













讓視頻姿態Transformer變得飛速,北大提出高效三維人體姿態估計框架HoT
目前,Video Pose Transformer(VPT)在基于視頻的三維人體姿態估計領域取得了最領先的性能。近年來,這些 VPT 的計算量變得越來越大,這些巨大的計算量同時也限制了這個領域的進一步發展,對那些計算資源不足的研究者十分不友好。例如,訓練一個 243 幀的 VPT 模型通常需要花費好幾天的時間,嚴重拖慢了研究的進度,并成為了該領域亟待解決的一大痛點。
那么,該如何有效地提升 VPT 的效率同時幾乎不損失精度呢?
來自北京大學的團隊提出了一種基于沙漏 Tokenizer 的高效三維人體姿態估計框架HoT,用來解決現有視頻姿態 Transformer(Video Pose Transformer,VPT)高計算需求的問題。該框架可以即插即用無縫地集成到 MHFormer,MixSTE,MotionBERT 等模型中,降低模型近 40% 的計算量而不損失精度,代碼已開源。

- 標題:Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
- 論文地址:https://arxiv.org/abs/2311.12028
- 代碼地址:https://github.com/NationalGAILab/HoT


研究動機
在 VPT 模型中,通常每一幀視頻都被處理成一個獨立的 Pose Token,通過處理長達數百幀的視頻序列(通常是 243 幀乃至 351 幀)來實現卓越的性能表現,并且在 Transformer 的所有層中維持全長的序列表示。然而,由于 VPT 中自注意力機制的計算復雜度與 Token 數量(即視頻幀數)的平方成正比關系,當處理具有較高時序分辨率的視頻輸入時,這些模型不可避免地帶來了巨大的計算開銷,使得它們難以被廣泛部署到計算資源有限的實際應用中。此外,這種對整個序列的處理方式沒有有效考慮到視頻序列內部幀之間的冗余性,尤其是在視覺變化不明顯的連續幀中。這種信息的重復不僅增加了不必要的計算負擔,而且在很大程度上并沒有對模型性能的提升做出實質性的貢獻。
因此,要想實現高效的 VPT,本文認為首先需要考慮兩個因素:
- 時間感受野要大:雖然直接減短輸入序列的長度能夠提升 VPT 的效率,但這樣做會縮小模型的時間感受野,進而限制模型捕獲豐富的時空信息,對性能提升構成制約。因此,在追求高效設計策略時,維持一個較大的時間感受野對于實現精確的估計是至關重要的。
- 視頻冗余得去除:由于相鄰幀之間動作的相似性,視頻中經常包含大量的冗余信息。此外,已有研究指出,在 Transformer 架構中,隨著層的加深,Token 之間的差異性越來越小。因此,可推斷出在 Transformer 的深層使用全長的 Pose Token 會引入不必要的冗余計算,而這些冗余計算對于最終的估計結果的貢獻有限。
基于這兩方面的觀察,作者提出對深層 Transformer 的 Pose Token 進行剪枝,以減少視頻幀的冗余性,同時提高 VPT 的整體效率。然而,這引發了一個新的挑戰:剪枝操作導致了 Token 數量的減少,這時模型不能直接估計出與原視頻序列相匹配數量的三維姿態估計結果。這是因為,在傳統的 VPT 模型中,每個 Token 通常對應視頻中的一幀,剪枝后剩余的序列將不足以覆蓋原視頻的全部幀,這在估計視頻中所有幀的三維人體姿態時成為一個顯著的障礙。因此,為了實現高效的 VPT,還需兼顧另一個重要因素:
- Seq2seq 的推理:一個實際的三維人體姿態估計系統應當能夠通過 seq2seq 的方式進行快速推理,即一次性從輸入的視頻中估計出所有幀的三維人體姿態。因此,為了實現與現有 VPT 框架的無縫集成并實現快速推理,需要保證 Token 序列的完整性,即恢復出與輸入視頻幀數相等的全長 Token。
基于以上三點思考,作者提出了一種基于沙漏結構的高效三維人體姿態估計框架,? Hourglass Tokenizer (HoT)。總的來說,該方法有兩大亮點:
- 簡單的 Baseline、基于 Transformer 通用且高效的框架
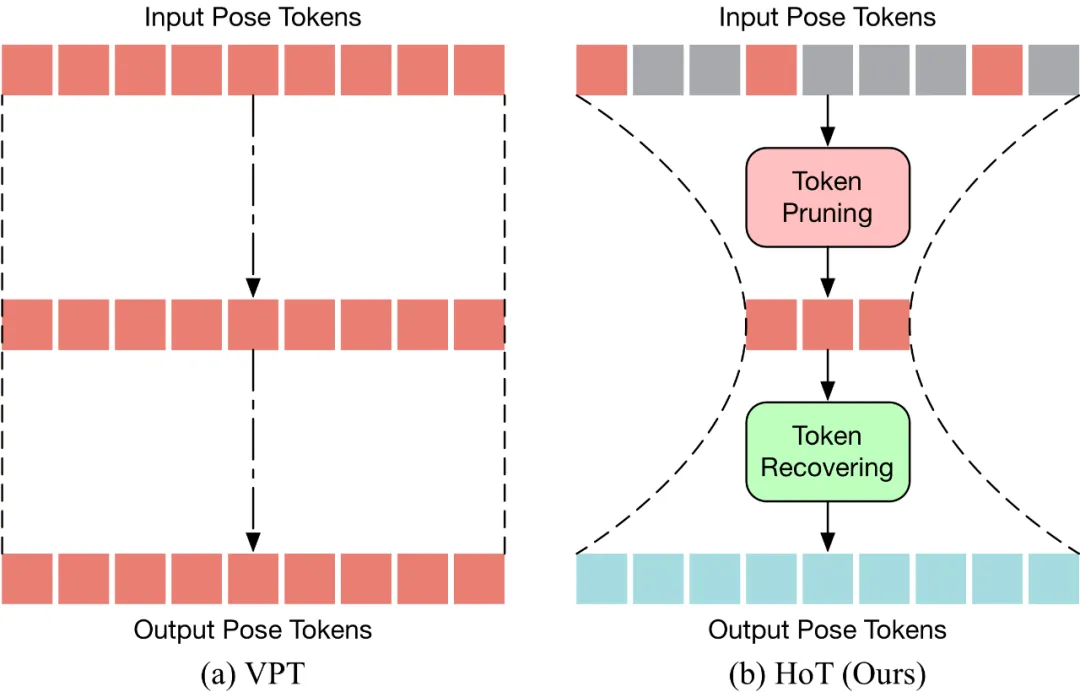
HoT是第一個基于 Transformer 的高效三維人體姿態估計的即插即用框架。如下圖所示,傳統的 VPT 采用了一個 “矩形” 的范式,即在模型的所有層中維持完整長度的 Pose Token,這帶來了高昂的計算成本及特征冗余。與傳統的 VPT 不同,HoT 先剪枝去除冗余的 Token,再恢復整個序列的 Token(看起來像一個 “沙漏”),使得 Transformer 的中間層中僅保留少量的 Token,從而有效地提升了模型的效率。HoT 還展現了極高的通用性,它不僅可以無縫集成到常規的 VPT 模型中,不論是基于 seq2seq 還是 seq2frame 的 VPT,同時也能夠適配各種 Token 剪枝和恢復策略。
- 效率和精度兼得
HoT揭示了維持全長的姿態序列是冗余的,使用少量代表性幀的 Pose Token 就可以同時實現高效率和高性能。與傳統的 VPT 模型相比,HoT 不僅大幅提升了處理效率,還實現了高度競爭性甚至更好的結果。例如,它可以在不犧牲性能的情況下,將 MotionBERT 的 FLOPs 降低近 50%;同時將 MixSTE 的 FLOPs 降低近 40%,而性能僅輕微下降 0.2%。

