













從數據庫思維到數據湖思維的轉變
在數據庫和數據湖的工作中,有幾個關鍵的概念性差異。
在這篇文章中,讓我們來確定其中的一些差異,這些差異在第一眼看到時可能并不直觀,特別是對于具有強大關系型數據庫背景的人來說。
服務器是一次性的。數據在云中。
解耦存儲和計算。在談論數據湖時,這是一個典型的問題。
在傳統的數據庫系統(以及最初的基于Hadoop的數據湖)中,存儲與計算服務器緊密結合。服務器要么有內置的存儲,要么直接連接到存儲。
在現代基于云的數據湖架構中,數據存儲和計算是獨立的。數據被保存在云對象存儲(例如:AWS S3、Azure Storage)中,通常是以一種開放的格式,如parquet,而計算服務器是無狀態的,它們可以在必要時啟動/關閉。
擁有一個解耦的存儲和計算使。
- 降低計算成本。服務器在必要時運行。當不使用時,它們可以被關閉,從而降低了計算成本。
- 可擴展性。你不必為高峰期的使用而購置硬件。服務器/中央處理器/內存的數量可以根據當前的使用情況動態地增加/減少。
- 沙盒化。相同的數據可以被多個計算服務器/集群同時讀取。這使得你可以讓多個團隊在不同的集群中并行工作,讀取相同的數據,而不影響彼此。
RAW數據才是王道!策劃的數據只是衍生的。
在數據庫范式中,來自源系統的數據被轉化并加載到數據庫表中后,它就不再有用了。在數據湖范式中,RAW數據被保留為真理的源泉,最終永遠保留,因為它是真正的資產。
然而,RAW數據通常不適合商業用戶的消費,因此它要經過一個策劃過程,以提高其質量,提供結構并方便消費。經過整理的數據最終被儲存起來,供數據科學團隊、數據倉庫、報告系統以及業務用戶的一般消費使用。

數據湖整理(來源:作者的圖片
典型的數據湖消費者只看到策劃過的數據,因此他們對策劃過的數據的重視程度遠遠超過產生這些數據的RAW數據。
然而,數據湖的真正資產是RAW數據(連同策展管道),從某種意義上說,策展的數據類似于一個可以隨時刷新的物化視圖。
主要收獲:
- 可以在任何時候從RAW中重新創建。
- 可以通過改進策展過程來重新創建。
- 我們可以有多個策劃好的視圖,每個視圖都用于特定的分析。
今天做出的模式決定不會制約未來的需求
通常情況下,信息需求會發生變化,一些原先沒有從源頭/運營系統中收集的信息需要被分析。
在一個典型的情況下,如果原始的RAW數據沒有被存儲,歷史數據就會永遠丟失。
然而,在數據湖架構中,今天決定不把某個字段加載到策劃的模式中,以后可以推翻,因為所有的詳細信息都安全地存儲在數據湖的RAW區域,歷史策劃的數據可以用額外的字段重新創建。
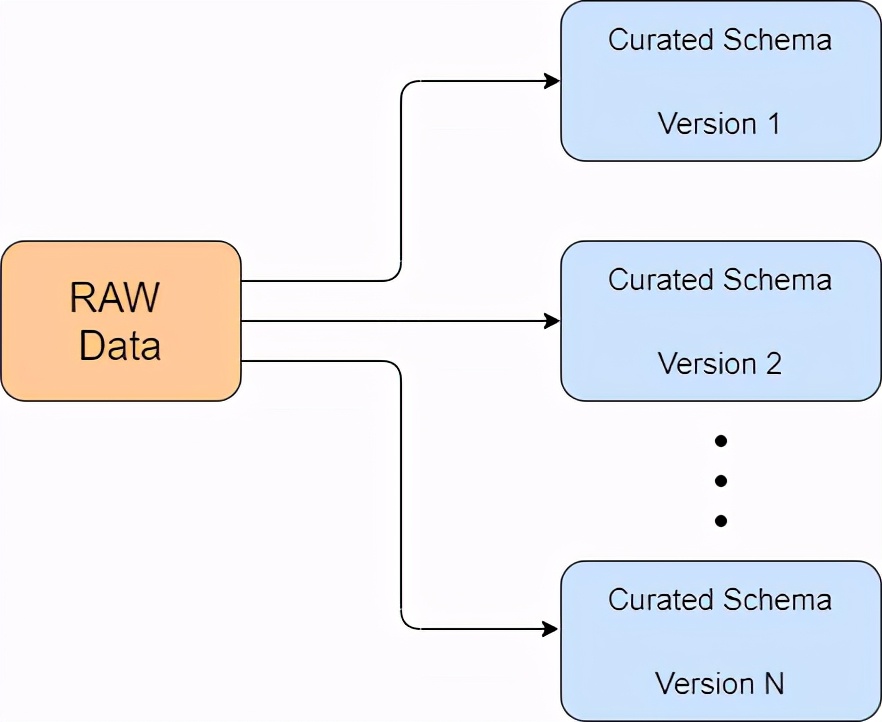
策劃的模式演變(圖片由作者提供
主要收獲:
- 如果你現在不需要,就不要花大量的時間去創建一個通用的一刀切的策劃模式。
- 迭代地創建一個策劃的模式,從添加你現在需要的字段開始。
- 當需要額外的字段時,將它們添加到策展過程中并重新處理。
最后的思考
數據湖不是數據庫的替代品,每種工具都有它的優勢和致命弱點。
將數據湖用于OLTP可能是一個壞主意,就像使用數據庫來存儲數千兆字節的非結構化數據一樣。
我希望這篇文章有助于闡明兩個系統之間的一些關鍵設計差異。


















