UniPAD:一種通用的自動駕駛預(yù)訓(xùn)練模式
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
寫在前面&筆者的個人理解
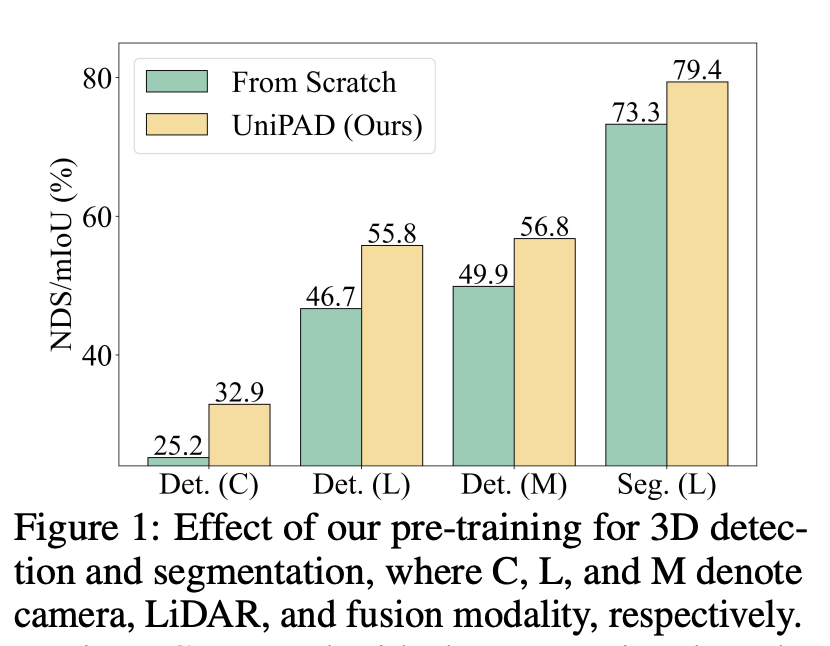
UniPAD研究了一個關(guān)鍵問題:如何有效地利用大量未標(biāo)記的3D點(diǎn)云數(shù)據(jù)進(jìn)行自監(jiān)督學(xué)習(xí),以增強(qiáng)其在3D目標(biāo)檢測和語義分割等下游任務(wù)中的應(yīng)用效率。這個問題之所以重要,是因?yàn)樵谧詣玉{駛和許多其他領(lǐng)域,3D點(diǎn)云數(shù)據(jù)的有效使用能夠極大提高任務(wù)執(zhí)行的準(zhǔn)確性和可靠性。盡管2D圖像領(lǐng)域的自監(jiān)督學(xué)習(xí)已經(jīng)取得了顯著進(jìn)展,但由于3D點(diǎn)云數(shù)據(jù)的固有稀疏性和點(diǎn)分布的變異性,將這些方法擴(kuò)展到3D點(diǎn)云上面臨著更大的挑戰(zhàn)。
傳統(tǒng)的針對3D場景理解的預(yù)訓(xùn)練范式主要基于對比學(xué)習(xí)和遮蔽自編碼(MAE)兩大類方法,它們或面臨樣本選擇的敏感性和實(shí)際應(yīng)用的局限性,或在處理3D點(diǎn)云數(shù)據(jù)的不規(guī)則性和稀疏性方面遇到挑戰(zhàn)。特別是,3D點(diǎn)云的遮蔽自編碼任務(wù)在細(xì)粒度的幾何結(jié)構(gòu)預(yù)測上往往效果不佳,因?yàn)閭鹘y(tǒng)方法可能無法有效捕獲3D空間中的連續(xù)性和結(jié)構(gòu)信息。
針對上述挑戰(zhàn),論文提出了一種新穎的預(yù)訓(xùn)練范式,專為3D表示學(xué)習(xí)量身定制。該方法通過3D可微分神經(jīng)渲染,以投影的2D深度圖像上重建缺失的幾何結(jié)構(gòu)為目標(biāo),避免了復(fù)雜的正負(fù)樣本分配,并隱式提供了連續(xù)的監(jiān)督信號來學(xué)習(xí)3D形狀結(jié)構(gòu)。這一方法不僅提高了訓(xùn)練效率和內(nèi)存使用的經(jīng)濟(jì)性,而且通過創(chuàng)新的采樣策略,在精確性上取得了顯著提升。
該研究的貢獻(xiàn)主要體現(xiàn)在三個方面:
