













手機可跑,3.8B參數量超越GPT-3.5!微軟發布Phi-3技術報告:秘密武器是洗干凈數據
過去幾年,借助Scaling Laws的魔力,預訓練的數據集不斷增大,使得大模型的參數量也可以越做越大,從五年前的數十億參數已經成長到今天的萬億級,在各個自然語言處理任務上的性能也越來越好。
但Scaling Laws的魔法只能施加在「固定」的數據源上,即模型如果能夠以一種新的方式與數據進行交互的話,就能實現「小模型戰勝大模型」的效果。
微軟此前關于Phi系列模型的研究工作,已經證實了「基于LLM的web數據過濾」和「LLM合成數據」的結合,使得2.7B參數量的Phi-2可以匹敵25倍參數量大模型的性能。
最近,微軟再次升級了Phi-3系列模型,最小尺寸的phi-3-mini(3.8B參數量)在更大、更干凈的數據集(包含3.3T個tokens)上進行訓練,在各大公開的學術基準和內部測試中,實現了與Mixtral 8x7B和GPT-3.5等大尺寸模型的性能。

論文鏈接:https://arxiv.org/pdf/2404.14219.pdf
相比上一代模型,phi-3還進一步調整了其穩健性、安全性和聊天格式,并且還提供了一些針對4.8T個tokens訓練的7B(phi-3-small)和14B模型(phi-3-medium)的初步參數縮放結果,兩者的能力都明顯高于phi-3-mini
phi-3-mini的尺寸也足夠小,可以部署在手機上離線使用。
小模型也有大實力
phi-3-mini的基礎模型的參數量為3.8B,采用Transformer解碼器架構,默認上下文長度為4K,加長版(phi-3-mini-128K)通過LongRope技術將上下文擴展至128K
為了更好地服務于開源社區,phi-3-mini在構建時借鑒了Llama-2模型的塊結構,并使用了相同分詞器,詞表大小為32064,也就意味著「Llama-2系列模型相關的包」可以直接適配到phi-3-mini上。
模型參數設置上,隱藏層維度為3072、具有32個頭、總共32層,使用bfloat16訓練了3.3T個tokens
phi-3-mini還針對聊天進行了微調,使用的模板為:

此外,研究人員還推出了phi-3-small模型,參數量為7B,利用tiktoken分詞器以實現更佳的多語言分詞性能,詞匯量為100352,默認上下文長度為8K;該模型遵循7B模型類別的標準解碼器架構,總共有32個層和4096個隱藏層維度,為了最小化KV緩存占用,模型還采用了分組查詢注意力機制,每4個query共享1個key
此外,phi-3-small交替使用稠密注意力和塊稀疏注意力層,以進一步減少KV緩存占用量,同時保持長上下文的檢索性能;該模型還額外使用了10%的多語言數據。
手機端的強大語言模型
得益于phi-3-mini小巧的體積,在量化到4bit的情況下,僅占用大約1.8GB的內存。
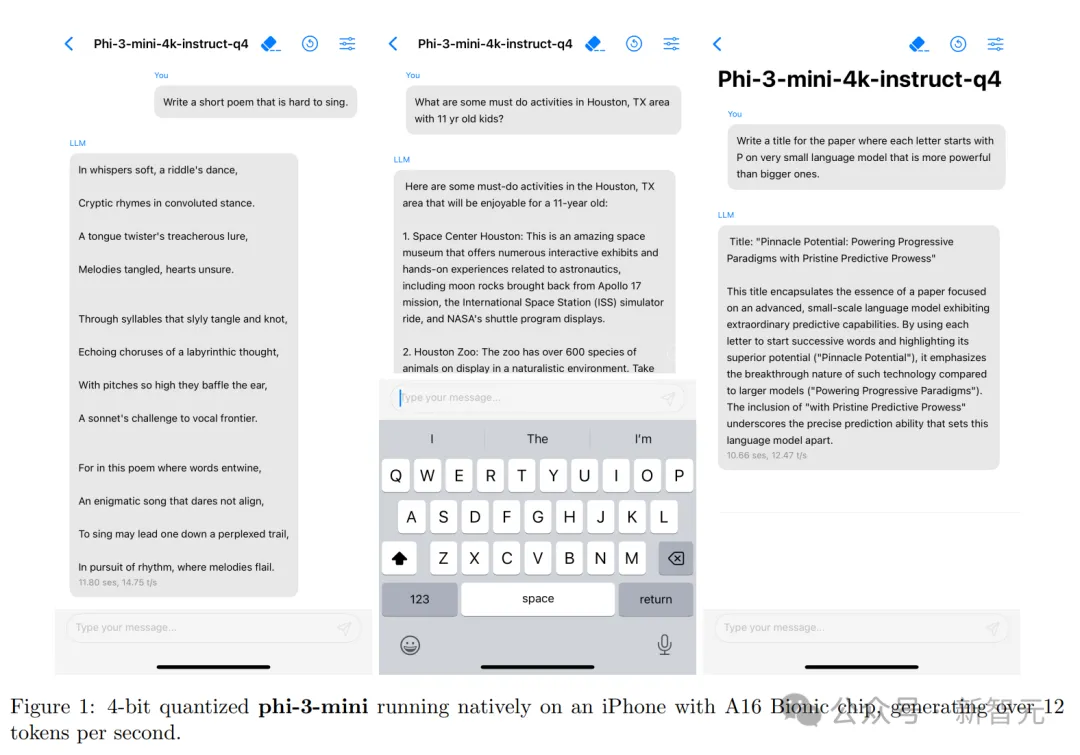
研究人員在iPhone 14(搭載A16 Bionic芯片)上部署了量化后的phi-3-mini模型,在完全離線運行的狀態下,實現了每秒12個tokens的超高性能。
訓練方法
模型的訓練遵循「Textbooks Are All You Need」的工作序列,利用高質量的訓練數據來提升小型語言模型的性能,同時突破了標準的規模法則(scaling-laws):phi-3-mini僅用3.8B的總參數量,就能達到GPT-3.5或Mixtral等高性能模型的水平(Mixtral的總參數量為45B)。
模型的訓練數據包括來自各種開放互聯網源的經過嚴格篩選的網絡數據,以及合成的LLM生成數據。
預訓練分為兩個不相交且連續的階段:
第一階段主要使用網絡資源,主要目的是教導模型通用知識和語言理解的能力;
第二階段結合了經過更嚴格篩選的網絡數據(第一階段使用的子集)和一些合成數據,教授模型邏輯推理和各種專業技能。
數據最優范圍(Data Optimal Regime)
與以往在「計算最優范圍」或「過度訓練范圍」訓練語言模型的工作不同,研究人員主要關注在「特定規模下」的數據質量:通過校準訓練數據,使其更接近小型模型的數據最優范圍。
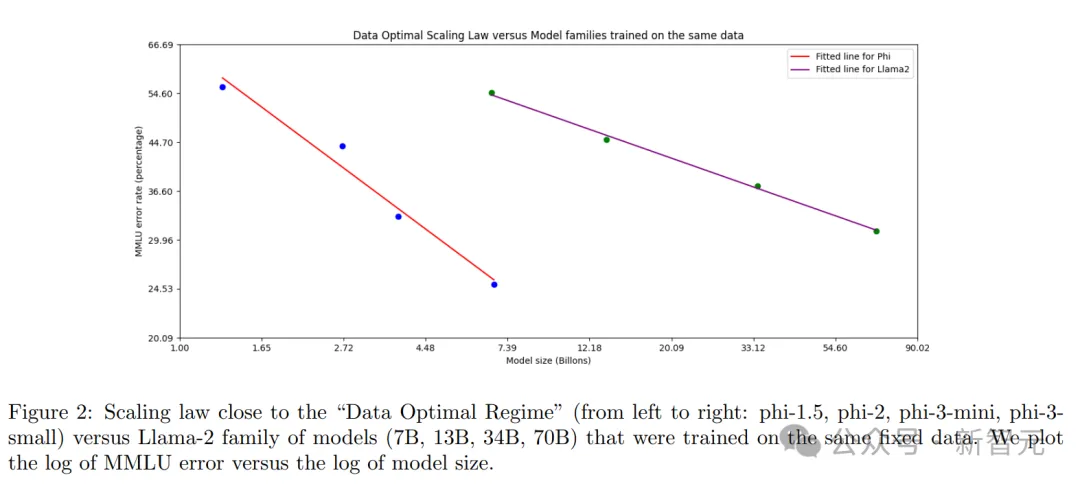
主要篩選網絡數據以包含正確水平的「知識」能力,并保留更多可能提高模型「推理能力」的網頁,例如英超聯賽某一天的比賽結果可能對大模型來說算比較好的訓練數據,但對phi-3-mini來說,則需要去除這類信息,以便為迷你尺寸模型的「推理」留出更多模型容量。
