比LoRA還快50%的微調(diào)方法來了!一張3090性能超越全參調(diào)優(yōu),UIUC聯(lián)合LMFlow團(tuán)隊提出LISA
2022 年底,隨著 ChatGPT 的爆火,人類正式進(jìn)入了大模型時代。然而,訓(xùn)練大模型需要的時空消耗依然居高不下,給大模型的普及和發(fā)展帶來了巨大困難。面對這一挑戰(zhàn),原先在計算機視覺領(lǐng)域流行的 LoRA 技術(shù)成功轉(zhuǎn)型大模型 [1][2],帶來了接近 2 倍的時間加速和理論最高 8 倍的空間壓縮,將微調(diào)技術(shù)帶進(jìn)千家萬戶。
但 LoRA 技術(shù)仍存在一定的挑戰(zhàn)。一是 LoRA 技術(shù)在很多任務(wù)上還沒有超過正常的全參數(shù)微調(diào) [2][3][4],二是 LoRA 的理論性質(zhì)分析比較困難,給其進(jìn)一步的研究帶來了阻礙。
UIUC 聯(lián)合 LMFlow 團(tuán)隊成員對 LoRA 的實驗性質(zhì)進(jìn)行了分析,意外發(fā)現(xiàn) LoRA 非常側(cè)重 LLM 的底層和頂層的權(quán)重。