- 首次探索了一種新穎的3D可微分渲染方法,用于自動駕駛場景下的自監(jiān)督學(xué)習(xí)。
- 該方法易于擴(kuò)展,以預(yù)訓(xùn)練2D背景模型,并通過創(chuàng)新的采樣策略,在有效性和效率上顯示出其優(yōu)越性。
- 通過在nuScenes數(shù)據(jù)集上進(jìn)行廣泛實(shí)驗(yàn),該方法在多種預(yù)訓(xùn)練策略中性能最優(yōu),并且在七種背景模型和兩種感知任務(wù)上的實(shí)驗(yàn)結(jié)果,為該方法的有效性提供了有力證據(jù)。
總體而言,這項(xiàng)研究為3D點(diǎn)云數(shù)據(jù)的自監(jiān)督學(xué)習(xí)提出了一個創(chuàng)新的方法論框架,有效解決了之前方法存在的問題,同時在3D目標(biāo)檢測和語義分割等關(guān)鍵任務(wù)上實(shí)現(xiàn)了顯著的性能提升。
方法
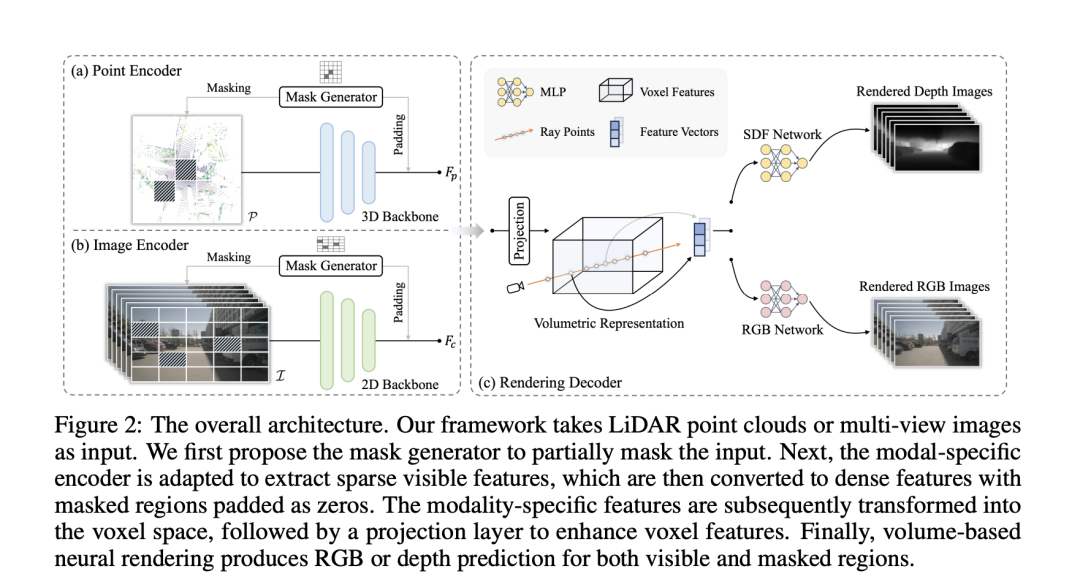
Modal-specific Encoder
在這個段落中,"Modal-specific Encoder"(模態(tài)特定編碼器)是一種為不同類型的輸入數(shù)據(jù)(例如LiDAR點(diǎn)云和多視圖圖像)設(shè)計(jì)的編碼器,用于提取高質(zhì)量的特征表示。這種編碼器針對每種輸入數(shù)據(jù)的特性進(jìn)行優(yōu)化,以有效處理數(shù)據(jù)的特定結(jié)構(gòu)和信息。
- 對于LiDAR點(diǎn)云,使用如VoxelNet這樣的點(diǎn)編碼器來提取層次化特征。這種編碼器能夠處理點(diǎn)云的稀疏性,并從中提取有用的空間信息。
- 對于多視圖圖像,則采用經(jīng)典的卷積網(wǎng)絡(luò)來提取特征。這種網(wǎng)絡(luò)適用于處理圖像數(shù)據(jù),能夠捕捉到視覺紋理和形狀信息。
此外,為了在不犧牲高級信息的同時捕獲細(xì)粒度的細(xì)節(jié),使用了額外的模態(tài)特定的FPN(Feature Pyramid Networks),這是一種高效聚合多尺度特征的方法,進(jìn)一步增強(qiáng)了模型對于不同尺度信息的處理能力。
