3D檢測+BEV分割全SOTA!HENet登場:多視角&多任務(wù)的端到端感知算法
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
寫在前面&筆者的個人理解
在自動駕駛系統(tǒng)中,感知任務(wù)是非常重要的一環(huán),是自動駕駛后續(xù)下游軌跡預(yù)測以及運(yùn)動規(guī)劃任務(wù)的基礎(chǔ)。作為一輛能夠?qū)崿F(xiàn)自動駕駛功能的汽車而言,其通常會配備環(huán)視相機(jī)傳感器、激光雷達(dá)傳感器以及毫米波雷達(dá)傳感器。由于基于純視覺的BEV感知算法需要更低的硬件以及部署成本,同時其輸出的BEV空間感知結(jié)果可以很方便被下游任務(wù)所使用,受到了來自工業(yè)界和學(xué)術(shù)界的廣泛關(guān)注。
隨著目前感知任務(wù)需求的增長,比如要實(shí)現(xiàn)基于BEV空間的3D檢測任務(wù)或者是基于BEV空間的語義分割任務(wù),一個理想的感知算法是可以同時處理像3D檢測或者語義分割等多個任務(wù)的。同時,目前的自動駕駛系統(tǒng)更加傾向于采用完全端到端的感知框架,從而簡化整個系統(tǒng)的架構(gòu)并降低感知算法實(shí)現(xiàn)的復(fù)雜性。
雖然端到端的多任務(wù)感知模型具有諸多的優(yōu)勢,但是目前依舊存在著諸多挑戰(zhàn):
- 目前,絕大多數(shù)基于相機(jī)的3D感知算法,為了提高模型的檢測性能,都會采用更高分辨率的輸入圖像、長時序的輸入信息以及更強(qiáng)大的圖像特征編碼器。但是需要注意的是,在單任務(wù)的感知算法模型上同時采用這些技術(shù)會導(dǎo)致訓(xùn)練過程中巨大的訓(xùn)練成本。
