精準高效估計多人3D姿態,美圖北航分布感知式單階段模型入選CVPR
近日,計算機視覺頂會 CVPR 2022 公布了會議錄取結果,美圖影像研究院(MT Lab)與北京航空航天大學可樂實驗室(CoLab)聯合發表的論文被接收。該論文突破性地提出分布感知式單階段模型,用于解決極具挑戰性的多人 3D 人體姿態估計問題。該方法通過一次網絡前向推理同時獲取 3D 空間中人體位置信息以及相對應的關鍵點信息,從而簡化了預測流程,提高了效率。此外,該方法有效地學習了人體關鍵點的真實分布,進而提升了基于回歸框架的精度。
多人 3D 人體姿態估計是當前的一個熱點研究課題,也具有廣泛的應用潛力。在計算機視覺中,基于單張 RGB 圖片的多人 3D 人體姿態估計問題通常通過自頂向下或是自底向上的兩階段方法來解決,然而兩階段的方法需忍受大量的冗余計算以及復雜的后處理,其低效率深受詬病。此外,已有方法缺少對人體姿態數據分布的認知,從而無法準確地求解從 2D 圖片到 3D 位置這一病態問題,以上兩點限制了已有方法在實際場景中的應用。
美圖影像研究院(MT Lab)與北京航空航天大學可樂實驗室(CoLab)在 CVPR 2022 發表的論文,提出一種分布感知式單階段模型,并利用這一模型從單張 RGB 圖片中估計多個人在 3D 相機空間中的人體姿態。
該方法將 3D 人體姿態表示為 2.5D 人體中心點和 3D 關鍵點偏移量,以適配圖片空間的深度估計,同時這一表示將人體位置信息和對應的關鍵點信息進行了統一,從而使得單階段多人 3D 姿態估計成為可能。

論文地址:https://arxiv.org/abs/2203.07697
此外,該方法在模型優化過程中對人體關鍵點的分布進行了學習,這為關鍵點位置的回歸預測提供了重要的指導信息,進而提升了基于回歸框架的精度。這一分布學習模塊可以與姿態估計模塊在訓練過程中通過最大似然估計一起學習,在測試過程中該模塊被移除,不會帶來模型推理計算量的增加。為了降低人體關鍵點分布學習的難度,該方法創新性地提出了一種迭代更新的策略以逐漸逼近目標分布。