Mask Generator(遮罩生成器)是一種數(shù)據(jù)增強(qiáng)手段,通過選擇性地移除輸入數(shù)據(jù)的一部分來提高模型的泛化能力和表示能力。這種方法靈感來自之前的自監(jiān)督學(xué)習(xí)方法,如He等人提出的MAE,通過增加訓(xùn)練難度來增強(qiáng)模型性能。在這個框架下,遮罩生成器采用塊狀遮罩,針對點(diǎn)云或圖像,生成遮罩并應(yīng)用到輸出特征圖的大小上,然后將其上采樣到原始輸入分辨率。對于點(diǎn)云,通過移除被遮罩區(qū)域的信息來獲取可見區(qū)域;對于圖像,則采用稀疏卷積,僅在可見位置進(jìn)行計(jì)算。編碼后,被遮罩的區(qū)域以零填充,并與可見特征結(jié)合形成規(guī)則的密集特征圖。
"Modal-specific Encoder"和"Mask Generator"共同構(gòu)成了一個強(qiáng)大的框架,通過模態(tài)特定的特征提取和創(chuàng)新的數(shù)據(jù)增強(qiáng)技術(shù),顯著提升了自監(jiān)督學(xué)習(xí)在處理復(fù)雜3D點(diǎn)云和圖像數(shù)據(jù)時的效率和性能。
Unified 3D Volumetric Representation
Unified 3D Volumetric Representation(統(tǒng)一的3D體積表示)是一種將來自不同模態(tài)的數(shù)據(jù)(如LiDAR點(diǎn)云和多視圖圖像)轉(zhuǎn)換為統(tǒng)一的3D體積空間表示的方法。這種表示方法的目的是為了在預(yù)訓(xùn)練方法中兼容不同的輸入模態(tài),同時盡可能保留每種模態(tài)原始視圖中的信息。
對于多視圖圖像,2D特征被轉(zhuǎn)換到3D自車坐標(biāo)系中,以獲得體積特征。這一過程首先是定義3D體素坐標(biāo),其中是體素分辨率。然后,將投影到多視圖圖像上以索引相應(yīng)的2D特征。通過雙線性插值方法,結(jié)合變換矩陣和(分別代表從LiDAR坐標(biāo)系到相機(jī)幀和從相機(jī)幀到圖像坐標(biāo)的轉(zhuǎn)換),構(gòu)造出體積特征。
對于3D點(diǎn)云模態(tài),直接在點(diǎn)編碼器中保留高度維度,以直接利用點(diǎn)云數(shù)據(jù)的空間信息。
在此基礎(chǔ)上,通過使用包含個卷積層的投影層,進(jìn)一步增強(qiáng)了體素表示的能力,使其能夠更好地捕捉和表達(dá)3D空間中的細(xì)節(jié)和結(jié)構(gòu)信息。