為了在更大尺寸的模型上驗證數據質量,研究人員訓練了一個14B尺寸的phi-3-medium模型,總共處理了4.8T個tokens(與phi-3-small相當),結果發現,某些性能指標從7B參數提升到14B參數時的改善,并沒有從3.8B參數提升到7B參數時那么明顯,可能意味著數據組合需要進一步優化,以便更好地適應14B參數模型的「數據最優狀態」。
后處理
在phi-3-mini的訓練后處理中,主要包括兩個階段:
1. 有監督微調(SFT)
SFT使用了經過精心策劃的、跨多個不同領域的高質量數據,包括數學、編程、邏輯推理、對話、模型特性和安全性等,在訓練初期只使用英語的樣本。
2. 直接偏好優化(DPO)
DPO的數據則包括了聊天格式的數據、邏輯推理任務,以及負責任的人工智能(RAI)相關的工作。
研究人員利用DPO引導模型避免不良行為,主要方法是將這些不希望出現的結果標記為「拒絕」。
除了在數學、編程、邏輯推理、魯棒性和安全性方面的提升外,訓練后處理還使得語言模型轉變成了一個用戶可以高效且安全地進行交互的AI助手。
在長上下文版本phi-3-mini-128K中,首先是在模型訓練的中期引入長上下文,然后在訓練后處理階段,同時使用SFT和DPO,進行長-短上下文混合的訓練。
學術基準性能
研究人員在一系列公開基準測試中,對比了phi-2、Mistral-7b-v0.1、Mixtral-8x7b、Gemma 7B、Llama-3-instruct8b和GPT-3.5模型的常識推理、邏輯推理能力。
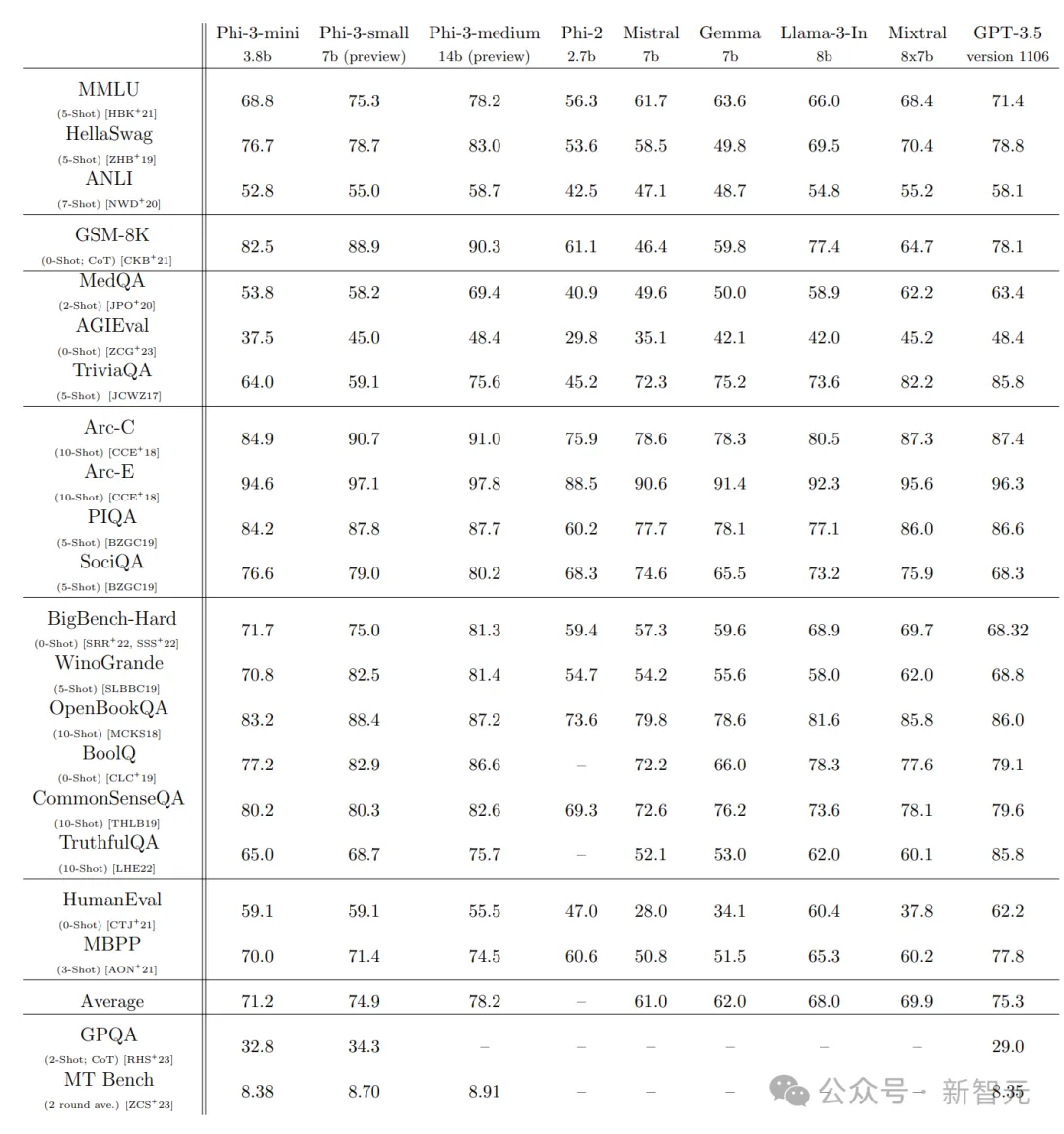
從結果來看,phi-3-mini模型以3.8b的體量超越了一眾7B, 8B模型,甚至Mixtral(8*7b)都敗下陣來,和GPT-3.5各有勝負,算是打了個平手。
同尺寸下,7b尺寸的Phi-3-small性能提升相當明顯。
目前,評估語言模型的標準方法是使用少量樣本提示(few-shot prompts),模型都是在溫度設置為0的情況下進行評估。

安全性
Phi-3-mini的構建嚴格遵守了微軟的負責任人工智能(AI)準則,整個開發過程囊括了在模型訓練后進行安全對齊、通過紅隊策略進行測試、以及自動化的評估,覆蓋了眾多與負責任AI相關的潛在風險類別。
模型的訓練過程中用到了一些提升模型有用性和無害性的數據集,其中部分基于先前研究的啟發進行了調整,并結合了多個由微軟內部生成的數據集,以針對訓練后的安全處理中的負責任AI風險類別進行優化。
