干貨
今天分享的是一位朋友在騰訊互娛的面經, 他本人目前已經是收到offer了, 讓我們來看看這個難度如何:
 圖片
圖片
面試題詳解
Go接口
接口在Golang中扮演著連接不同類型之間的橋梁,它定義了一組方法的集合,而不關心具體的實現。接口的作用主要體現在以下幾個方面:
多態性:
接口允許不同的類型實現相同的方法,從而實現多態性。這意味著我們可以使用接口類型來處理不同的對象,而不需要關心具體的類型。
package main
import "fmt"
type Animal interface {
Sound() string
}
type Dog struct{}
func (d Dog) Sound() string {
return "Woof!"
}
type Cat struct{}
func (c Cat) Sound() string {
return "Meow!"
}
func main() {
animals := []Animal{Dog{}, Cat{}}
for _, animal := range animals {
fmt.Println(animal.Sound())
}
}在上面的示例中,我們定義了一個Animal接口,它包含了一個Sound()方法。然后,我們實現了Dog和Cat兩個結構體,分別實現了Sound()方法。通過將Dog和Cat類型賦值給Animal接口類型,我們可以在循環中調用Sound()方法,而不需要關心具體的類型。這就體現了接口的多態性,不同的類型可以實現相同的接口方法。
解耦合:
接口可以將抽象與實現分離,降低代碼之間的耦合度。通過定義接口,我們可以將實現細節隱藏起來,只暴露必要的方法,從而提高代碼的可維護性和可讀性。
package main
import "fmt"
type Printer interface {
Print(string)
}
type ConsolePrinter struct{}
func (cp ConsolePrinter) Print(message string) {
fmt.Println(message)
}
type FilePrinter struct{}
func (fp FilePrinter) Print(message string) {
// 將消息寫入文件
fmt.Println("Writing message to file:", message)
}
func main() {
printer := ConsolePrinter{}
printer.Print("Hello, World!")
printer = FilePrinter{}
printer.Print("Hello, World!")
}在上面的示例中,我們定義了一個Printer接口,它包含了一個Print()方法。然后,我們實現了ConsolePrinter和FilePrinter兩個結構體,分別實現了Print()方法。通過將不同的結構體賦值給Printer接口類型的變量,我們可以在主函數中調用Print()方法,而不需要關心具體的實現。這樣,我們可以根據需要輕松地切換不同的打印方式,實現了解耦合。
可擴展性:
package main
import "fmt"
type Shape interface {
Area() float64
}
type Rectangle struct {
Width float64
Height float64
}
func (r Rectangle) Area() float64 {
return r.Width * r.Height
}
type Circle struct {
Radius float64
}
func (c Circle) Area() float64 {
return 3.14 * c.Radius * c.Radius
}
func main() {
shapes := []Shape{Rectangle{Width: 5, Height: 10}, Circle{Radius: 3}}
for _, shape := range shapes {
fmt.Println("Area:", shape.Area())
}
}在上面的示例中,我們定義了一個Shape接口,它包含了一個Area()方法。然后,我們實現了Rectangle和Circle兩個結構體,分別實現了Area()方法。通過將不同的結構體賦值給Shape接口類型的切片,我們可以在循環中調用Area()方法,而不需要關心具體的類型。這樣,當我們需要添加新的形狀時,只需要實現Shape接口的Area()方法即可,而不需要修改已有的代碼。這就實現了代碼的可擴展性。