該模型以全卷積的方式來實現,可以進行端到端的訓練和測試。通過這樣一種方式,該算法可以有效且精準地解決多人 3D 人體姿態估計問題,在取得和兩階段方法接近的精度的同時,也大大提升了速度。
背景
多人 3D 人體姿態估計是計算機視覺中的經典問題,它被廣泛應用于 AR/VR、游戲、運動分析、虛擬試衣等。近年來隨著元宇宙概念的興起,更是讓這一技術備受關注。目前,通常采用兩階段方法來解決該問題:自頂向下方法,即先檢測圖片多個人體的位置,之后對檢測到的每個人使用單人 3D 姿態估計模型來分別預測其姿態;自底向上方法,即先檢測圖片中所有人的 3D 關鍵點,之后通過相關性將這些關鍵點分配給對應的人體。
盡管兩階段方法取得了良好的精度,但是需要通過冗余的計算和復雜的后處理來順序性地獲取人體位置信息和關鍵點位置信息,這使得速率通常難以滿足實際場景的部署需求,因此多人 3D 姿態估計算法流程亟需簡化。
另一方面,在缺少數據分布先驗知識的情況下,從單張 RGB 圖片中估計 3D 關鍵點位置,特別是深度信息,是一個病態問題。這使得傳統的應用于 2D 場景的單階段模型無法直接向 3D 場景進行擴展,因此學習并獲取 3D 關鍵點的數據分布是進行高精度多人 3D 人體姿態估計的關鍵所在。
為了克服以上問題,該論文提出了一種分布感知式單階段模型(Distribution-Aware Single-stage model, DAS)用于解決基于單張圖片的多人 3D 人體姿態估計這一病態問題。DAS 模型將 3D 人體姿態表示為 2.5D 人體中心點和 3D 人體關鍵點偏移,這一表示有效地適配了基于 RGB 圖片域的深度信息預測。同時,它也將人體位置信息和關鍵點位置信息進行了統一,從而使得基于單目圖片的單階段多人 3D 姿態估計方法成為可能。