- 由于時序的輸入信息可以更好的提升感知算法模型對于當(dāng)前環(huán)境的理解和感知,目前很多工作都采用了這一策略。這些工作主要將不同幀的信息處理為BEV特征后,直接沿著通道的維度進(jìn)行求和或者拼接來讓模型能夠獲取到一段時間段內(nèi)的環(huán)境元素信息,但收益卻不是特別的理想。造成這一現(xiàn)象的主要原因是自車周圍環(huán)境的運(yùn)動物體在不同時刻沿著BEV的軌跡是不同的,并且分散在BEV的大片區(qū)域中。因此,我們需要引入動態(tài)對齊機(jī)制的思想來對運(yùn)動物體的位置進(jìn)行調(diào)整。
- 對于目前已有的多任務(wù)學(xué)習(xí)框架而言,主要都是采用一個共享的圖像編碼網(wǎng)絡(luò)來處理不同的感知任務(wù)。然而,通過這些論文中列舉的相關(guān)實(shí)驗(yàn)結(jié)果我們發(fā)現(xiàn),通過多任務(wù)聯(lián)合學(xué)習(xí)的方式通常在不同任務(wù)上的表現(xiàn)要弱于每個任務(wù)單獨(dú)訓(xùn)練的性能。
針對上述提到的端到端多任務(wù)感知模型存在的諸多挑戰(zhàn),在本文中,我們提出了一個用于端到端多任務(wù)3D感知的混合特征編碼算法模型HENet,在nuScenes數(shù)據(jù)集上實(shí)現(xiàn)了多個任務(wù)的SOTA,如下圖所示。
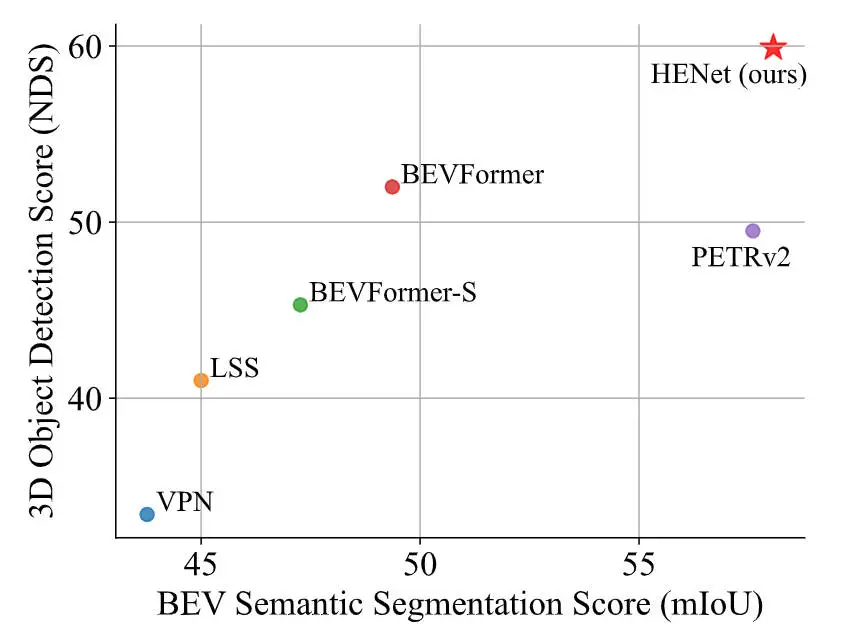
與其他算法模型的語義分割和3D檢測性能指標(biāo)對比
論文鏈接:https://arxiv.org/pdf/2404.02517.pdf;
網(wǎng)絡(luò)模型的整體架構(gòu)&細(xì)節(jié)梳理
在詳細(xì)介紹本文提出的HENet端到端的多任務(wù)感知算法模型之前,下圖展示了我們提出的HENet算法的整體網(wǎng)絡(luò)結(jié)構(gòu)。
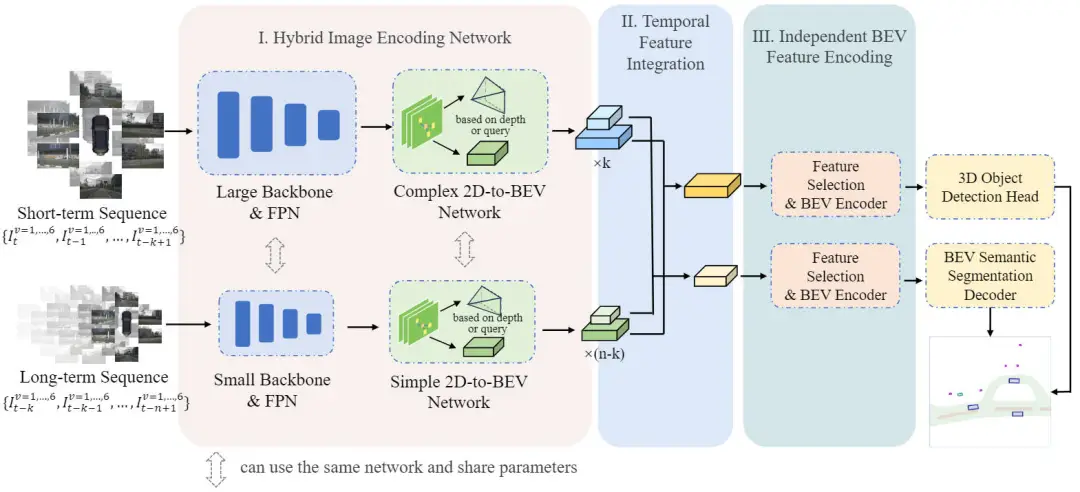
提出的HENet多任務(wù)感知算法模型的整體網(wǎng)絡(luò)結(jié)構(gòu)圖