接口的應用場景
- API設計:接口在API設計中起到了至關重要的作用。通過定義接口,我們可以規范API的輸入和輸出,提高代碼的可讀性和可維護性。
- 單元測試:接口在單元測試中也扮演著重要的角色。通過使用接口,我們可以輕松地替換被測試對象的實現,從而實現對被測代碼的獨立測試。
- 插件系統:接口可以用于實現插件系統,通過定義一組接口,不同的插件可以實現這些接口,并在程序運行時動態加載和使用插件。
- 依賴注入:接口在依賴注入中也有廣泛的應用。通過定義接口,我們可以將依賴對象的創建和管理交給外部容器,從而實現松耦合的代碼結構。
空結構體的用途
不包含任何字段的結構體,就叫做空結構體。
空結構體的特點:
- 零內存占用
- 地址都相同
- 無狀態
空結構體的使用場景
- 實現set集合
在 Go 語言中,雖然沒有內置 Set 集合類型,但是我們可以利用 map 類型來實現一個 Set 集合。由于 map 的 key 具有唯一性,我們可以將元素存儲為 key,而 value 沒有實際作用,為了節省內存,我們可以使用空結構體作為 value 的值。
package main
import "fmt"
type Set[K comparable] map[K]struct{}
func (s Set[K]) Add(val K) {
s[val] = struct{}{}
}
func (s Set[K]) Remove(val K) {
delete(s, val)
}
func (s Set[K]) Contains(val K) bool {
_, ok := s[val]
return ok
}
func main() {
set := Set[string]{}
set.Add("程序員")
fmt.Println(set.Contains("程序員")) // true
set.Remove("程序員")
fmt.Println(set.Contains("程序員")) // false
}- 用于通道信號
空結構體常用于 Goroutine 之間的信號傳遞,尤其是不關心通道中傳遞的具體數據,只需要一個觸發信號時。例如,我們可以使用空結構體通道來通知一個 Goroutine 停止工作:
package main
import (
"fmt"
"time"
)
func main() {
quit := make(chan struct{})
go func() {
// 模擬工作
fmt.Println("工作中...")
time.Sleep(3 * time.Second)
// 關閉退出信號
close(quit)
}()
// 阻塞,等待退出信號被關閉
<-quit
fmt.Println("已收到退出信號,退出中...")
}- 作為方法接收器
有時候我們需要創建一組方法集的實現(一般來說是實現一個接口),但并不需要在這個實現中存儲任何數據,這種情況下,我們可以使用空結構體來實現:
type Person interface {
SayHello()
Sleep()
}
type CMY struct{}
func (c CMY) SayHello() {
fmt.Println("你好,世界。")
}
func (c CMY) Sleep() {
fmt.Println("晚安,世界...")
}Go原生支持默認參數或可選參數嗎,如何實現
什么是默認參數
默認參數是指在函數調用時,如果沒有提供某個參數的值,那么使用函數定義中指定的默認值。這種語言特性可以減少代碼量,簡化函數的使用。
在Go語言中,函數不支持默認參數。這意味著如果我們想要設置默認值,那么就需要手動在函數內部進行處理。
例如,下面是一個函數用于計算兩個整數的和:
func Add(a int, b int) int {
return a + b
}如果我們希望b參數有一個默認值,例如為0,那么可以在函數內部進行處理:
func AddWithDefault(a int, b int) int {
if b == 0 {
b = 0
}
return a + b
}上面的代碼中,如果b參數沒有提供值,那么默認為0。通過這種方式,我們就實現了函數的默認參數功能。
需要注意的是,這種處理方式雖然可以實現默認參數的效果,但會增加代碼復雜度和維護難度,因此在Go語言中不被推薦使用。
什么是可選參數
可選參數是指在函數調用時,可以省略一些參數的值,從而讓函數更加靈活。這種語言特性可以讓函數更加易用,提高代碼的可讀性。
在Go語言中,函數同樣不支持可選參數。但是,我們可以使用可變參數來模擬可選參數的效果。