Neural Rendering Decoder
該部分引入了一種利用神經(jīng)渲染技術(shù)靈活整合幾何或紋理線索到學(xué)習(xí)到的體積特征中的新方法,這在統(tǒng)一的預(yù)訓(xùn)練架構(gòu)中實(shí)現(xiàn)了對體積特征的有效使用。具體來說,提供體積特征后,從多視圖圖像或點(diǎn)云中采樣一些光線,并使用可微分體積渲染技術(shù)為每條光線渲染顏色或深度。這種靈活性進(jìn)一步促進(jìn)了將3D先驗(yàn)融入所獲取的圖像特征中,通過額外的深度渲染監(jiān)督實(shí)現(xiàn),確保了其能夠無縫集成到2D和3D框架中。
通過使用隱式符號距離函數(shù)(SDF)場來表示場景,能夠高質(zhì)量地表現(xiàn)出幾何細(xì)節(jié)。SDF表示查詢點(diǎn)與最近表面之間的3D距離,從而隱式地描述了3D幾何形態(tài)。對于每個光線點(diǎn),可以從體積表示中通過三線性插值提取特征嵌入。然后,通過淺層MLP預(yù)測SDF值。
對于顏色值,根據(jù)表面法線(即SDF值在光線點(diǎn)處的梯度)和來自的幾何特征向量,通過MLP來確定顏色場。最后,通過沿光線集成預(yù)測的顏色和采樣深度來渲染RGB值和深度。
此外,為了減輕計(jì)算負(fù)擔(dān),提出了三種內(nèi)存友好的光線采樣策略:擴(kuò)張采樣、隨機(jī)采樣和深度感知采樣。這些策略通過選擇性地采樣光線,而不是渲染整個圖像的所有光線,從而減少了計(jì)算需求,同時優(yōu)化了神經(jīng)渲染的精確度,專注于場景中最相關(guān)的部分。整體預(yù)訓(xùn)練損失由顏色損失和深度損失組成,用于訓(xùn)練模型以精確渲染給定場景的顏色和深度,從而在不同模態(tài)間建立了一個高效、統(tǒng)一且信息豐富的3D體積表示。
實(shí)驗(yàn)
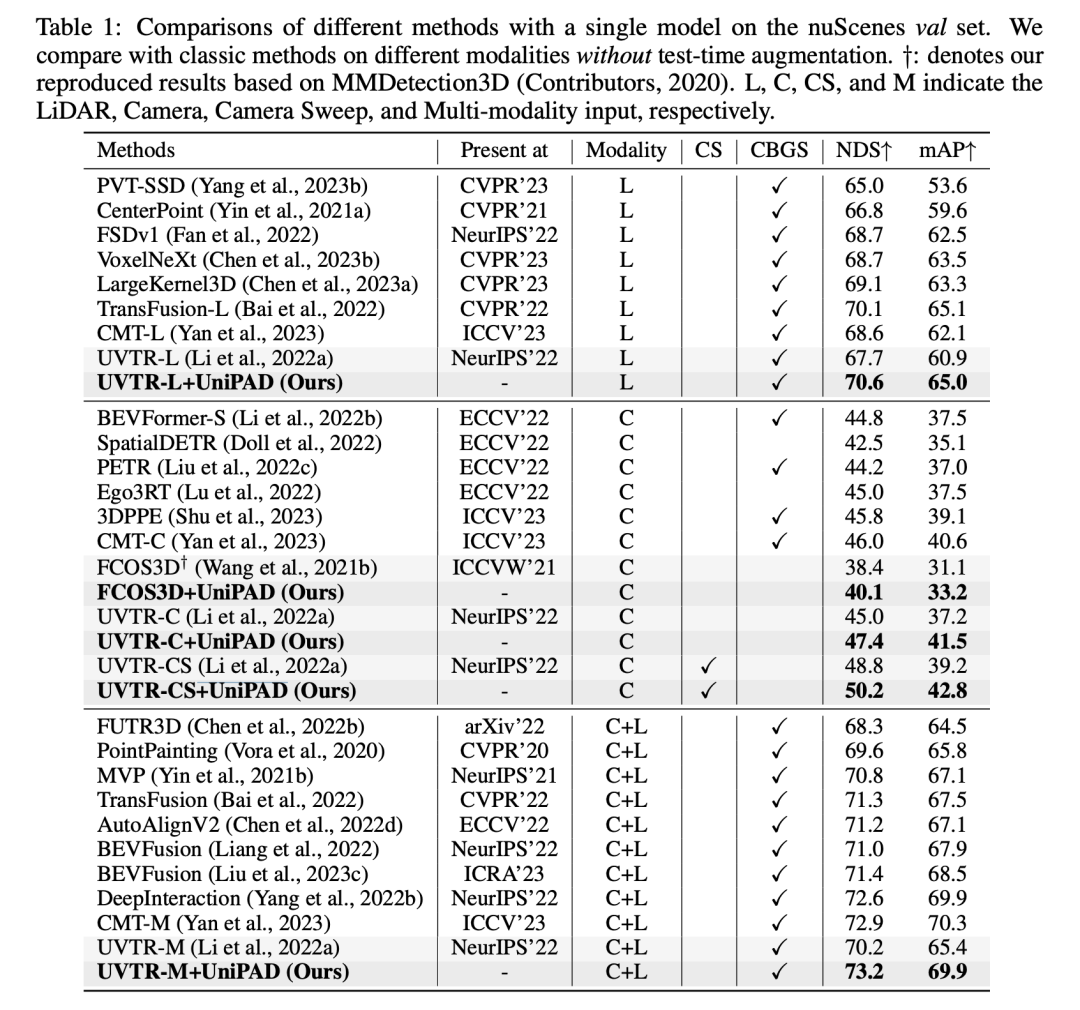
在這張表格的實(shí)驗(yàn)結(jié)果中,+UniPAD的方法在不同模態(tài)的輸入數(shù)據(jù)上表現(xiàn)出色。這些模態(tài)包括LIDAR (L)、Camera (C)、Camera Stereo (CS) 和 Multi-input (C+L),對應(yīng)于不同的3D目標(biāo)檢測和語義分割任務(wù)。通過使用UniPAD方法,我們看到在各種不同的配置和數(shù)據(jù)輸入模態(tài)中,性能普遍得到提升。