通過網(wǎng)絡(luò)結(jié)構(gòu)圖可以看出,我們提出的HENet網(wǎng)絡(luò)結(jié)構(gòu)主要包括Hybrid Image Encoding Network(混合圖像編碼網(wǎng)絡(luò))、Temporal Feature Integration(時序特征集成模塊)以及Independent BEV Feature Encoding(獨(dú)立BEV特征編碼模塊)三個子部分。
具體而言,對于給定的時序環(huán)視圖像輸入,首先利用混合圖像編碼網(wǎng)絡(luò)提取其BEV空間特征。然后,利用提出的時序特征集成模塊來聚合多幀的BEV特征信息。最后,將具有不同BEV特征分辨率的BEV特征送入到獨(dú)立BEV特征編碼模塊中實(shí)現(xiàn)進(jìn)一步的特征提取,并送入到解碼器中完成最終的多任務(wù)感知結(jié)果的預(yù)測。
混合圖像編碼網(wǎng)絡(luò)(Hybrid Image Encoding Network)
通過網(wǎng)絡(luò)結(jié)構(gòu)圖可以看出,混合圖像編碼網(wǎng)絡(luò)包含兩種不同復(fù)雜度的圖像編碼器,具體配置方式如下:
- 短時序信息的處理方式:我們首先采用高分辨的輸入圖像以及更加強(qiáng)大的圖像特征提取主干網(wǎng)絡(luò)(VoVNetV2-99)以及FPN特征金字塔組合來處理短時序的輸入信息。然后,對于2D特征向BEV空間的坐標(biāo)映射,我們采用了BEVStereo中的雙目深度估計(jì)網(wǎng)絡(luò)來預(yù)測像素深度信息以及構(gòu)建相機(jī)視錐特征。最后,利用BEVPoolv2的BEV池化模塊來生成最終的多尺度BEV特征。
- 長時序信息的處理方式:我們首先對輸入的環(huán)視圖像進(jìn)行降采樣用于降低輸入圖像的分辨率,并且采用一個小規(guī)模的圖像特征提取主干網(wǎng)絡(luò)(ResNet-50)以及FPN特征金字塔組合來處理長時序的輸入信息。然后,對于2D特征向BEV特征的坐標(biāo)映射,我們采用了BEVDepth中的單目深度估計(jì)網(wǎng)絡(luò)來預(yù)測像素深度信息以及構(gòu)建相機(jī)視錐特征。最后,同樣是利用BEVPoolv2的BEV池化模塊來生成最終的多尺度BEV特征。