下面是一個函數用于計算任意個整數的和:
func Add(nums ...int) int {
sum := 0
for _, num := range nums {
sum += num
}
return sum
}上面的代碼中,我們使用...int類型的可變參數來接收任意個整數,并在函數內部進行求和處理。
如果我們希望b和c參數為可選參數,那么可以將它們放到nums可變參數之后:
func AddWithOptional(a int, nums ...int) int {
sum := a
for _, num := range nums {
sum += num
}
return sum
}上面的代碼中,我們首先將a參數賦值給sum變量,然后對可變參數進行求和處理。如果函數調用時省略了nums參數,則sum等于a的值。
需要注意的是,使用可變參數模擬可選參數的效果雖然能夠實現函數的靈活性,但也會降低代碼的可讀性和規范性。因此在Go語言中不被推薦使用。
defer執行順序
在 Go 中,defer 語句用于延遲(defer)函數的執行,通常用于在函數執行結束前執行一些清理或收尾工作。當函數中存在多個 defer 語句時,它們的執行順序是“后進先出”(Last In First Out,LIFO)的,即最后一個被延遲的函數最先執行,倒數第二個被延遲的函數次之,以此類推。
在 Go 中,defer 語句中的函數在執行時會被壓入一個棧中,當函數執行結束時,這些被延遲的函數會按照后進先出的順序執行。這意味著在函數中的 defer 語句中的函數會在函數執行結束前執行,包括在 return 語句之前執行。
協程之間信息如何同步
協程(Goroutine)之間的信息同步通常通過通道(Channel)來實現。通道是 Go 語言中用于協程之間通信的重要機制,可以安全地在不同協程之間傳遞數據,實現協程之間的信息同步。
一些常見的方法來實現協程之間的信息同步:
- 使用無緩沖通道:無緩沖通道是一種同步通道,發送和接收操作會在數據準備好之前被阻塞。通過無緩沖通道,可以實現協程之間的同步通信,確保數據的正確傳遞。
- 使用帶緩沖通道:帶緩沖通道允許在通道中存儲一定數量的元素,發送操作只有在通道已滿時才會被阻塞。通過帶緩沖通道,可以實現異步通信。
- 使用同步原語:Go 語言中的 sync 包提供了一些同步原語,如互斥鎖(Mutex)、讀寫鎖(RWMutex)等,可以用于協程之間的同步訪問共享資源。
- 使用select語句:select 語句可以用于在多個通道操作中選擇一個執行,可以實現協程之間的多路復用和超時控制。
- 使用context包:context 包提供了一種在協程之間傳遞取消信號和截止時間的機制,可以用于協程之間的協調和同步。
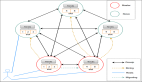
GMP模型
GM模型開銷大的原因?
最開始的是GM模型沒有 P 的,是M:N的兩級線程模型,但是會出現一些性能問題:
- 全局隊列的鎖競爭。M從全局隊列中添加或獲取 G 的時候,都是需要上鎖的(下圖執行步驟要加鎖),這樣就會導致鎖競爭,雖然達到了并發安全,但是性能是非常差的。
- M 轉移 G 會有額外開銷。M 在執行 G 的時候,假設 M1 執行的 G1 創建了 G2,新創建的就要放到全局隊列中去,但是這時有一個空閑的 M2 獲取到了 G2,那么這樣 G1、G2 會被不同的 M 執行,但是 M1 中本來就有 G2 的信息,M2 在 G1 上執行是更好的,而且取和放到全局隊列也會來回加鎖,這樣都會有一部分開銷。
- 線程的使用效率不能最大化。M 拿不到的時候就會一直空閑,阻塞的時候也不會切換。也就是沒有 workStealing 機制和 handOff 機制。
 圖片
圖片
GMP
 圖片
圖片
go生成一個協程,此時放在P中還是M中
如果在本地的隊列中有足夠的空間,則會直接進入本地隊列等待M的執行;如果本地隊列已經滿了,則進入全局隊列(在GMP模型中,所有的M都可以從全局隊列中獲取協程并執行)
G阻塞,M、P如何
當G因系統調用(syscall)阻塞時會阻塞M,此時P會和M解綁即hand off,并尋找新的idle的M,若沒有idle的M就會新建一個M
Redis與MySQL數據如何同步
這里提供幾種方案:
- 定時任務同步:編寫定時任務或腳本,定期從 MySQL 中讀取數據,然后將數據同步到 Redis 中。這種方案簡單直接,適用于數據量不大且同步頻率不高的場景。
- 使用消息隊列:將 MySQL 中的數據變更操作(如新增、更新、刪除)通過消息隊列(如 RabbitMQ、Kafka)發送到消息隊列中,然后消費者從消息隊列中讀取消息,將數據同步到 Redis 中。這種方案實現了異步同步,降低了對 MySQL 的壓力。
