實現百萬級數據從Excel導入到數據庫的方式
高手回答
場景分析
這個案例實際上涉及到多個方面,需要我們系統地分析。讓我們首先看看,從Excel中讀取百萬級數據并將其插入數據庫時可能遇到的問題:
- 內存溢出風險
加載如此龐大的Excel數據可能導致內存溢出,需要注意內存管理。
- 性能瓶頸
處理百萬級數據的讀取和插入操作可能很耗時,性能優化至關重要。
- 異常處理策略
讀取和導入過程中會有各種潛在問題,我們需妥善處理各類異常情況。
內存溢出問題
處理百萬級數據,直接加載到內存中顯然不現實。解決之道在于采用流式讀取,分批處理數據。
在技術選型上,選擇EasyExcel是明智之舉。它專為處理大數據量和復雜Excel文件進行了優化。EasyExcel在解析Excel時,不會將整個文件一次性加載到內存中,而是按行從磁盤逐個讀取數據并解析。
性能問題
針對百萬級數據的處理,單線程顯然效率低下。提升性能的關鍵在于多線程處理。
多線程應用涉及兩個場景:一是多線程讀取文件,另一個是多線程實現數據插入。這涉及到生產者-消費者模式,多線程讀取并多線程插入,以最大程度提升整體性能。
在數據插入方面,除了利用多線程,還應當結合數據庫的批量插入功能以進一步提升速度。
錯誤處理
在文件讀取和數據庫寫入過程中,可能遇到諸多問題,如數據格式錯誤、不一致性和重復數據等。
因此,應分兩步處理。首先進行數據檢查,在插入操作前檢查數據格式等問題,然后在插入過程中處理異常情況。
處理方式多種多樣,可通過事務回滾或記錄日志。一般不推薦直接回滾操作,而是自動重試,若嘗試多次仍無效,則記錄日志,隨后重新插入數據。
此外,在這一過程中,需考慮數據重復問題,可在Excel中設定若干字段為數據庫唯一約束。遇到數據沖突時,可覆蓋、跳過或報錯處理。根據實際業務情況選擇合適的處理方式,一般情況下,跳過并記錄日志是相對合理的選擇。
解決思路
所以,總體方案如下:
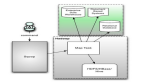
利用EasyExcel進行Excel數據讀取,因其逐行讀取數據而非一次性加載整個文件至內存。為提高并發效率,將百萬級數據分布在不同的工作表中,利用線程池和多線程同時讀取各個工作表。在讀取過程中,借助EasyExcel的ReadListener進行數據處理。
在處理過程中,并非每條數據都直接操作數據庫,以免對數據庫造成過大壓力。設定一個批次大小,例如每1000條數據,將從Excel中讀取的數據臨時存儲在內存中(可使用List實現)。每讀取1000條數據后,執行數據的批量插入操作,可簡單地借助mybatis實現批量插入。
此外,在處理過程中,需要考慮并發問題,因此我們將使用線程安全的隊列來存儲內存中的臨時數據,如ConcurrentLinkedQueue。
經驗證,通過上述方案,讀取并插入100萬條數據的Excel所需時間約為100秒,不超過2分鐘。
具體實現
為了提升并發處理能力,我們將百萬級數據存儲在同一個Excel文件的不同工作表中,然后通過EasyExcel并發地讀取這些工作表數據。
EasyExcel提供了ReadListener接口,允許在每批數據讀取后進行自定義處理。我們可以基于這一功能實現文件的分批讀取。
pom依賴
首先,需要添加以下依賴:
<dependencies>
<!-- EasyExcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>latest_version</version>
</dependency>
<!-- 數據庫連接和線程池 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>并發讀取多個sheet
然后實現并發讀取多個sheet的代碼:
@Service
public class ExcelImporterService {
@Autowired
private MyDataService myDataService;
public void doImport() {
// Excel文件的路徑
String filePath = "users/paidaxing/workspace/excel/test.xlsx";
// 需要讀取的sheet數量
int numberOfSheets = 20;
// 創建一個固定大小的線程池,大小與sheet數量相同
ExecutorService executor = Executors.newFixedThreadPool(numberOfSheets);
// 遍歷所有sheets
for (int sheetNo = 0; sheetNo < numberOfSheets; sheetNo++) {
// 在Java lambda表達式中使用的變量需要是final
int finalSheetNo = sheetNo;
// 向線程池提交一個任務
executor.submit(() -> {
// 使用EasyExcel讀取指定的sheet
EasyExcel.read(filePath, MyDataModel.class, new MyDataModelListener(myDataService))
.sheet(finalSheetNo) // 指定sheet號
.doRead(); // 開始讀取操作
});
}
// 啟動線程池的關閉序列
executor.shutdown();
// 等待所有任務完成,或者在等待超時前被中斷
try {
executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
// 如果等待過程中線程被中斷,打印異常信息