模型方法
提出的 HoT 整體框架如下圖所示。為了更有效地執行 Token 的剪枝和恢復,本文提出了 Token 剪枝聚類(Token Pruning Cluster,TPC)和 Token 恢復注意力(Token Recovering Attention,TRA)兩個模塊。其中,TPC 模塊動態地選擇少量具有高語義多樣性的代表性 Token,同時減輕視頻幀的冗余。TRA 模塊根據所選的 Token 來恢復詳細的時空信息,從而將網絡輸出擴展到原始的全長時序分辨率,以進行快速推理。
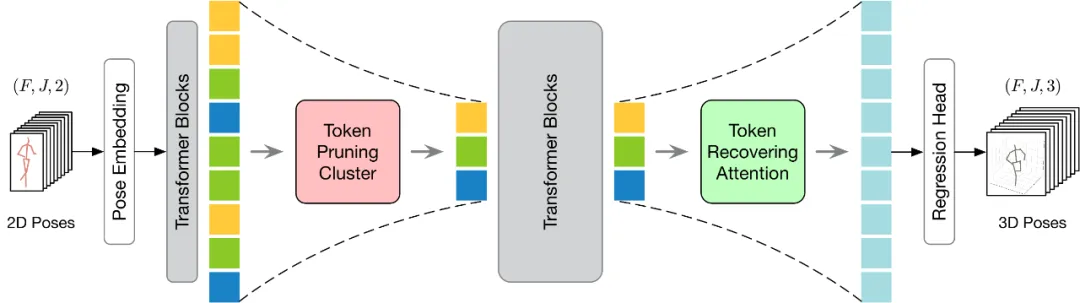
Token 剪枝聚類模塊
本文認為選取出少量且帶有豐富信息的 Pose Token 以進行準確的三維人體姿態估計是一個難點問題。
為了解決該問題,本文認為關鍵在于挑選那些具有高度語義多樣性的代表性 Token,因為這樣的 Token 能夠在降低視頻冗余的同時保留必要的信息。基于這一理念,本文提出了一種簡單、有效且無需額外參數的 Token 剪枝聚類(Token Pruning Cluster,TPC)模塊。該模塊的核心在于鑒別并去除掉那些在語義上貢獻較小的 Token,并聚焦于那些能夠為最終的三維人體姿態估計提供關鍵信息的 Token。通過采用聚類算法,TPC 動態地選擇聚類中心作為代表性 Token,借此利用聚類中心的特性來保留原始數據的豐富語義。
TPC 的結構如下圖所示,它先對輸入的 Pose Token 在空間維度上進行池化處理,隨后利用池化后 Token 的特征相似性對輸入 Token 進行聚類,并選取聚類中心作為代表性 Token。