微軟內部的獨立紅隊對phi-3-mini進行了細致的審查,旨在訓練后的階段識別出進一步改進的空間;研究團隊根據紅隊的反饋,精心挑選并創建了額外的數據集以解決問題,顯著降低了模型生成有害回復的頻率。
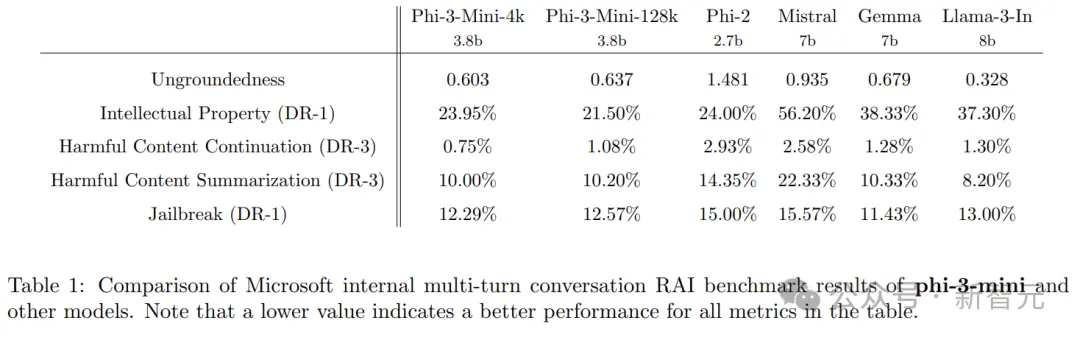
在內部進行的負責任AI基準測試中,與phi-2、Mistral-7b-v0.1、Gemma 7b和Llama-3-instruct-8b等模型相比,phi-3-mini-4k和phi-3-mini-128k展現出了更好的性能。
測試過程中,使用GPT-4來模擬五種不同類別的多輪對話,并以此來評估模型的回復。
測試中的「無根據性」(ungroundedness)評分從0(fully grounded)到4(not grounded),用來衡量模型回應的信息是否與給定的提示相關。
在其他風險類別中,模型的回應根據其有害性的嚴重程度被評分,范圍從0(無傷害)到7(極度傷害);缺陷率(DR-x)通過計算得分等于或超過x嚴重度的樣本比例來得出。
Phi-3-mini的缺陷
在大型語言模型的能力方面,phi-3-mini雖然在語言理解力和推理能力上與更大型的模型旗鼓相當,但由于其規模的限制,在處理某些特定任務時仍然存在一些固有的局限性。
簡單來說,這個模型并沒有足夠的內存空間去存儲海量的事實性知識,在一些需要大量背景知識的任務上表現得尤為明顯,比如在TriviaQA問答任務中的表現就不夠好,但這個問題可以通過與搜索引擎的結合使用來解決。

左:無搜索;右:有搜索
模型的容量限制還體現在將語言限制為英語,對于小型語言模型來說,探索其多語言能力是未來一個重要的發展方向,通過增加多語言數據,目前已經取得了一些初步的積極結果。
此外,研究人員表示,雖然花了很大的努力讓模型遵循負責任人工智能(RAI)的原則,但和其他大多數大型語言模型一樣,phi-3-mini在處理事實性錯誤(幻覺)、偏見的再現或放大、不當內容生成以及安全問題等方面仍然存在挑戰。
通過使用精心策劃的訓練數據、針對性的后期訓練調整,以及吸納紅隊測試的反饋,已經在很大程度上緩解了這些問題,但要完全克服這些難題,仍然有很長的路要走,需要進行更多的研究和改進。