但是,根據(jù)我們基于BEV空間的3D檢測以及語義分割對于不同BEV網(wǎng)格分辨率的相關(guān)實(shí)驗(yàn)結(jié)果可以看出,不同的感知任務(wù)對于BEV空間特征的分辨率是不相同的,結(jié)果見下表所示。
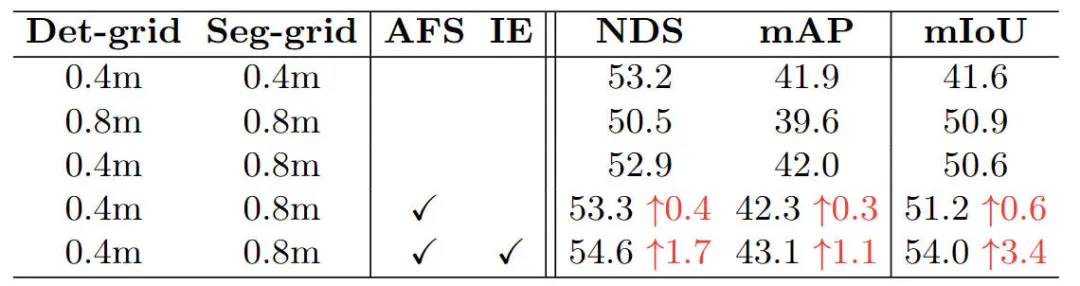
關(guān)于不同BEV分辨率對于3D感知以及語義分割任務(wù)影響的消融實(shí)驗(yàn)
通過上述的實(shí)驗(yàn)結(jié)果可以看出,不同的3D感知任務(wù)(基于BEV空間的3D目標(biāo)檢測及基于BEV空間的語義分割)對于BEV網(wǎng)格的要求并不完全相同。具體來說,對于3D目標(biāo)檢測任務(wù)而言,模型更加關(guān)注定位局部的前景目標(biāo),所以適合采用更小的BEV特征分辨率。但是與之相反,BEV空間的語義分割任務(wù)需要對于大尺度場景的整體理解,包括車道線和道路區(qū)域,所以更適合采用更大一些的BEV特征分辨率。因此,在實(shí)驗(yàn)中我們對于3D檢測任務(wù)采用的BEV特征大小為256×256,對于語義分割任務(wù)采用的BEV特征大小為128×128。
時序特征集成模塊(Temporal Feature Integration)
在利用提出的混合圖像編碼網(wǎng)絡(luò)生成多幀、多尺度的BEV特征之后,我們采用提出的時序特征集成模塊來實(shí)現(xiàn)時序特征的融合,網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示。
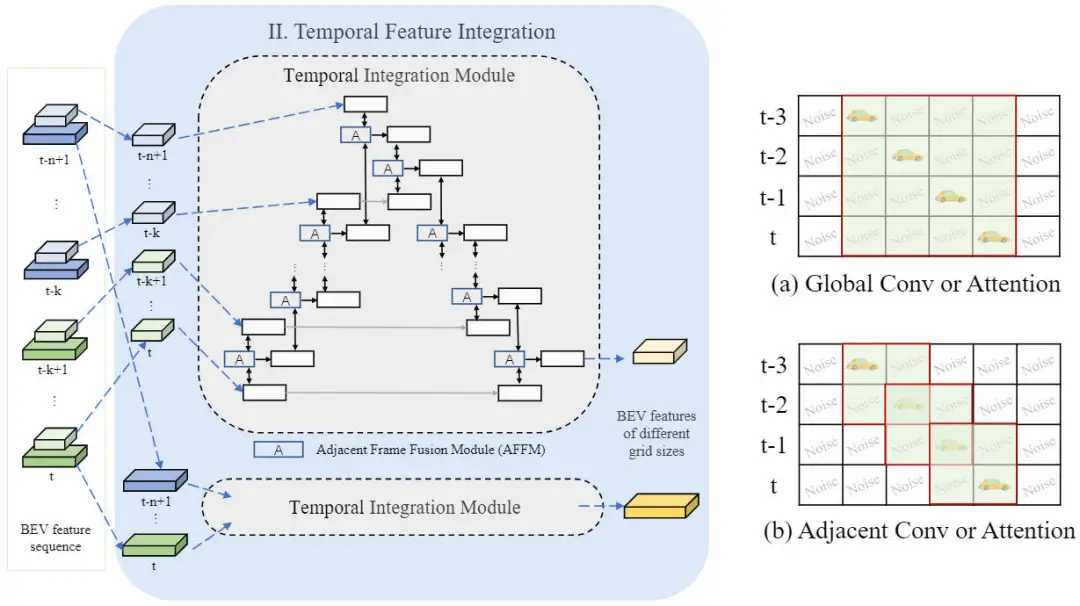
時序特征集成模塊網(wǎng)絡(luò)結(jié)構(gòu)示意圖