Token 恢復注意力模塊
TPC 模塊有效地減少了 Pose Token 的數量,然而,剪枝操作引起的時間分辨率下降限制了 VPT 進行 seq2seq 的快速推理。因此,需要對 Token 進行恢復操作。同時,考慮到效率因素,該恢復模塊應當設計得輕量級,以最小化對總體模型計算成本的影響。
為了解決上述挑戰,本文設計了一個輕量級的 Token 恢復注意力(Token Recovering Attention,TRA)模塊,它能夠基于選定的 Token 恢復詳細的時空信息。通過這種方式,由剪枝操作引起的低時間分辨率得到了有效擴展,達到了原始完整序列的時間分辨率,使得網絡能夠一次性估計出所有幀的三維人體姿態序列,從而實現 seq2seq 的快速推理。
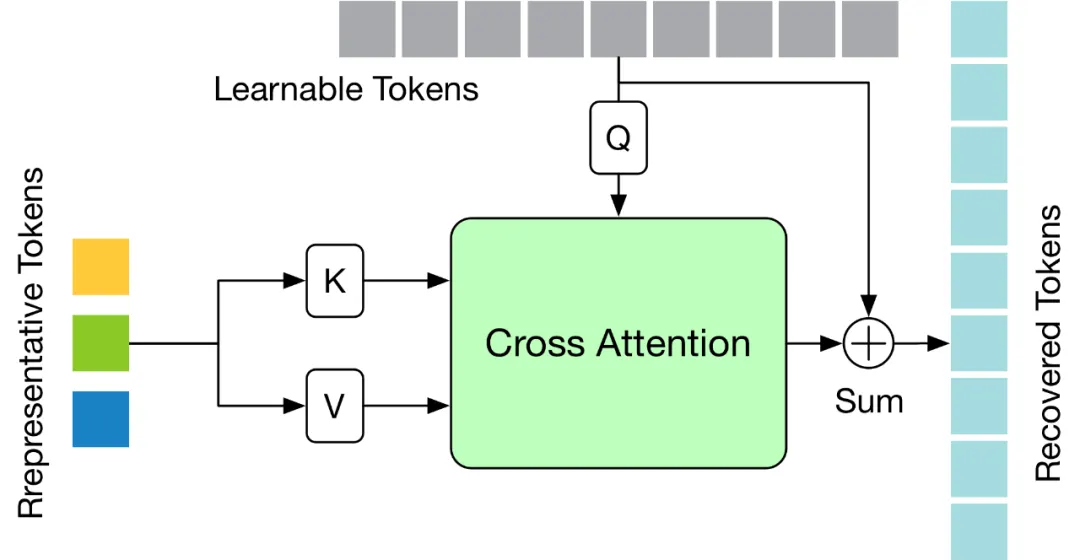
TRA 模塊的結構如下圖所示,其利用最后一層 Transformer 中的代表性 Token 和初始化為零的可學習 Token,通過一個簡單的交叉注意力機制來恢復完整的 Token 序列。
應用到現有的 VPT
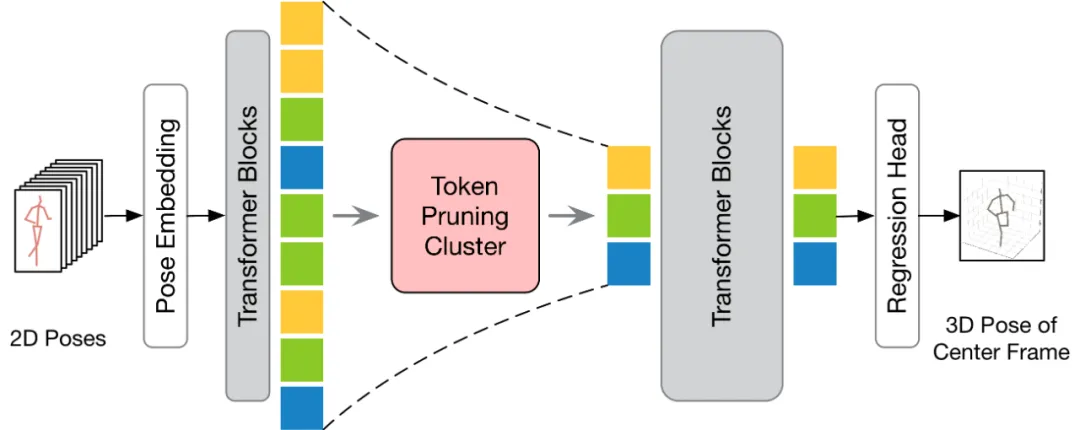
在討論如何將所提出的方法應用到現有的 VPT 之前,本文首先對現有的 VPT 架構進行了總結。如下圖所示,VPT 架構主要由三個組成部分構成:一個姿態嵌入模塊用于編碼姿態序列的空間與時間信息,多層 Transformer 用于學習全局時空表征,以及一個回歸頭模塊用于回歸輸出三維人體姿態結果。