當(dāng)專注于LiDAR模態(tài)時,+UniPAD版本的UVT-RL方法達(dá)到了70.6%的NDS(Normalized Detection Score)和65.0%的mAP(mean Average Precision),這是這個類別中最高的得分。這表明UniPAD方法在處理點(diǎn)云數(shù)據(jù)時非常有效,能夠提高模型的檢測性能和精確度。在Camera模態(tài)中,UVT-RC+UniPAD版本比起原始的UVT-RC方法,在NDS和mAP上也有明顯的提升。例如,原始的UVT-RC方法的NDS為45.0%,而UVT-RC+UniPAD的NDS為47.4%,在mAP上也從37.2%提高到了41.5%。當(dāng)數(shù)據(jù)輸入是Camera Stereo時,我們看到UVT-CS+UniPAD在NDS上得到了顯著的提升,從原來的UVT-CS的48.3%提升至50.2%,在mAP上也從39.2%提升至42.8%。這表明UniPAD方法能夠利用立體視覺的深度信息,以提高性能。
最后,在使用多種輸入模態(tài)(Camera+LiDAR)的配置中,UVT-M+UniPAD方法在NDS上實(shí)現(xiàn)了73.2%,在mAP上實(shí)現(xiàn)了69.9%,這是所有列出配置中的最高分。這表明UniPAD方法能夠有效地整合來自不同傳感器的信息,進(jìn)一步提高了模型在復(fù)雜場景下的表現(xiàn)。UniPAD方法的引入為各種基線方法帶來了性能的顯著提升,這證明了UniPAD在多種傳感器數(shù)據(jù)融合和自監(jiān)督預(yù)訓(xùn)練方面的有效性。這些改進(jìn)可能是由于UniPAD方法能夠更好地理解和整合來自不同模態(tài)的數(shù)據(jù),從而為3D目標(biāo)檢測和語義分割任務(wù)提供了更豐富和更準(zhǔn)確的特征表示。
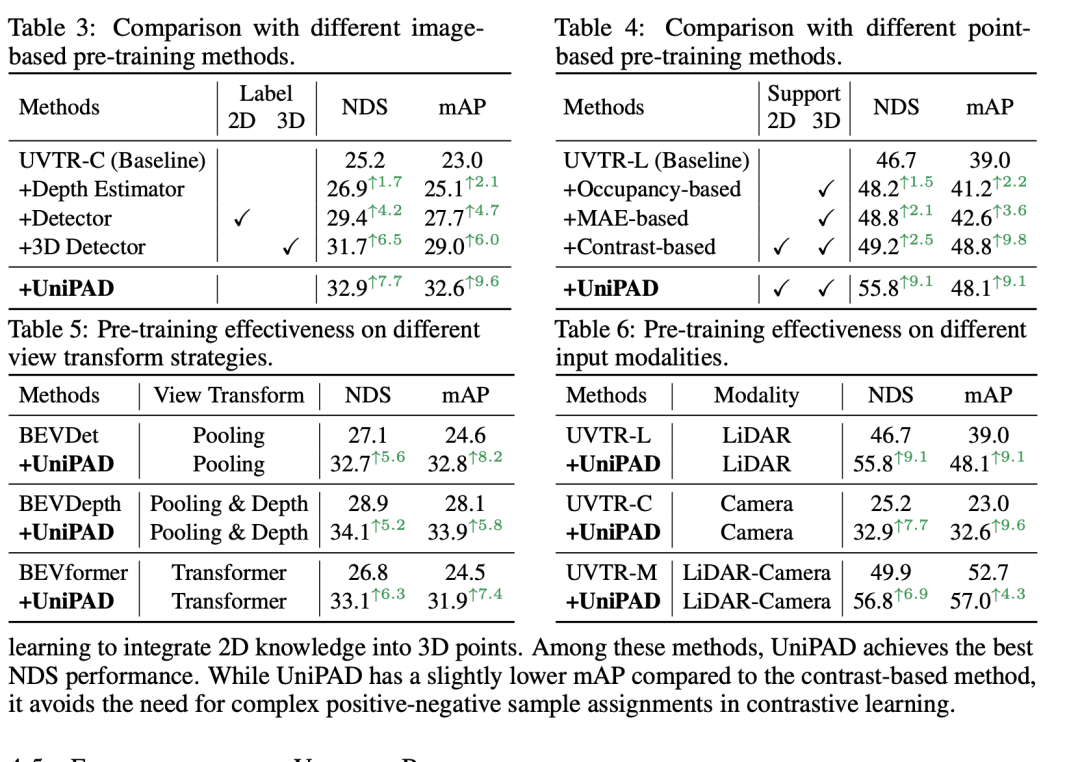
消融實(shí)驗(yàn)通常用來理解不同組件對模型性能的影響。根據(jù)提供的表格內(nèi)容,我們可以總結(jié)以下關(guān)于體積基神經(jīng)渲染的消融研究結(jié)果:
- 遮罩比例 (Mask ratio): 使用0.3的遮罩比例在NDS和mAP上分別取得了32.9%和32.6%的得分,表現(xiàn)出是這一系列實(shí)驗(yàn)中的最佳設(shè)置。這表明在輸入數(shù)據(jù)中遮蔽30%的部分可以提供最佳的訓(xùn)練難度,有利于模型學(xué)習(xí)。
- 解碼器深度 (Decoder depth): 解碼器的深度影響模型的性能。一個具有(6, 4)層的解碼器在NDS上達(dá)到了32.9%,這是測試的配置中最高的,表明一個較深的解碼器可以提高精度。
- 解碼器寬度 (Decoder width): 解碼器的寬度對性能的影響較小。不同維度的解碼器在NDS和mAP上的得分差異不大,最高分?jǐn)?shù)與最低分?jǐn)?shù)相差不到0.5%。
- 渲染技術(shù) (Rendering technique): 在測試的三種不同的渲染方法中,NeuS方法(NDS 32.9%, mAP 32.6%)略勝一籌,表明良好設(shè)計(jì)的渲染技術(shù)對于表示學(xué)習(xí)是有益的。
- 采樣策略 (Sampling strategy): 深度感知采樣在NDS和mAP上均取得了32.9%和32.6%的最佳得分,優(yōu)于擴(kuò)張采樣和隨機(jī)采樣,這顯示出選擇性地采樣更為重要的區(qū)域可以提升渲染質(zhì)量和模型性能。
- 特征投影 (Feature projection): 特征投影對于增強(qiáng)體素表示至關(guān)重要。與基線模型相比,去掉投影層會導(dǎo)致NDS和mAP的性能下降,這表明特征投影對于保持高質(zhì)量的體素表示是必要的。
- 預(yù)訓(xùn)練組件 (Pre-trained components): 模型的預(yù)訓(xùn)練組件對于微調(diào)至關(guān)重要。只有編碼器的模型(NDS 32.0%, mAP 31.8%)比只有基線的模型(NDS 25.2%, mAP 23.0%)性能有顯著提升,而加入FPN和VT(Volume Transformer)后,模型在NDS上進(jìn)一步提升到了32.9%,在mAP上提升到了32.6%,證明了在預(yù)訓(xùn)練階段加入這些組件能夠顯著提升模型的性能。
通過這些消融實(shí)驗(yàn),我們可以看出每個組件和參數(shù)選擇如何影響最終的模型性能,并且可以得出哪些組件對于模型最為關(guān)鍵。這樣的分析有助于研究者們理解和優(yōu)化他們的模型結(jié)構(gòu)。
