用MoE橫掃99個子任務!浙大等提出全新通用機器人策略GeRM
多任務機器人學習在應對多樣化和復雜情景方面具有重要意義。然而,當前的方法受到性能問題和收集訓練數據集的困難的限制。
這篇論文提出了GeRM(通用機器人模型),研究人員利用離線強化學習來優化數據利用策略,從演示和次優數據中學習,從而超越了人類演示的局限性。

作者:宋文軒,趙晗,丁鵬翔,崔燦,呂尚可,范亞凝,王東林
單位:西湖大學、浙江大學
論文地址:https://arxiv.org/abs/2403.13358
項目地址:https://songwxuan.github.io/GeRM/
之后采用基于Transformer的視覺-語言-動作模型來處理多模態輸入并輸出動作。
通過引入專家混合結構,GeRM實現了更快的推理速度和更高的整體模型容量,從而解決了強化學習參數量受限的問題,提高了多任務學習中的模型性能,同時控制了計算成本。
通過一系列實驗證明,GeRM在所有任務中均優于其他方法,同時驗證了其在訓練和推理過程中的效率。
此外,研究人員還提供了QUARD-Auto數據集以支持訓練,該數據集的構建遵循文中提出的數據自動化收集的新范式,該方法可以降低收集機器人數據的成本,推動多任務學習社區的進步。
主要貢獻:
1. 首次提出了用于四足強化學習的混合專家模型,其在混合質量的數據上進行訓練,從而具備習得最優策略的潛力。
2. 與現有方法相比,GeRM在只激活自身1/2參數的情況下展現出更高的成功率,激活了涌現能力,同時在訓練過程中展現了更優的數據利用策略。
3.提出了一個全自動機器人數據集收集的范式,并收集了一個大規模開源數據集。
方法
GeRM網絡結構如圖1所示,包含示范數據和失敗數據的視覺-語言輸入,分別經過編碼器和tokenizer后輸入到8層混合專家結構的decoder中,并生成動作token,最終轉化為離散的機器人動作數據并通過底層策略部署到機器人上,此外我們用強化學習的方式進行訓練。
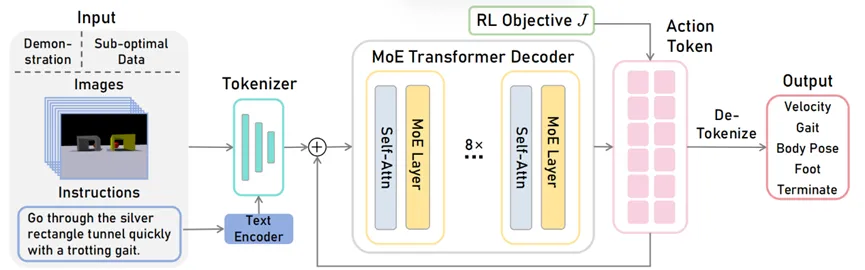
圖1 GeRM網絡結構圖
GeRM Decoder是一個包含 Transformer Decoder架構模型,其中前饋網絡(FFN)從一組 8 個不同的專家網絡中選擇。
在每一層,對于每一個標記,門控網絡選擇兩個專家來處理token,并將它們的輸出加權組合。
不同的專家擅長不同的任務/不同的動作維度,以解決不同場景中的問題,從而學習跨多個任務的通用模型。該架構擴大了網絡參數量,同時保持計算成本基本不變。

圖2 Decoder結構圖
我們提出了一個自動的范式來收集機器人多模態數據。通過這種方式,我們構建了一個大規模的機器人數據集QUARD-Auto,其中包含演示和次優數據的組合。它包括5個任務和99個子任務,總共有257k條軌跡。我們將進行開源以促進機器人社區發展。