利用這一特性,LMFlow 團(tuán)隊提出一個極其簡潔的算法:Layerwise Importance Sampled AdamW(LISA)。

- 論文鏈接:https://arxiv.org/abs/2403.17919
- 開源地址:https://github.com/OptimalScale/LMFlow
LISA 介紹
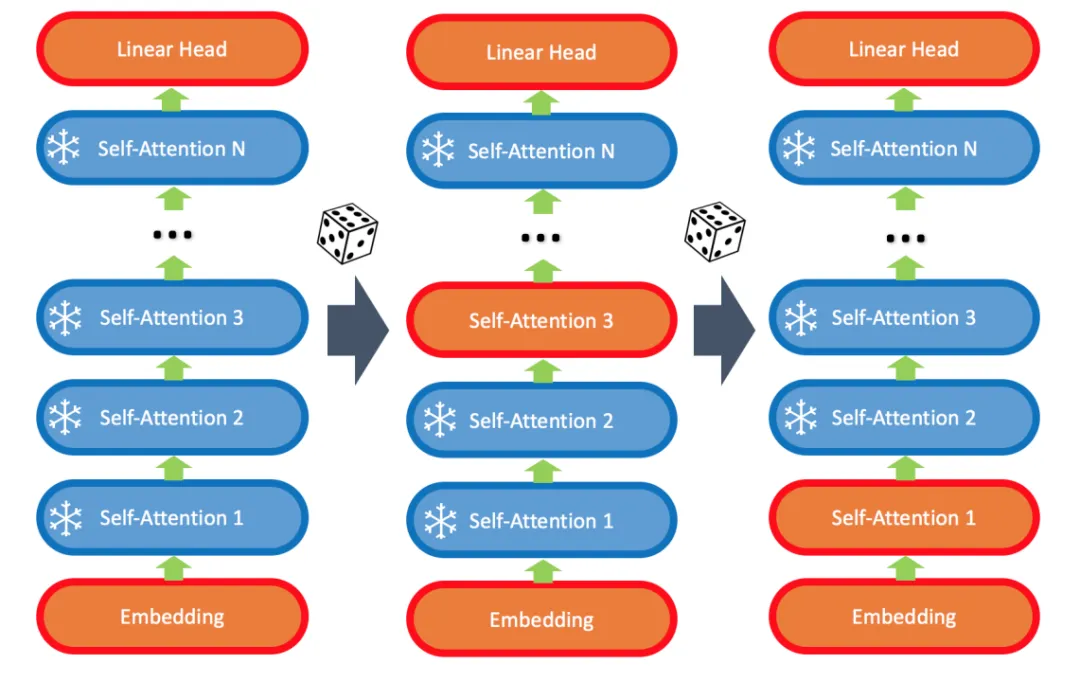
LISA 算法的核心在于:
- 始終更新底層 embedding 和頂層 linear head;
- 隨機更新少數(shù)中間的 self-attention 層,比如 2-4 層。

出乎意料的是,實驗發(fā)現(xiàn)該算法在指令微調(diào)任務(wù)上超過 LoRA 甚至全參數(shù)微調(diào)。


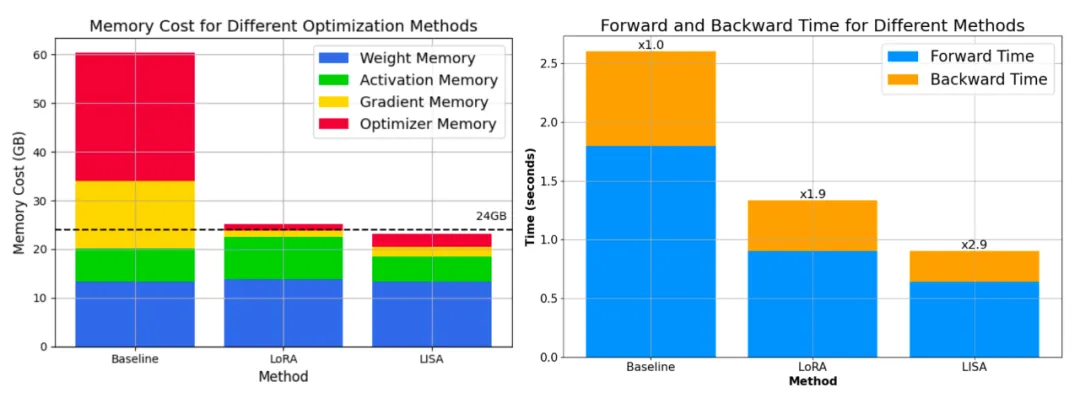
更重要的是,其空間消耗和 LoRA 相當(dāng)甚至更低。70B 的總空間消耗降低到了 80G*4,而 7B 則直接降到了單卡 24G 以下!