e.printStackTrace();
}
}
}這段代碼通過創建一個固定大小的線程池來并發讀取一個包含多個sheets的Excel文件。每個sheet的讀取作為一個單獨的任務提交給線程池。
我們在代碼中用了一個MyDataModelListener,這個類是ReadListener的一個實現類。當EasyExcel讀取每一行數據時,它會自動調用我們傳入的這個ReadListener實例的invoke方法。在這個方法中,我們就可以定義如何處理這些數據。
MyDataModelListener還包含doAfterAllAnalysed方法,這個方法在所有數據都讀取完畢后被調用。這里可以執行一些清理工作,或處理剩余的數據。
ReadListener
接下來,我們來實現這個我們的ReadListener:
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.List;
// 自定義的ReadListener,用于處理從Excel讀取的數據
public class MyDataModelListener implements ReadListener<MyDataModel> {
// 設置批量處理的數據大小
private static final int BATCH_SIZE = 1000;
// 用于暫存讀取的數據,直到達到批量大小
private List<MyDataModel> batch = new ArrayList<>();
private MyDataService myDataService;
// 構造函數,注入MyBatis的Mapper
public MyDataModelListener(MyDataService myDataService) {
this.myDataService = myDataService;
}
// 每讀取一行數據都會調用此方法
@Override
public void invoke(MyDataModel data, AnalysisContext context) {
//檢查數據的合法性及有效性
if (validateData(data)) {
//有效數據添加到list中
batch.add(data);
} else {
// 處理無效數據,例如記錄日志或跳過
}
// 當達到批量大小時,處理這批數據
if (batch.size() >= BATCH_SIZE) {
processBatch();
}
}
private boolean validateData(MyDataModel data) {
// 調用mapper方法來檢查數據庫中是否已存在該數據
int count = myDataService.countByColumn1(data.getColumn1());
// 如果count為0,表示數據不存在,返回true;否則返回false
if(count == 0){
return true;
}
// 在這里實現數據驗證邏輯
return false;
}
// 所有數據讀取完成后調用此方法
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 如果還有未處理的數據,進行處理
if (!batch.isEmpty()) {
processBatch();
}
}
// 處理一批數據的方法
private void processBatch() {
int retryCount = 0;
// 重試邏輯
while (retryCount < 3) {
try {
// 嘗試批量插入
myDataService.batchInsert(batch);
// 清空批量數據,以便下一次批量處理
batch.clear();
break;
} catch (Exception e) {
// 重試計數增加
retryCount++;
// 如果重試3次都失敗,記錄錯誤日志
if (retryCount >= 3) {
logError(e, batch);
}
}通過自定義MyDataModelListener,在讀取Excel文件過程中可實現數據處理。每讀取一條數據后,將其加入列表,在列表累積達到1000條時,執行一次數據庫批量插入操作。若插入失敗,則進行重試;若多次嘗試仍失敗,則記錄錯誤日志。
批量插入
這里批量插入,用到了MyBatis的批量插入,代碼實現如下:
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface MyDataMapper {
void batchInsert(List<MyDataModel> dataList);
int countByColumn1(String column1);
}mapper.xml文件:
<insert id="batchInsert" parameterType="list">
INSERT INTO paidaxing_test_table_name (column1, column2, ...)
VALUES
<foreach collection="list" item="item" index="index" separator=",">
(#{item.column1}, #{item.column2}, ...)
</foreach>
</insert>
<select id="countByColumn1" resultType="int">
SELECT COUNT(*) FROM your_table WHERE column1 = #{column1}
</select>