表1 數據集介紹
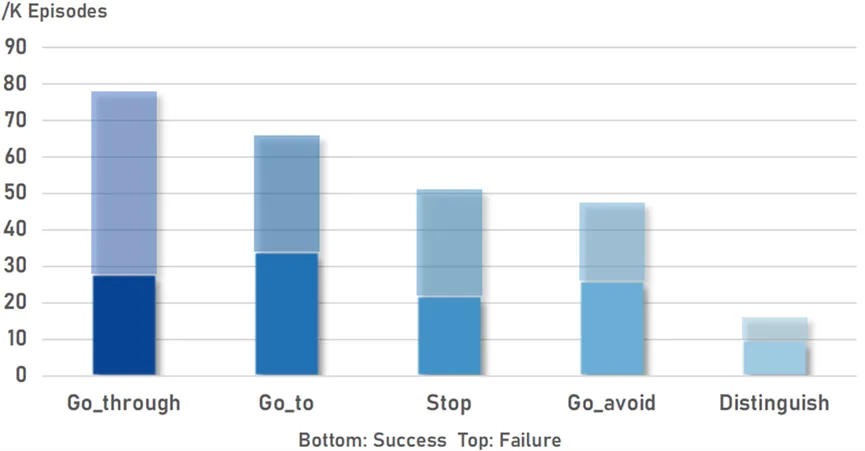
圖3 數據量統計
實驗
我們進行了一系列全面而可靠的實驗,涵蓋了所有 99 個子任務,每個子任務進行了 400 條軌跡的精心測試。
如表1所示,GeRM在所有任務中具有最高的成功率。與 RT-1 和其他GeRM 的變體相比,它有效地從混合質量的數據中學習,優于其他方法,并在多任務中展現出優越的能力。與此同時,MoE 模塊通過在推理時激活部分參數來平衡計算成本和性能。
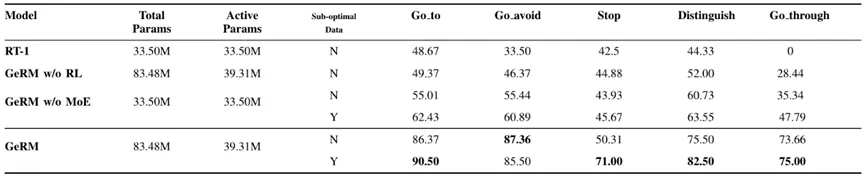
表2 多任務對比實驗
GeRM表現出令人稱贊的訓練效率。與其他方法相比,GeRM 僅需極少的batch就獲得了極低的Loss和較高的成功率,凸顯了GeRM優化數據利用策略的能力。
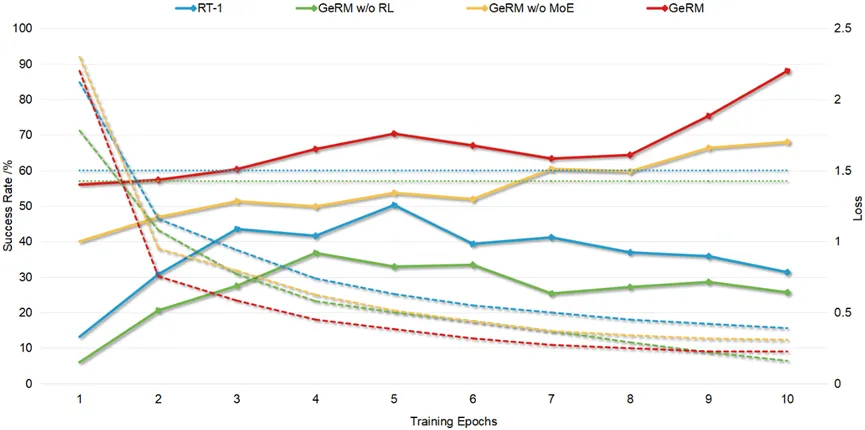
圖4 成功率/Loss變化曲線
GeRM 在動態自適應路徑規劃方面展現出了涌現能力。如視頻所示,四足機器人在初始位置視野受限,難以確定移動方向。為了避開障礙物,它隨機選擇向左轉。
隨后,在遇到錯誤的視覺輸入后,機器人執行了大幅度的重新定向,以與原始視野之外的正確目標對齊。然后,它繼續向目的地駛去,最終完成任務。
值得注意的是,這樣的軌跡不屬于我們的訓練數據集分布之內。這表明 GeRM 在場景背景下的動態自適應路徑規劃方面具有涌現能力,即它能夠根據視覺感知進行決策、規劃未來路徑,并根據需要改變下一步行動。

圖5 涌現能力