- 使用數據庫觸發器:在 MySQL 中設置觸發器,當數據發生變更時觸發觸發器,將變更信息發送到消息隊列或直接同步到 Redis 中。這種方案可以實現實時同步,但需要謹慎設計觸發器邏輯,避免影響數據庫性能。
- 使用數據同步工具:可以使用一些數據同步工具(如 Maxwell、Debezium)來實現 MySQL 和 Redis 數據的實時同步。這些工具可以監控 MySQL 數據庫的變更,并將變更數據同步到 Redis 中。
- 使用緩存庫:一些緩存庫(如 Redisson、Lettuce)提供了與 MySQL 數據庫的集成,可以通過配置簡單地實現 MySQL 數據到 Redis 的同步。
Explain的字段
explain的用法:
explain select * from gateway_apps;返回結果:
 圖片
圖片
下面對上面截圖中的字段一一解釋:
1、id:select 查詢序列號。id相同,執行順序由上至下;id不同,id值越大優先級越高,越先被執行。
2、select_type:查詢數據的操作類型,其值如下:
- simple:簡單查詢,不包含子查詢或 union
- primary:包含復雜的子查詢,最外層查詢標記為該值
- subquery:在 select 或 where 包含子查詢,被標記為該值
- derived:在 from 列表中包含的子查詢被標記為該值,MySQL 會遞歸執行這些子查詢,把結果放在臨時表
- union:若第二個 select 出現在 union 之后,則被標記為該值。若 union 包含在 from 的子查詢中,外層 select 被標記為 derived
- union result:從 union 表獲取結果的 select
3、table:顯示該行數據是關于哪張表
4、partitions:匹配的分區
5、type:表的連接類型,其值,性能由高到底排列如下:
- system:表只有一行記錄,相當于系統表
- const:通過索引一次就找到,只匹配一行數據
- eq_ref:唯一性索引掃描,對于每個索引鍵,表中只有一條記錄與之匹配。常用于主鍵或唯一索引掃描
- ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。用于=、< 或 > 操作符帶索引的列
- range:只檢索給定范圍的行,使用一個索引來選擇行。一般使用between、>、<情況
- index:只遍歷索引樹
- ALL:全表掃描,性能最差
6、 possible_keys:顯示 MySQL 理論上使用的索引,查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢實際使用。如果該值為 NULL,說明沒有使用索引,可以建立索引提高性能
7、key:顯示 MySQL 實際使用的索引。如果為 NULL,則沒有使用索引查詢
8、key_len:表示索引中使用的字節數,通過該列計算查詢中使用的索引的長度。在不損失精確性的情況下,長度越短越好 顯示的是索引字段的最大長度,并非實際使用長度
9、ref:顯示該表的索引字段關聯了哪張表的哪個字段
10、 rows:根據表統計信息及選用情況,大致估算出找到所需的記錄或所需讀取的行數,數值越小越好
11、filtered:返回結果的行數占讀取行數的百分比,值越大越好
12、extra:包含不合適在其他列中顯示但十分重要的額外信息,常見的值如下:
- using filesort:說明 MySQL 會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取。出現該值,應該優化 SQL
- using temporary:使用了臨時表保存中間結果,MySQL 在對查詢結果排序時使用臨時表。常見于排序 order by 和分組查詢 group by。出現該值,應該優化 SQL
- using index:表示相應的 select 操作使用了覆蓋索引,避免了訪問表的數據行,效率不錯
- using where:where 子句用于限制哪一行
- using join buffer:使用連接緩存
- distinct:發現第一個匹配后,停止為當前的行組合搜索更多的行
Redis過期刪除策略
Redis 中提供了三種過期刪除的策略
定時刪除
在設置某個 key 的過期時間同時,我們創建一個定時器,讓定時器在該過期時間到來時,立即執行對其進行刪除的操作。
優點:
對 CPU 是友好的,只有在取出鍵值對的時候才會進行過期檢查,這樣就不會把 CPU 資源花費在其他無關緊要的鍵值對的過期刪除上。