具體而言,時序特征集成模塊包括前向和反向兩個特征聚合過程。我們提供了該過程的一個完整的偽代碼來說明其具體的實(shí)現(xiàn)流程。在每個處理的步驟中,我們會采用帶有交叉注意力機(jī)制的相鄰幀融合模塊(AFFM)來融合兩個相鄰幀的BEV特征。

我們將任意兩幀BEV特征分別記作為以及,則相鄰幀融合模塊的實(shí)現(xiàn)細(xì)節(jié)可以用如下的公式進(jìn)行表示:
其中,代表均值操作,是一個可以學(xué)習(xí)的調(diào)節(jié)因子,代表特征圖之間的拼接操作,代表常規(guī)的注意力運(yùn)算。
此外,通過時序特征集成模塊的示意圖可以看出,在使用了相鄰幀注意力機(jī)制的情況下,相比于應(yīng)用全局注意力或者在所有幀上應(yīng)用卷積層而言,會引入更少的噪聲。通過相鄰的注意力機(jī)制,相鄰幀融合模塊可以更準(zhǔn)確的對齊運(yùn)動物體的特征,避免融合冗余背景信息。
獨(dú)立BEV特征編碼模塊(Independent BEV Feature Encoding)
在獲得了時序特征集成模塊輸出的不同分辨率大小的BEV特征之后,我們將不同特征分辨率的BEV特征分別用于不同的感知任務(wù)上。在送入到各個任務(wù)的解碼器之前,我們借鑒了BEVFusion工作中進(jìn)一步處理BEV特征的自適應(yīng)特征選擇以及BEV編碼網(wǎng)絡(luò)。
具體而言,我們設(shè)計(jì)了一個獨(dú)立的BEV特征編碼模塊,整體結(jié)構(gòu)如下圖所示。
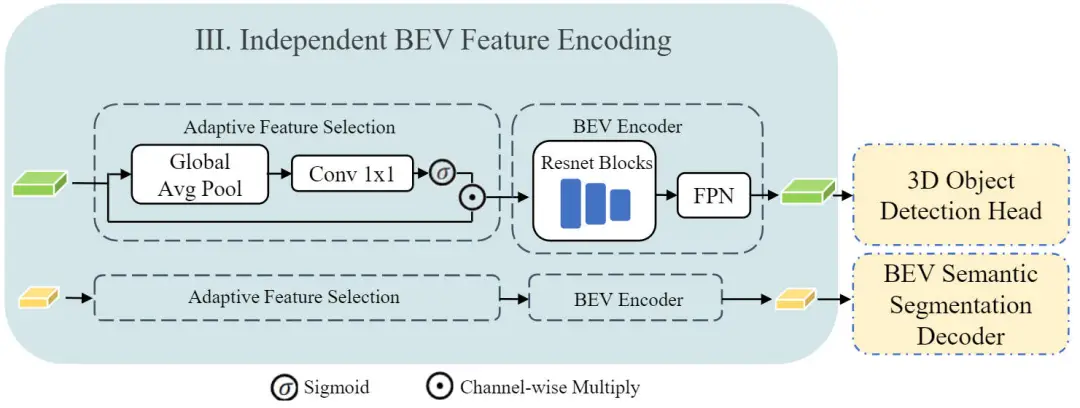
獨(dú)立BEV特征編碼模塊網(wǎng)絡(luò)結(jié)構(gòu)示意圖
通過上圖可以看出,獨(dú)立BEV特征編碼模塊由兩部分構(gòu)成,分別是自適應(yīng)特征選擇以及BEV Encoder兩部分模塊構(gòu)成。其中自適應(yīng)特征選擇模塊采用了一個簡單的通道注意力模塊來選擇重要的特征,這部分可以建模成如下的公式形式:
其中,是BEV特征圖,代表線性的變換矩陣,代表全局平均池化,代表Sigmoid激活函數(shù)。對于圖中的BEV Encoder模塊而言,我們采用了三個殘差連接模塊和一個FPN網(wǎng)絡(luò)來實(shí)現(xiàn)BEV特征的進(jìn)一步特征提取過程。但需要注意的是,對于兩個不同的任務(wù)而言,3D目標(biāo)檢測以及語義分割分支共享了相同的獨(dú)立BEV特征編碼網(wǎng)絡(luò)結(jié)構(gòu),但是其中的參數(shù)并不共享。
實(shí)驗(yàn)結(jié)果&評價(jià)指標(biāo)
定量分析部分
為了驗(yàn)證我們提出的算法模型HENet對于多任務(wù)感知任務(wù)的效果,我們在nuScenes的驗(yàn)證集上與其他的多任務(wù)模型進(jìn)行了對比,實(shí)驗(yàn)結(jié)果見下表所示。
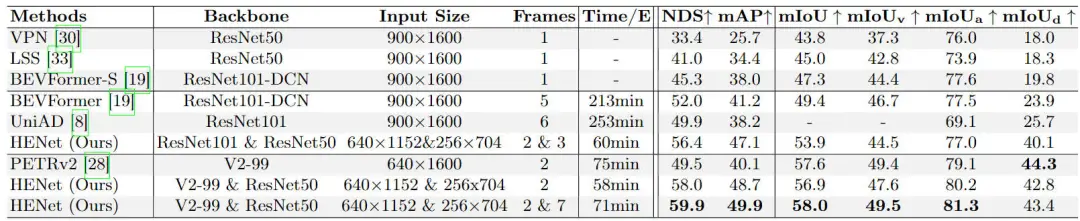
不同多任務(wù)感知算法模型的實(shí)驗(yàn)結(jié)果對比情況
通過實(shí)驗(yàn)結(jié)果可以看出,我們提出的HENet表現(xiàn)出了良好的多任務(wù)感知性能,并實(shí)現(xiàn)了SOTA的性能。具體而言,在3D目標(biāo)檢測任務(wù)上,我們提出的算法模型相比于BEVFormer,在NDS和mAP指標(biāo)上要分別提高7.9%以及8.7%。在BEV空間下的語義分割任務(wù)中,在mIoU指標(biāo)上要高于8.6%。同時,相比于具有很強(qiáng)BEV空間下語義分割能力的PETRv2算法模型而言,我們提出的HENet在3D目標(biāo)檢測任務(wù)中,NDS指標(biāo)要超過10.4%,在mIoU指標(biāo)上童謠具有很強(qiáng)的競爭力。
除了多任務(wù)感知效果的對比之外,我們也進(jìn)行了單任務(wù)的效果對比實(shí)驗(yàn)。首先,我們現(xiàn)在單獨(dú)的3D目標(biāo)檢測任務(wù)上與其它優(yōu)秀的檢測算法模型進(jìn)行了對比,實(shí)驗(yàn)對比結(jié)果如下表所示。