另外,DAS 模型在優化過程中對 3D 關鍵點的分布進行學習,這為 3D 關鍵點的回歸提供了極具價值的指導性信息,從而有效地提升了預測精度。此外,為了緩解關鍵點分布估計的難度,DAS 模型采用了一種迭代更新策略以逐步逼近真實分布目標,通過這樣一種方式,DAS 模型可以高效且精準地從單目 RGB 圖片中一次性獲取多個人的 3D 人體姿態估計結果。
單階段多人 3D 姿態估計模型
在實現上,DAS 模型基于回歸預測框架來構建,對于給定圖片,DAS 模型通過一次前向預測輸出圖片中所包含人物的 3D 人體姿態。DAS 模型將人體中心點表示為中心點置信度圖和中心點坐標圖兩部分,如圖 1 (a) 和 (b) 所示,
其中,DAS 模型使用中心點置信度圖來定位 2D 圖片坐標系中人體投影中心點的位置,而使用中心點坐標圖來預測 3D 相機坐標系內人體中心點的絕對位置。DAS 模型將人體關鍵點建模為關鍵點偏移圖,如圖 1 (c) 所示。
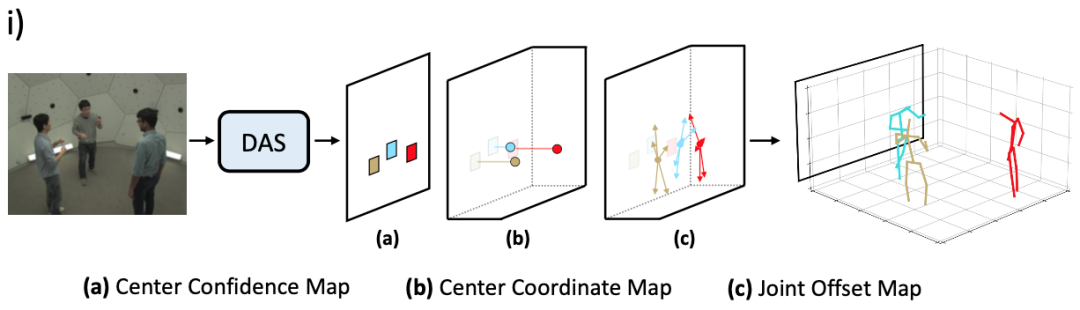
圖 1:用于多人 3D 人體姿態估計的分布感知式單階段模型流程圖。
DAS 模型將中心點置信度圖建模為二值圖,圖中每個像素點表示人體中心點是否在該位置出現,如果出現則為 1,否則為 0。DAS 模型將中心點坐標圖以稠密圖的方式進行建模,圖中每個像素點編碼了出現在該位置的人物中心在 x、y 和 z 方向的坐標。關鍵點偏移圖和中心點坐標圖建模方式類似,圖中每個像素點編碼了出現在該位置的人體關鍵點相對于人體中心點在 x、y、z 方向的偏移量。DAS 模型可以在網絡前向過程中以并行的方式輸出以上三種信息圖,從而避免了冗余計算。
此外,DAS 模型可以使用這三種信息圖簡單地重建出多個人的 3D 姿態,也避免了復雜的后處理過程,與兩階段方法相比,這樣一種緊湊、簡單的單階段模型可以取得更優的效率。
分布感知學習模型
