深入了解Python中的拷貝:淺拷貝與深拷貝的區別

在Python編程中,拷貝數據結構是一項常見的任務,但深拷貝和淺拷貝是兩個不同的概念。了解它們之間的區別對于避免潛在的錯誤至關重要。
本文將深入研究深拷貝和淺拷貝的概念、區別以及如何在接口自動化中使用參數化示例。
1. 深拷貝與淺拷貝的基本概念
什么是淺拷貝?
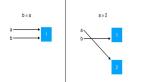
淺拷貝是指創建一個新的數據結構對象,該對象是原始數據結構的副本,但不復制原始數據結構中的嵌套對象的引用。淺拷貝可以通過各種方式完成,如切片、工廠函數或copy模塊的copy方法。
什么是深拷貝?
深拷貝是指創建一個新的數據結構對象,該對象是原始數據結構及其所有嵌套對象的完整副本。深拷貝通常使用copy模塊的deepcopy方法來完成。
2. 區分淺拷貝和深拷貝
淺拷貝和深拷貝的區別在于它們是否復制了原始數據結構中的嵌套對象的引用。讓我們通過示例代碼來演示這一區別。
示例代碼演示
import copy
# 創建一個原始列表
original_list = [1, [2, 3], [4, 5]]
# 淺拷貝
shallow_copy = copy.copy(original_list)
# 修改淺拷貝的元素
shallow_copy[1][0] = 6
# 輸出原始列表和淺拷貝
print("Original List:", original_list)
print("Shallow Copy:", shallow_copy)在上面的示例中,首先創建一個原始列表original_list,其中包含兩個嵌套的子列表。然后,進行淺拷貝,并嘗試修改淺拷貝中的一個嵌套子列表的元素。最后,打印原始列表和淺拷貝的內容。
結果將顯示出淺拷貝只復制了原始數據結構的引用,而不復制嵌套對象的引用。這意味著修改淺拷貝會影響原始數據結構。
3. 深拷貝與淺拷貝在接口自動化中的應用
深拷貝和淺拷貝的概念在接口自動化中也很有用,特別是在參數化測試中。參數化測試是指在多組輸入數據下運行相同的測試用例。在這種情況下,深拷貝和淺拷貝可以用來確保每組測試數據不會相互影響。
參數化測試
通過一個簡單的參數化測試示例來演示深拷貝的應用:
import copy
def test_api_request(request_data):
# 模擬API請求并使用request_data
print("API Request Data:", request_data)
# 參數化測試數據
test_data = [
{"param1": "value1", "param2": "value2"},
{"param1": "value3", "param2": "value4"}
]
for data in test_data:
test_api_request(data)在上述示例中,使用一個包含多個字典的test_data列表來模擬參數化測試數據。如果不使用深拷貝,而是直接迭代test_data,每次測試都會修改request_data字典,從而影響其他測試。這時,使用深拷貝可以解決這個問題:
for data in test_data:
test_api_request(copy.deepcopy(data))通過copy.deepcopy,確保每次測試使用的request_data是完全獨立的,不會相互影響。
總結
在Python編程中,深拷貝和淺拷貝是處理數據拷貝的兩種重要方式,它們之間的區別在于是否復制了嵌套對象的引用。淺拷貝創建一個新的數據結構對象,但嵌套對象的引用保持不變,而深拷貝創建一個原始數據結構及其所有嵌套對象的完整副本。
深拷貝和淺拷貝在接口自動化中具有廣泛的應用,特別是在參數化測試中。參數化測試是在多組輸入數據下運行相同測試用例的場景,而深拷貝可以確保每組測試數據都是獨立的,不會相互影響。這在確保測試的獨立性和可靠性方面至關重要。
深拷貝通常使用Python的copy模塊的deepcopy方法來完成,而淺拷貝可以通過copy模塊的copy方法或其他方式來實現。
深入理解深拷貝和淺拷貝的區別,以及在參數化測試中的應用,有助于編寫更健壯的接口自動化測試代碼,確保測試數據的獨立性和可重復性。