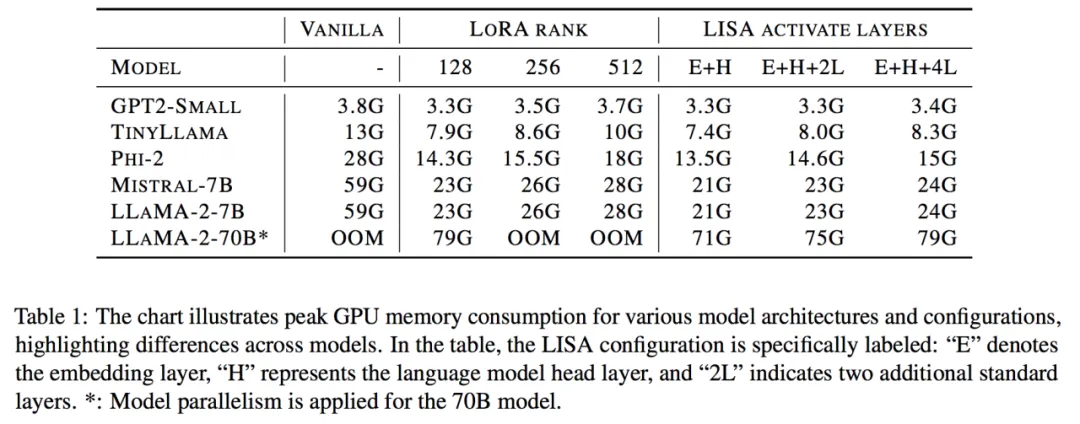
進(jìn)一步的,因為 LISA 每次中間只會激活一小部分參數(shù),算法對更深的網(wǎng)絡(luò),以及梯度檢查點技術(shù)(Gradient Checkpointing)也很友好,能夠帶來更大的空間節(jié)省。
在指令微調(diào)任務(wù)上,LISA 的收斂性質(zhì)比 LoRA 有很大提升,達(dá)到了全參數(shù)調(diào)節(jié)的水平。
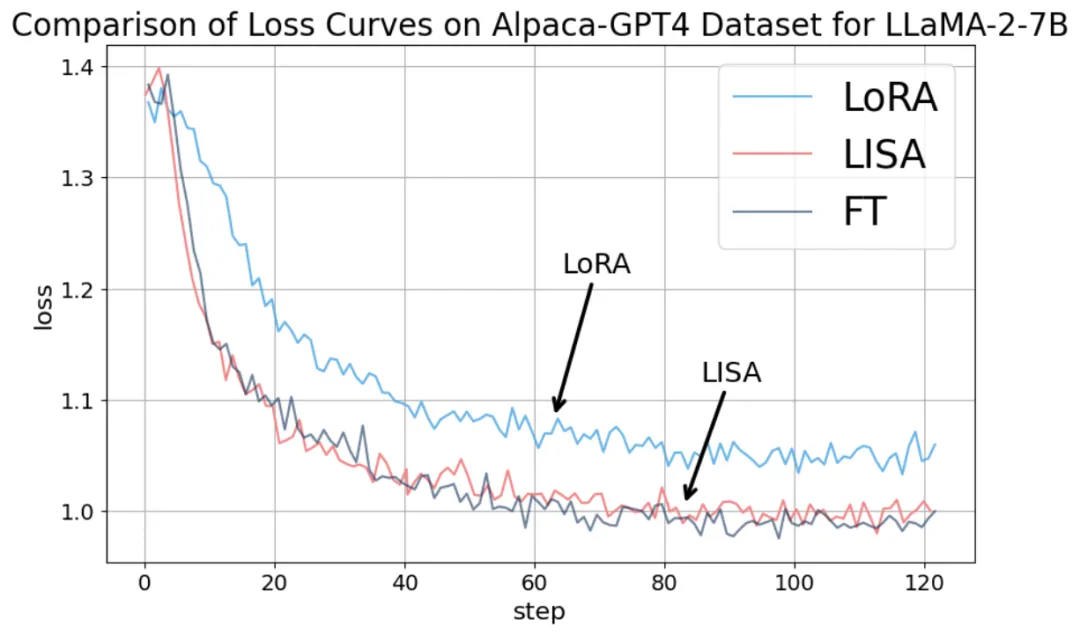
而且,由于不需要像 LoRA 一樣引入額外的 adapter 結(jié)構(gòu),LISA 的計算量小于 LoRA,速度比 LoRA 快將近 50%。
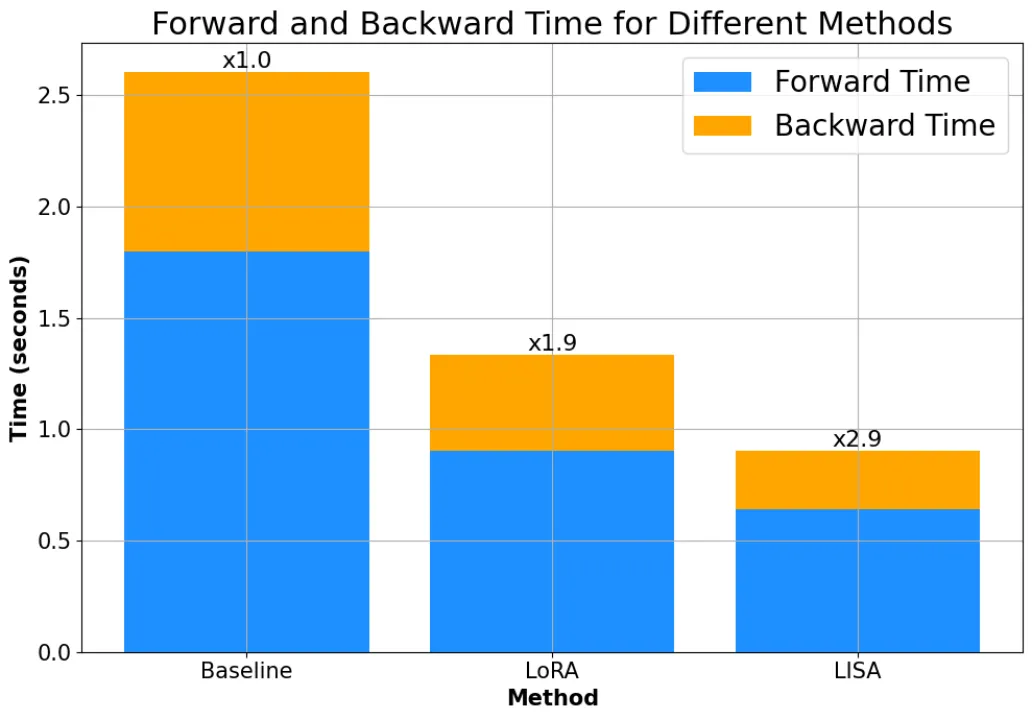
理論性質(zhì)上,LISA 也比 LoRA 更容易分析,Gradient Sparsification、Importance Sampling、Randomized Block-Coordinate Descent 等現(xiàn)有優(yōu)化領(lǐng)域的數(shù)學(xué)工具都可以用于分析 LISA 及其變種的收斂性質(zhì)。
