OmniDrive: 一個關于大模型與3D駕駛任務對齊的框架
作者:Chi Zhang
多模態大語言模型(MLLMs)的進展導致了對基于LLM的自動駕駛的興趣不斷增長,以利用它們強大的推理能力。
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
從一個新穎的3D MLLM架構開始,該架構使用稀疏查詢將視覺表示提升和壓縮到3D,然后將其輸入LLM。
題目:OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception Reasoning and Planning
作者單位:北京理工大學,NVIDIA,華中科技大學
開源地址:GitHub - NVlabs/OmniDrive
多模態大語言模型(MLLMs)的進展導致了對基于LLM的自動駕駛的興趣不斷增長,以利用它們強大的推理能力。然而,利用MLLMs強大的推理能力來改進規劃行為是具有挑戰性的,因為它需要超越2D推理的完整3D情境意識。為了解決這一挑戰,本工作提出了OmniDrive,這是一個關于智能體模型與3D駕駛任務之間強大對齊的全面框架。框架從一個新穎的3D MLLM架構開始,該架構使用稀疏查詢將視覺表示提升和壓縮到3D,然后將其輸入LLM。這種基于查詢的表示允許我們聯合編碼動態對象和靜態地圖元素(例如,交通車道),為3D中的感知-行動對齊提供了一個簡潔的世界模型。進一步提出了一個新的基準,其中包括全面的視覺問答(VQA)任務,包括場景描述、交通規則、3D基礎、反事實推理、決策制定和規劃。廣泛的研究表明,OmniDrive在復雜的3D場景中具有出色的推理和規劃能力。
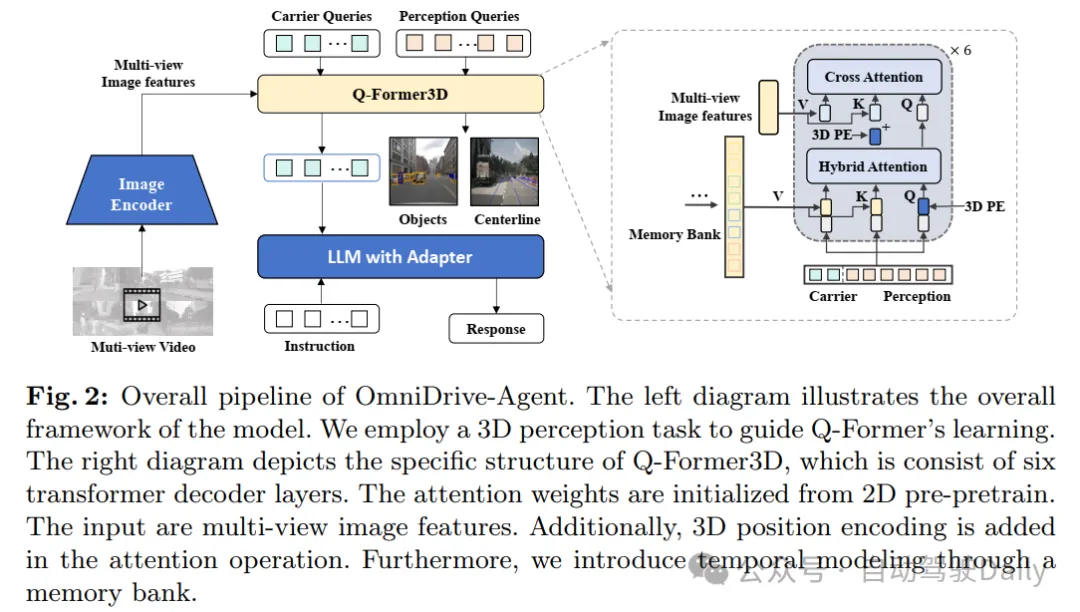
網絡結構

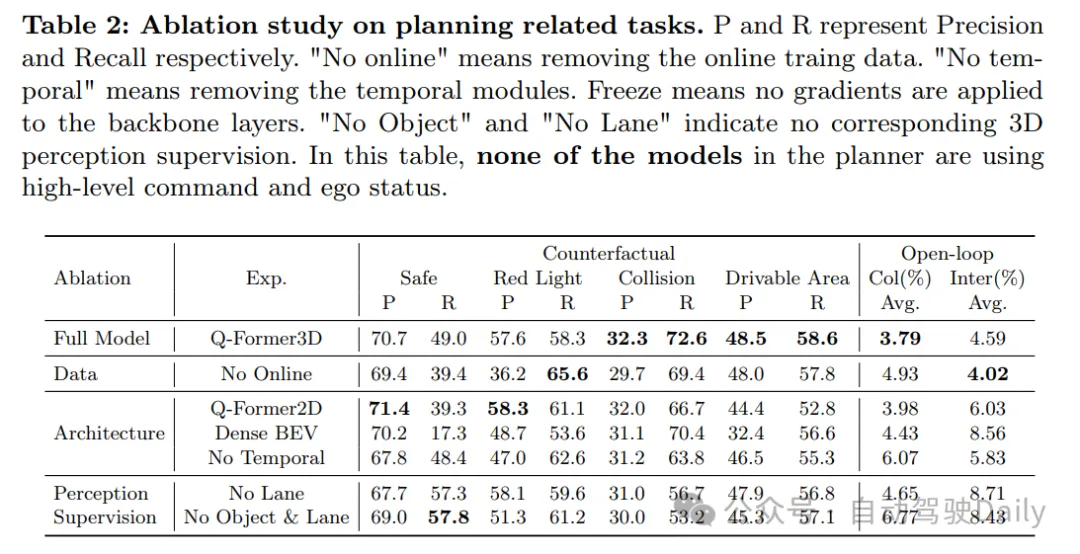
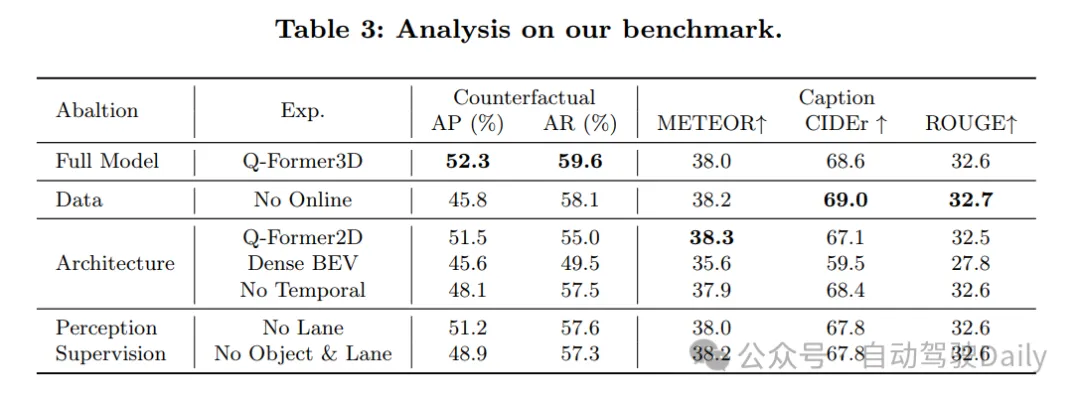
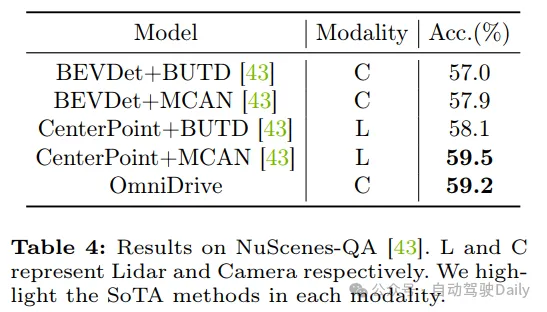
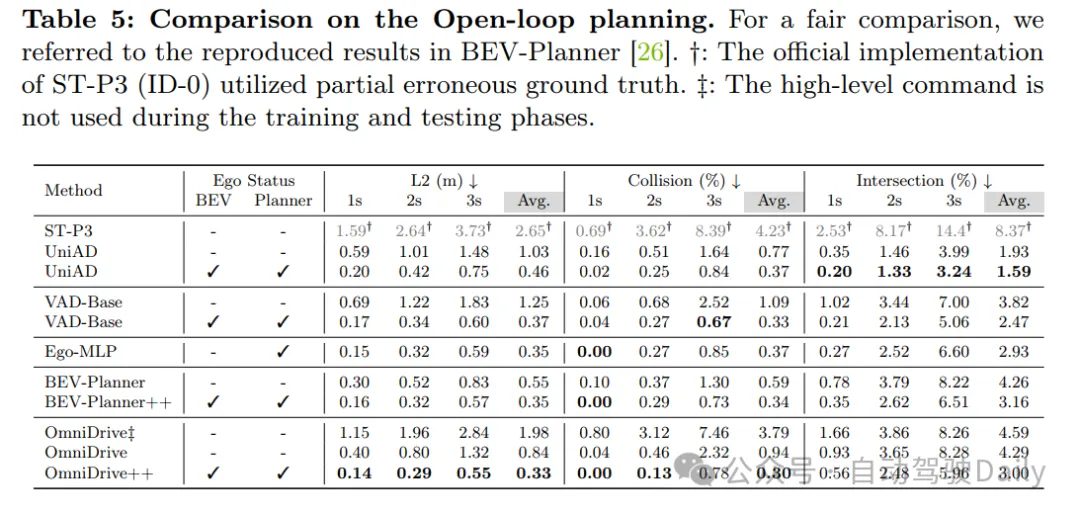
實驗結果

責任編輯:張燕妮
來源:
自動駕駛之心