缺點:
如果一些鍵值對永遠不會被再次用到,那么將不會被刪除,最終會造成內存泄漏,無用的垃圾數據占用了大量的資源,但是服務器卻不能去刪除。
惰性刪除
惰性刪除,當一個鍵值對過期的時候,只有再次用到這個鍵值對的時候才去檢查刪除這個鍵值對,也就是如果用不著,這個鍵值對就會一直存在。
優點:
對 CPU 是友好的,只有在取出鍵值對的時候才會進行過期檢查,這樣就不會把 CPU 資源花費在其他無關緊要的鍵值對的過期刪除上。
缺點:
如果一些鍵值對永遠不會被再次用到,那么將不會被刪除,最終會造成內存泄漏,無用的垃圾數據占用了大量的資源,但是服務器卻不能去刪除。
定期刪除
定期刪除是對上面兩種刪除策略的一種整合和折中
每個一段時間就對一些 key 進行采樣檢查,檢查是否過期,如果過期就進行刪除
1、采樣一定個數的key,采樣的個數可以進行配置,并將其中過期的 key 全部刪除;
2、如果過期 key 的占比超過可接受的過期 key 的百分比,則重復刪除的過程,直到過期key的比例降至可接受的過期 key 的百分比以下。
優點:
定期刪除,通過控制定期刪除執行的時長和頻率,可以減少刪除操作對 CPU 的影響,同時也能較少因過期鍵帶來的內存的浪費。
缺點:
執行的頻率不太好控制
頻率過快對 CPU 不友好,如果過慢了就會對內存不太友好,過期的鍵值對不能及時的被刪除掉
同時如果一個鍵值對過期了,但是沒有被刪除,這時候業務再次獲取到這個鍵值對,那么就會獲取到被刪除的數據了,這肯定是不合理的。
Redis 中過期刪除策略
上面討論的三種策略,都有或多或少的問題。Redis 中實際采用的策略是惰性刪除加定期刪除的組合方式。
定期刪除,獲取 CPU 和 內存的使用平衡,針對過期的 KEY 可能得不到及時的刪除,當 KEY 被再次獲取的時候,通過惰性刪除再做一次過期檢查,來避免業務獲取到過期內容。
Redis常用數據結構
Redis 共有 5 種基本數據類型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
Zset使用場景, 具體實現
Zset的兩種實現方式:
- ziplist:滿足以下兩個條件的時候
- 元素數量少于128的時候
- 每個元素的長度小于64字節
- skiplist:不滿足上述兩個條件就會使用跳表,具體來說是組合了map和skiplist
- map用來存儲member到score的映射,這樣就可以在O(1)時間內找到member對應的分數
- skiplist按從小到大的順序存儲分數
- skiplist每個元素的值都是[score,value]對
skiplist優勢
skiplist本質上是并行的有序鏈表,但它克服了有序鏈表插入和查找性能不高的問題。它的插入和查詢的時間復雜度都是O(logN)
skiplist原理
普通有序鏈表的插入需要一個一個向前查找是否可以插入,所以時間復雜度為O(N),比如下面這個鏈表插入23,就需要一直查找到22和26之間。
 圖片
圖片
如果節點能夠跳過一些節點,連接到更靠后的節點就可以優化插入速度:
 圖片
圖片
在上面這個結構中,插入23的過程是
- 先使用第2層鏈接head->7->19->26,發現26比23大,就回到19
- 再用第1層連接19->22->26,發現比23大,那么就插入到26之前,22之后
上面這張圖就是跳表的初步原理,但一個元素插入鏈表后,應該擁有幾層連接呢?跳表在這塊的實現方式是隨機的,也就是23這個元素插入后,隨機出一個數,比如這個數是3,那么23就會有如下連接:
- 第3層head->23->end
- 第2層19->23->26
- 第1層22->23->26
下面這張圖展示了如何形成一個跳表
 圖片
圖片
在上述跳表中查找/插入23的過程為:
 圖片
圖片
總結一下跳表原理:
- 每個跳表都必須設定一個最大的連接層數MaxLevel
- 第一層連接會連接到表中的每個元素
- 插入一個元素會隨機生成一個連接層數值[1, MaxLevel]之間,根據這個值跳表會給這元素建立N個連接
- 插入某個元素的時候先從最高層開始,當跳到比目標值大的元素后,回退到上一個元素,用該元素的下一層連接進行遍歷,周而復始直到第一層連接,最終在第一層連接中找到合適的位置
使用場景:
- 對有序數據進行排序,例如新聞排行榜或游戲排行榜。
- 對數據進行分組,例如將所有評分在3.0 到4.0 之間的電影分為一組。
- 對數據進行去重,例如將所有重復的單詞從文本中刪除。
本文轉載自微信公眾號「王中陽Go」,作者「王中陽Go」,可以通過以下二維碼關注。

轉載本文請聯系「王中陽Go」公眾號。