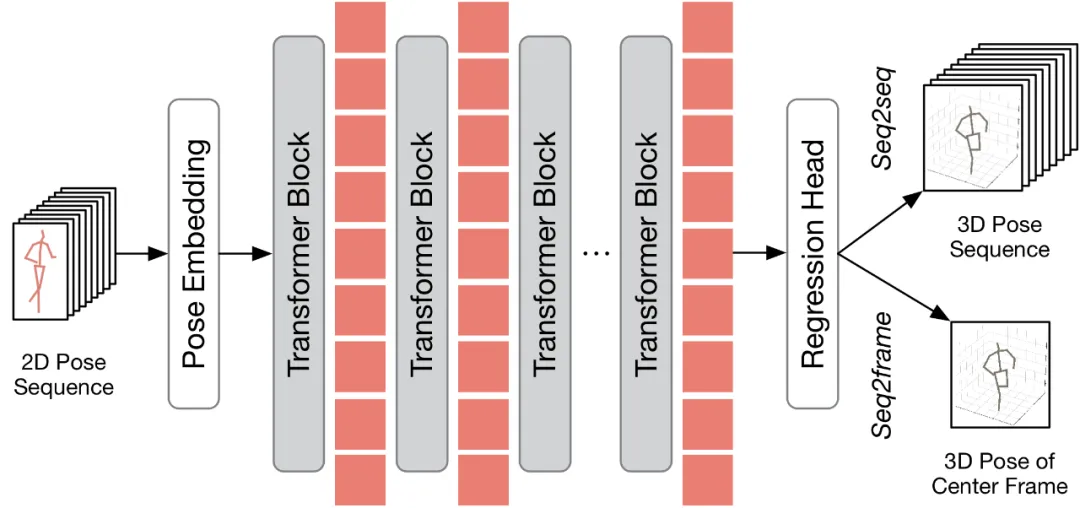
根據輸出的幀數不同,現有的 VPT 可分為兩種推理流程:seq2frame 和 seq2seq。在 seq2seq 流程中,輸出是輸入視頻的所有幀,因此需要恢復原始的全長時序分辨率。如 HoT 框架圖所示的,TPC 和 TRA 兩個模塊都被嵌入到 VPT 中。在 seq2frame 流程中,輸出是視頻中心幀的三維姿態。因此,在該流程下,TRA 模塊是不必要的,只需在 VPT 中集成 TPC 模塊即可。其框架如下圖所示。
實驗結果
消融實驗
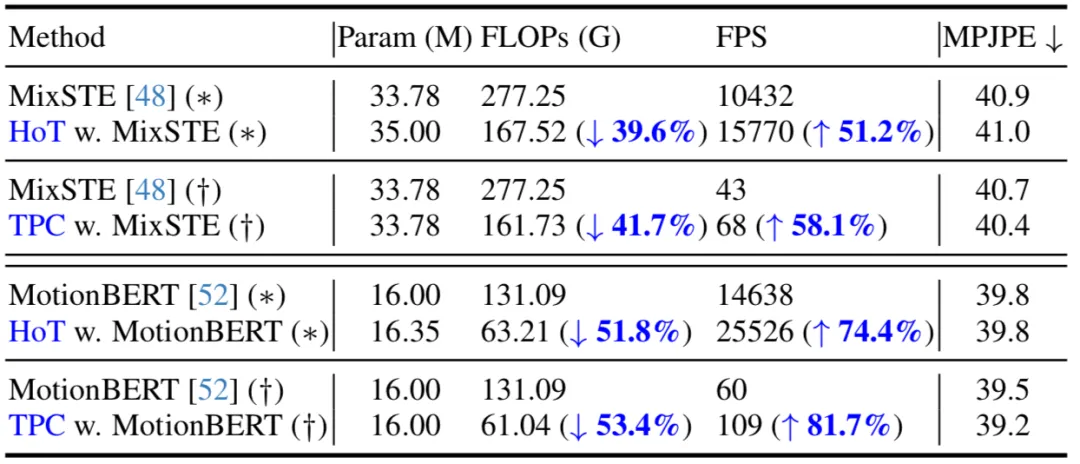
在下表,本文給出了在 seq2seq(*)和 seq2frame(?)推理流程下的對比。結果表明,通過在現有 VPT 上應用所提出的方法,本方法能夠在保持模型參數量幾乎不變的同時,顯著減少 FLOPs,并且大幅提高了 FPS。此外,相比原始模型,所提出的方法在性能上基本持平或者能取得更好的性能。
本文還對比了不同的 Token 剪枝策略,包括注意力分數剪枝,均勻采樣,以及選擇前 k 個具有較大運動量 Token 的運動剪枝策略,可見所提出的 TPC 取得了最好的性能。