對于回歸預測框架的優化,已有工作多采用傳統的 L1 或者 L2 損失函數,但研究發現這類監督訓練實際上是在假設人體關鍵點的數據分布滿足拉普拉斯分布或者高斯分布的前提下進行的模型優化 [12]。然而在實際場景中,人體關鍵點的真實分布極為復雜,以上簡單的假設與真實分布相距甚遠。
與現有方法不同,DAS 模型在優化過程中學習 3D 人體關鍵點分布的真實分布,指導關鍵點回歸預測的過程。考慮到真實分布不可追蹤的問題,DAS 模型利用標準化流(Normalizing Flow)來達到對于模型預測結果概率估計的目標,以生成適合模型輸出的分布,如圖 2 所示。
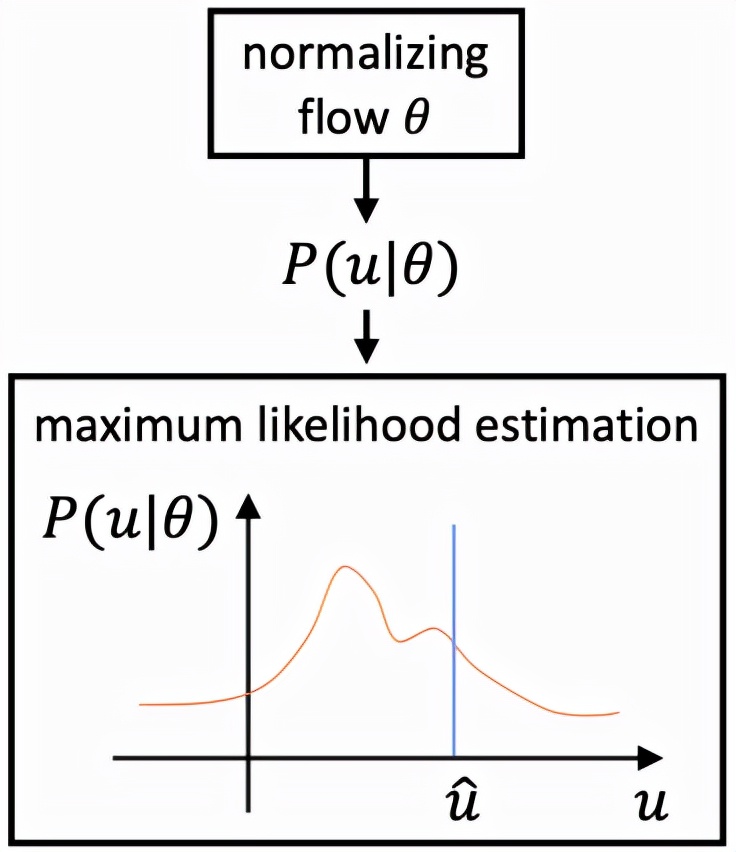
圖 2:標準化流。
該分布感知模塊可以同關鍵點預測模塊一起在訓練過程中通過最大似然估計的方法進行學習,完成學習之后,該分布感知模塊會在預測過程中進行移除,這樣一種分布感知式算法可以在不增加額外計算量的同時提升回歸預測模型的精度。
此外,用于人體關鍵點預測的特征提取于人體中心點處,這一特征對于遠離中心點的人體關鍵點來說表示能力較弱,和目標在空間上的不一致問題會引起預測的較大誤差。為了緩和這一問題,該算法提出了迭代更新策略,該策略利用歷史更新結果為出發點,并整合中間結果附近預測值以逐步逼近最終目標,如圖 3 所示
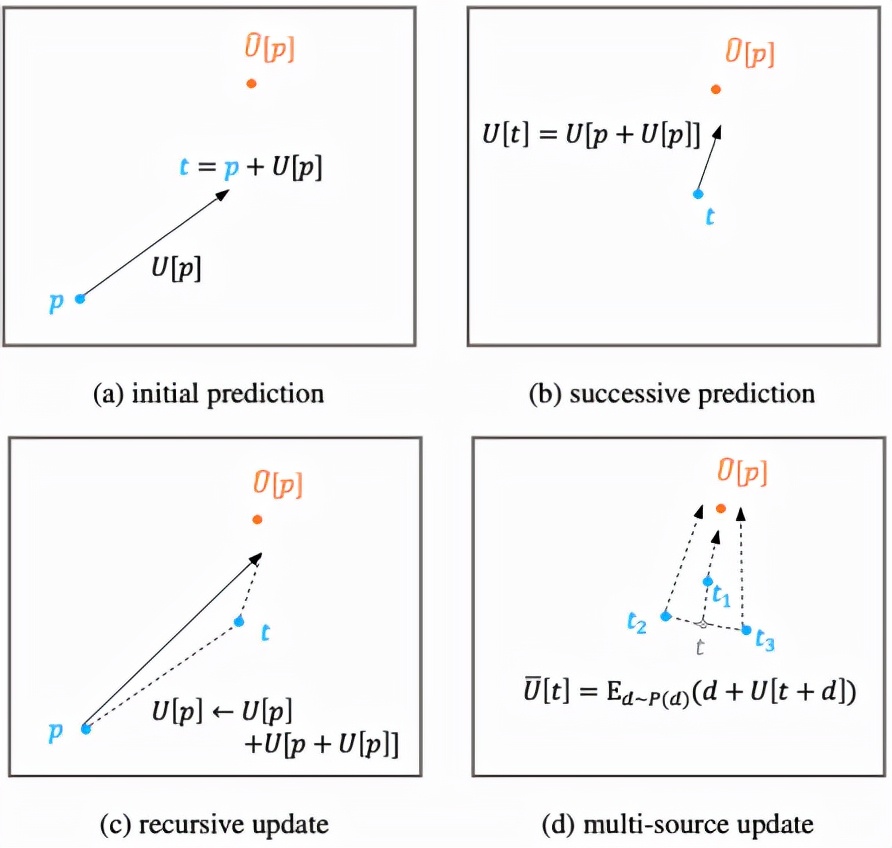
圖 3:迭代優化策略。
該算法模型通過全卷積網絡(Fully Convolutional Networks, FCNs)實現,訓練和測試過程都可以以端到端的方式進行,如圖 4 所示。
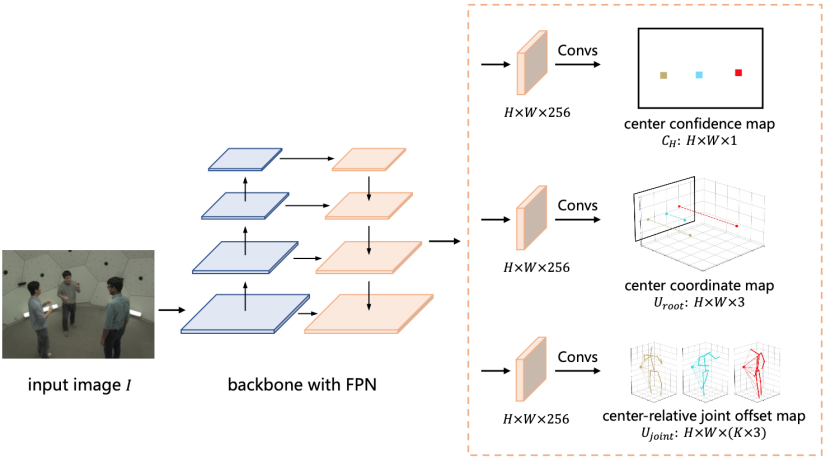
圖 4:分布感知式單階段多人 3D 人體姿態估計網絡結構。
根據實驗結果,如圖 5 所示,單階段算法和已有 state-of-the-art 兩階段方法相比,可以取得接近甚至更優的精度,同時可以大幅提升速度,證明了其在解決多人 3D 人體姿態估計這一問題上的優越性。