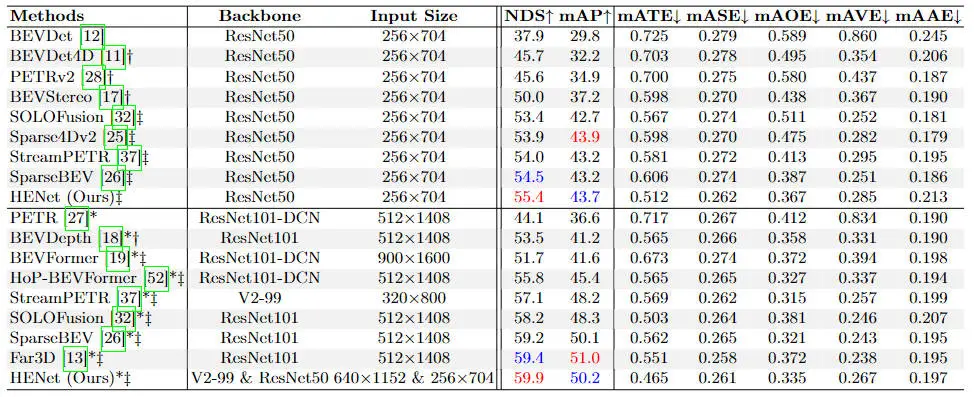
不同3D目標(biāo)檢測算法模型的精度對比情況
通過上表的實(shí)驗(yàn)結(jié)果對比可以看出,我們提出的HENet在單獨(dú)的3D目標(biāo)檢測任務(wù)上,在不同的主干網(wǎng)絡(luò)以及輸入圖像分辨率的情況下,均超過了所有的環(huán)視相機(jī)的3D目標(biāo)檢測算法,進(jìn)一步證明了我們提出的混合圖像編碼網(wǎng)絡(luò)以及時序特征集成模塊的有效性。
此外,我們也在單獨(dú)的BEV空間下的語義分割任務(wù)上進(jìn)行了不同算法模型的對比實(shí)驗(yàn),相關(guān)實(shí)驗(yàn)結(jié)果匯總在下表中。
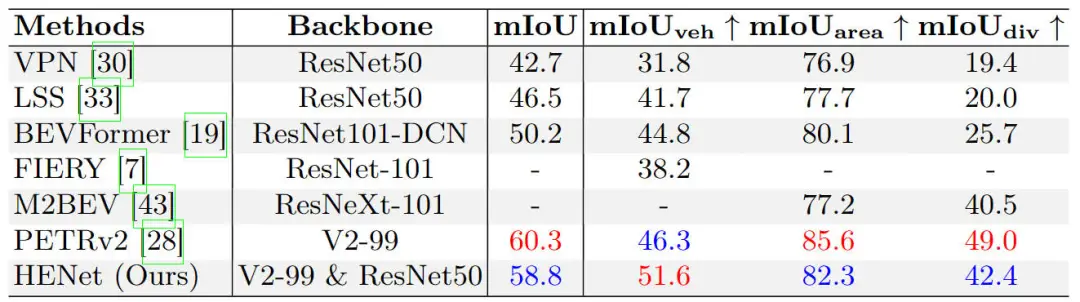
不同BEV語義分割算法模型的精度對比情況
通過上表的實(shí)驗(yàn)結(jié)果可以看出,我們提出的HENet與現(xiàn)有的BEV空間語義分割算法而言,具有更好的性能。
除了不同算法模型精度對比的實(shí)驗(yàn),我們也進(jìn)行了模塊級的消融實(shí)驗(yàn),首先是我們提出的混合圖像編碼網(wǎng)絡(luò)的消融實(shí)驗(yàn)結(jié)果,如下表實(shí)驗(yàn)結(jié)果所示。
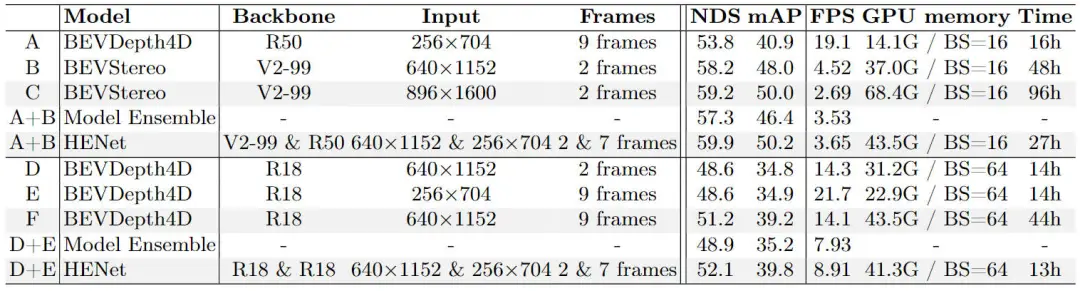
提出的混合圖像編碼網(wǎng)絡(luò)的消融實(shí)驗(yàn)結(jié)果
為了證明提出的混合圖像編碼網(wǎng)絡(luò)的有效性,我們將HENet算法模型與所采用的基線算法模型以及二者的集成模型進(jìn)行了對比。通過采用混合圖像編碼網(wǎng)絡(luò)的方式來集成BEVDepth以及BEVStereo算法可以顯著提升3D目標(biāo)檢測的性能。