本文還對比了不同的 Token 恢復策略,包括最近鄰插值和線性插值,可見所提出的 TRA 取得了最好的性能。

與 SOTA 方法的對比
當前,在 Human3.6M 數據集上,三維人體姿態估計的領先方法均采用了基于 Transformer 的架構。為了驗證本方法的有效性,作者將其應用于三個最新的 VPT 模型:MHForme,MixSTE 和 MotionBERT,并與它們在參數量、FLOPs 和 MPJPE 上進行了比較。
如下表所示,本方法在保持原有精度的前提下,顯著降低了 SOTA VPT 模型的計算量。這些結果不僅驗證了本方法的有效性和高效率,還揭示了現有 VPT 模型中存在著計算冗余,并且這些冗余對最終的估計性能貢獻甚小,甚至可能導致性能下降。此外,本方法可以剔除掉這些不必要的計算量,同時達到了高度競爭力甚至更優的性能。

代碼運行
作者還給出了 demo 運行(https://github.com/NationalGAILab/HoT),集成了 YOLOv3 人體檢測器、HRNet 二維姿態檢測器、HoT w. MixSTE 二維到三維姿態提升器。只需下載作者提供的預訓練模型,輸入一小段含有人的視頻,便可一行代碼直接輸出三維人體姿態估計的 demo。
python demo/vis.py --video sample_video.mp4運行樣例視頻得到的結果:

小結
本文針對現有 Video Pose Transforme(VPT)計算成本高的問題,提出了沙漏 Tokenizer(Hourglass Tokenizer,HoT),這是一種即插即用的 Token 剪枝和恢復框架,用于從視頻中高效地進行基于 Transformer 的 3D 人體姿勢估計。研究發現,在 VPT 中維持全長姿態序列是不必要的,使用少量代表性幀的 Pose Token 即可同時實現高精度和高效率。大量實驗驗證了本方法的高度兼容性和廣泛適用性。它可以輕松集成至各種常見的 VPT 模型中,不論是基于 seq2seq 還是 seq2frame 的 VPT,并且能夠有效地適應多種 Token 剪枝與恢復策略,展示出其巨大潛力。作者期望 HoT 能夠推動開發更強、更快的 VPT。
