一鍵使用 LISA
為了貢獻(xiàn)大模型開源社區(qū),LMFlow 現(xiàn)已集成 LISA,安裝完成后只需一條指令就可以使用 LISA 進(jìn)行微調(diào):

如果需要進(jìn)一步減少大模型微調(diào)的空間消耗,LMFlow 也已經(jīng)支持一系列最新技術(shù):
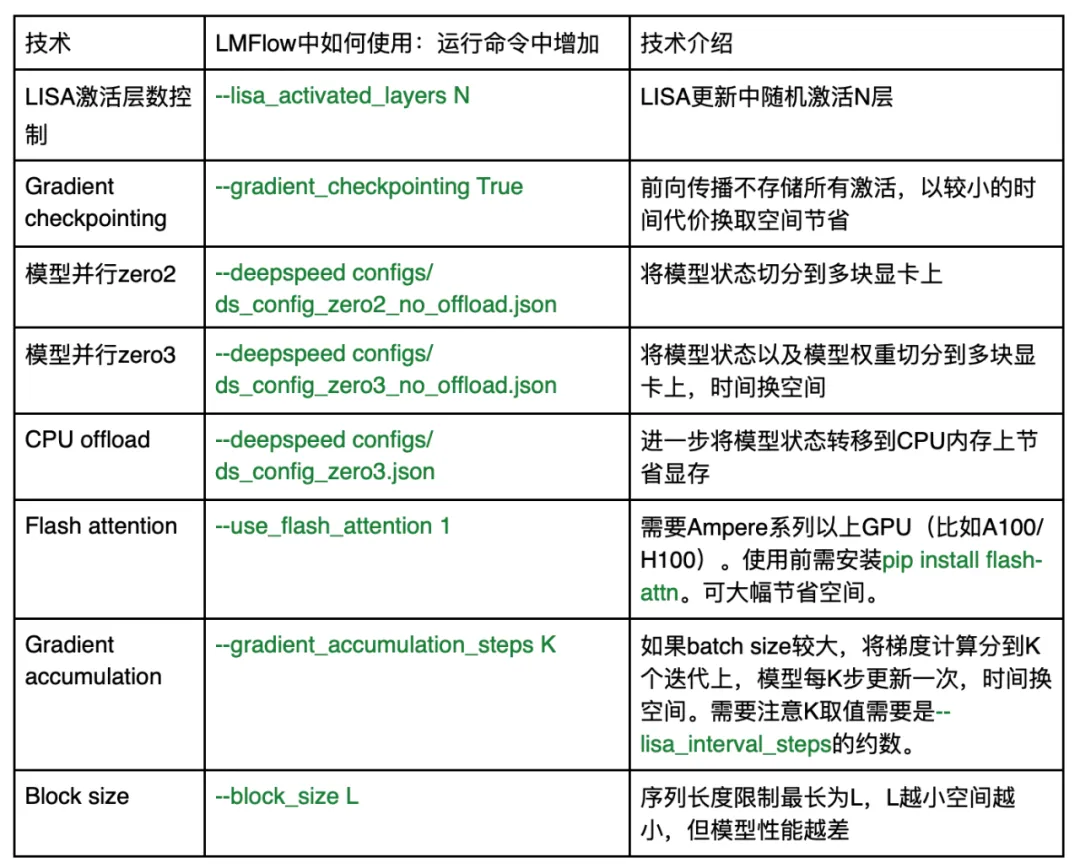
如果在使用過程中遇到任何問題,可通過 github issue 或 github 主頁的微信群聯(lián)系作者團(tuán)隊。LMFlow 將持續(xù)維護(hù)并集成最新技術(shù)。
總結(jié)
在大模型競賽的趨勢下,LMFlow 中的 LISA 為所有人提供了 LoRA 以外的第二個選項,讓大多數(shù)普通玩家可以通過這些技術(shù)參與到這場使用和研究大模型的浪潮中來。正如團(tuán)隊口號所表達(dá)的:讓每個人都能訓(xùn)得起大模型(Large Language Model for All)。