此外,與輸入更高分辨率的圖像相比,我們提出的混合圖像編碼網(wǎng)絡(luò)可以實(shí)現(xiàn)更快的推理速度和更低的訓(xùn)練成本以實(shí)現(xiàn)更高的檢測精度。與增加時序信息的幀數(shù)相比,混合圖像編碼網(wǎng)絡(luò)可以在較低訓(xùn)練成本下獲得更高的準(zhǔn)確度。
接下來是我們提出的時序特征集成模塊的消融對比實(shí)驗(yàn),相關(guān)的實(shí)驗(yàn)結(jié)果匯總在下面的表格中。

提出的時序特征集成模塊的消融對比實(shí)驗(yàn)結(jié)果
通過上表的實(shí)驗(yàn)結(jié)果可以看出,在采用了相鄰幀注意力的情況下,我們的模型實(shí)現(xiàn)了最佳的檢測結(jié)果。此外,我們還發(fā)現(xiàn),采用了相鄰幀融合的思想要好于采用全局操作的方式,無論是采用注意力機(jī)制還是使用卷積還是拼接等方法。同時,在引入了全局注意力以及更大的BEV Encoder模塊,模型的參數(shù)量進(jìn)一步提高,但是性能卻有所降低。這一現(xiàn)象表明了性能的提升主要來自于模型設(shè)計(jì)本身而不是增加模型的參數(shù)。
定性分析部分
下圖展示了我們提出的HENet算法模型與基線模型的端到端多任務(wù)的預(yù)測結(jié)果可視化。通過可視化的結(jié)果可以證明,我們提出的HENet算法模型通過時序信息的引入更好的解決了物體被遮擋的問題,以及得益于高分辨率的輸入實(shí)現(xiàn)更加準(zhǔn)確的預(yù)測。
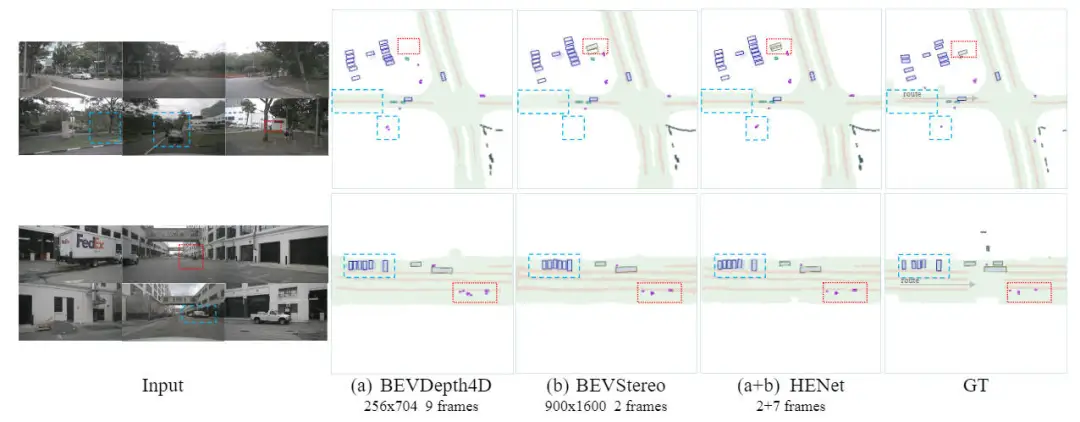
提出的HENet算法模型與基線模型可視化結(jié)果對比
結(jié)論
在本文中,我們提出了一個端到端的多任務(wù)感知算法模型HENet。通過提出的混合圖像編碼網(wǎng)絡(luò)、時序特征集成模塊以及獨(dú)立BEV特征編碼模塊在nuScenes數(shù)據(jù)集上實(shí)現(xiàn)了多任務(wù)感知的SOTA性能。