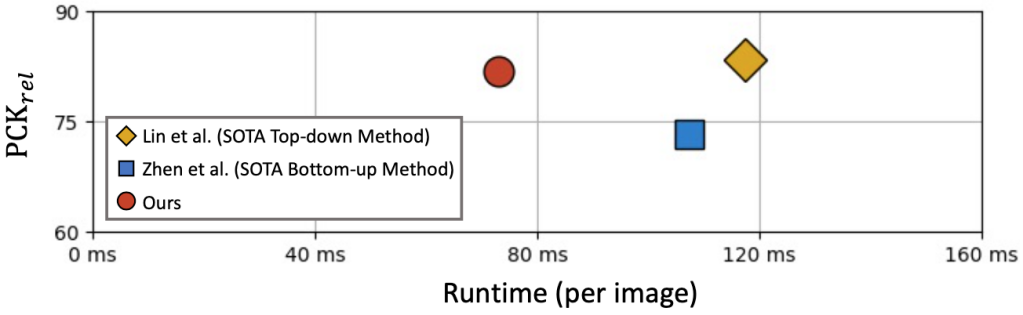
圖 5:與現有 SOTA 兩階段算法對比結果。
詳細實驗結果可參考表 1 和表 2。
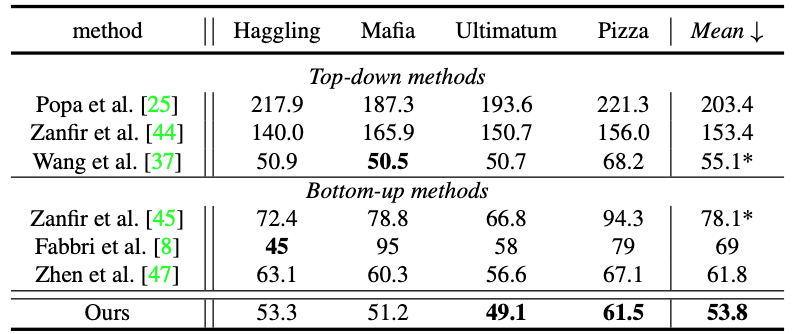
表 1:CMU Panoptic Studio 數據集結果比較。
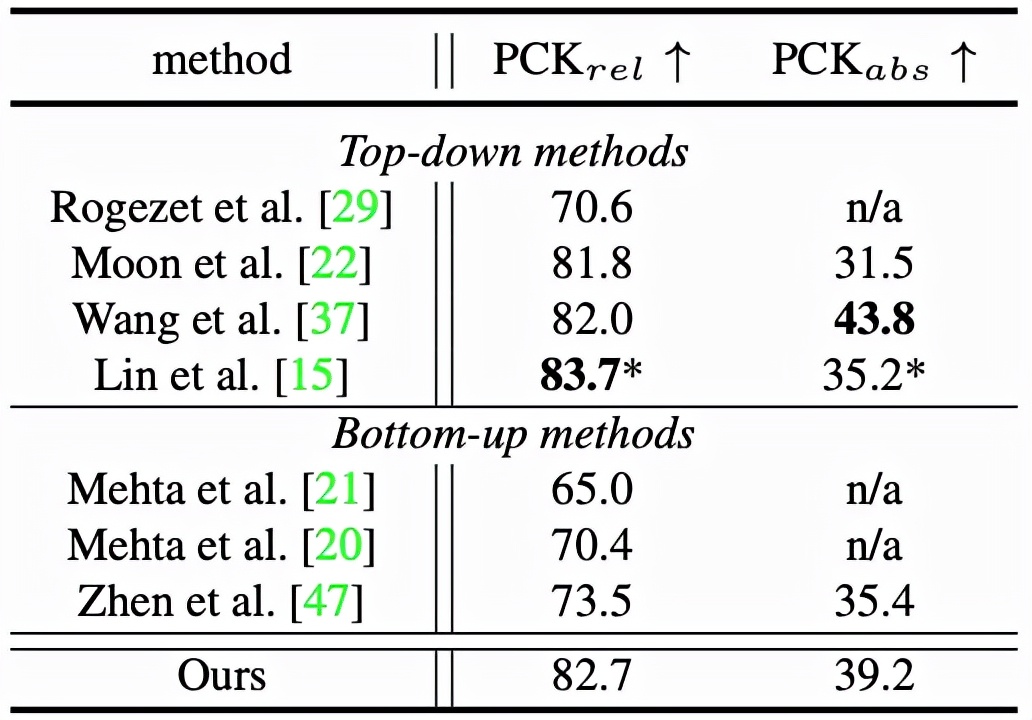
表 2:MuPoTS-3D 數據集結果比較。
根據單階段算法的可視化結果,如圖 6 所示,該算法能夠適應不同的場景,例如姿勢變化、人體截斷以及雜亂背景等來產生精確的預測結果,這進一步說明了該算法的健壯性。
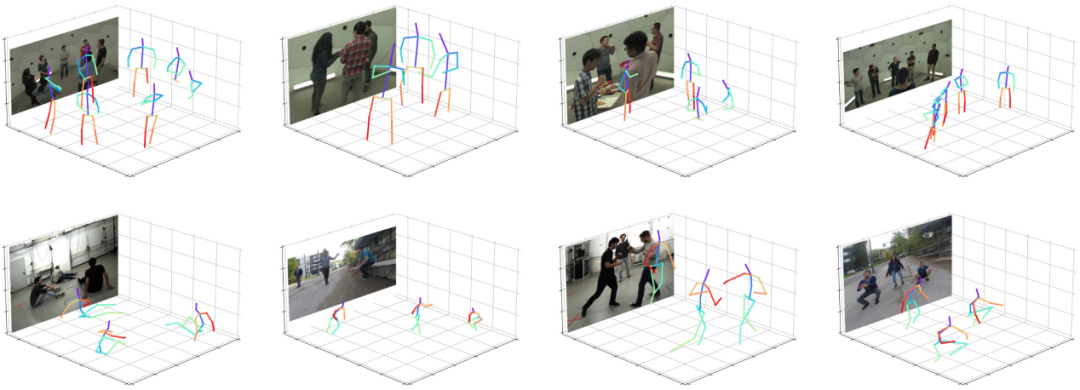
圖 6:可視化結果。
總結
在本論文中,美圖和北航的研究者們創新性地提出了一種分布感知式單階段模型,用于解決極具挑戰性的多人 3D 人體姿態估計問題。與已有的自頂向下和自底向上這種兩階段模型相比,該模型可以通過一次網絡前向推理同時獲取人體位置信息以及所對應的人體關鍵點位置信息,從而有效地簡化預測流程,同時克服了已有方法在高計算成本和高模型復雜度方面的弊端。
另外,該方法成功將標準化流引進到多人 3D 人體姿態估計任務中以在訓練過程中學習人體關鍵點分布,并提出迭代回歸策略以緩解分布學習難度來達到逐步逼近目標的目的。通過這樣一種方式,該算法可以獲取數據的真實分布以有效地提升模型的回歸預測精度。
研究團隊
本論文由美圖影像研究院(MT Lab)和北京航空航天大學可樂實驗室(CoLab)研究者們共同提出。美圖影像研究院(MT Lab)是美圖公司致力于計算機視覺、機器學習、增強現實、云計算等領域的算法研究、工程開發和產品化落地的團隊,為美圖現有和未來的產品提供核心算法支持,并通過前沿技術推動美圖產品發展,被稱為「美圖技術中樞」,曾先后多次參與 CVPR、ICCV、ECCV 等計算機視覺國際頂級會議,并斬獲冠亞軍十余項。
引用文獻:
[1] JP Agnelli, M Cadeiras, Esteban G Tabak, Cristina Vilma Turner, and Eric Vanden-Eijnden. Clustering and classifica- tion through normalizing flows in feature space. Multiscale Modeling & Simulation, 2010.
[12] Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang, Wentao Liu, and Cewu Lu. Human pose regression with residual log-likelihood estimation. In ICCV, 2021.
[15] Jiahao Lin and Gim Hee Lee. Hdnet: Human depth estima- tion for multi-person camera-space localization. In ECCV, 2020.
[47] Jianan Zhen, Qi Fang, Jiaming Sun, Wentao Liu, Wei Jiang, Hujun Bao, and Xiaowei Zhou. Smap: Single-shot multi- person absolute 3d pose estimation. In ECCV, 2020.
[48] Xingyi Zhou, Dequan Wang, and Philipp Kra ?henbu ?hl. Ob- jects as points. arXiv preprint arXiv:1904.07850, 2019.