討論
這篇論文提出的方法在處理3D點(diǎn)云和多視圖圖像數(shù)據(jù)時表現(xiàn)出了顯著的優(yōu)勢。通過將數(shù)據(jù)統(tǒng)一轉(zhuǎn)換成3D體積表示,并使用先進(jìn)的神經(jīng)渲染技術(shù),該方法在預(yù)訓(xùn)練階段就能學(xué)習(xí)到豐富的幾何和紋理特征,這在后續(xù)的下游任務(wù)中證明是有益的。特別是通過深度感知采樣,該方法優(yōu)先處理更為重要的數(shù)據(jù)區(qū)域,從而有效提高了模型的渲染質(zhì)量和整體性能。此外,特征投影和體積變換器的應(yīng)用進(jìn)一步加強(qiáng)了體積表示,使得模型能夠在預(yù)訓(xùn)練后更好地進(jìn)行微調(diào)。
盡管如此,方法也存在一些局限性。例如,盡管解碼器的深度和寬度調(diào)整顯示出對模型性能有細(xì)微的影響,但這也意味著在資源有限的情況下,選擇合適的模型規(guī)模和復(fù)雜度是一項(xiàng)挑戰(zhàn)。此外,盡管深度感知采樣策略在性能上取得了最佳結(jié)果,但它也依賴于高質(zhì)量的深度信息,這在實(shí)際應(yīng)用中可能受到傳感器質(zhì)量和環(huán)境因素的影響。最后,雖然預(yù)訓(xùn)練組件證明是提高性能的關(guān)鍵,但每個組件的設(shè)計(jì)和集成都需要仔細(xì)的考量,以確保模型的泛化能力和實(shí)際應(yīng)用的有效性。這些挑戰(zhàn)需要未來的研究工作來進(jìn)一步探討和解決。
結(jié)論
總結(jié)來說,這篇論文介紹的方法通過創(chuàng)新性地將3D點(diǎn)云和多視圖圖像統(tǒng)一到3D體積表示,并運(yùn)用先進(jìn)的神經(jīng)渲染技術(shù),顯著提升了自監(jiān)督學(xué)習(xí)的效果。該方法通過深度感知采樣策略和有效的特征投影,使得預(yù)訓(xùn)練模型在多個下游任務(wù)中都取得了卓越的性能。然而,面對模型規(guī)模和復(fù)雜度的選擇,以及在變化的環(huán)境和傳感器條件下保持性能的挑戰(zhàn),仍有進(jìn)一步的優(yōu)化空間。未來的工作可以在提高模型的魯棒性和適應(yīng)性上進(jìn)行更多的探索,以實(shí)現(xiàn)對這種方法的全面優(yōu)化和應(yīng)用。