譯者 | 朱先忠
審校 | 重樓
引言
我不得不承認,我最初對大型語言模型(LLM)生成實際有效的代碼片段的能力持懷疑態度。我抱著最壞的打算嘗試了一下,結果我感到很驚喜。就像與聊天機器人的任何互動一樣,問題的格式很重要;但隨著時間的推移,你會知道如何指定你需要幫助的問題的邊界。
當我的老板發布了一項全公司范圍的政策——禁止員工使用在線聊天機器人服務時,我已經習慣了在編寫代碼時始終可以使用這類服務。盡管我可以回到以前的谷歌搜索習慣,但我還是決定建立一個在本地運行的LLM服務;這樣一來,我就可以在不將信息泄露到公司外面的情況下繼續向機器人提出問題了。最后,多虧了HuggingFace網站(https://huggingface.co/)上的開源LLM產品和chailit項目(https://docs.chainlit.io/get-started/overview),我終于可以開發出一個能夠提供編碼輔助需求的服務程序。
隨后的一個合乎邏輯的步驟就是添加一些語音交互功能。盡管語音不太適合作為編碼輔助(你想看到生成的代碼片段,而不是聽到它們),但在某些情況下,你需要在創意項目中獲得靈感,畢竟聽他人講故事的感覺總會進一步增加體驗感。另一方面,你可能不愿意使用在線服務,因為你想保密你所做的工作。
在接下來的這個項目中,我將帶您完成構建一個語音助理的所有步驟,該助理允許您與開源LLM進行語音交互。所有組件都將在您的計算機上以本地方式運行。
系統構架
這個項目的體系結構包括三個獨立的組件:
- 一個喚醒詞檢測服務
- 一個語音助理服務
- 一個聊天服務
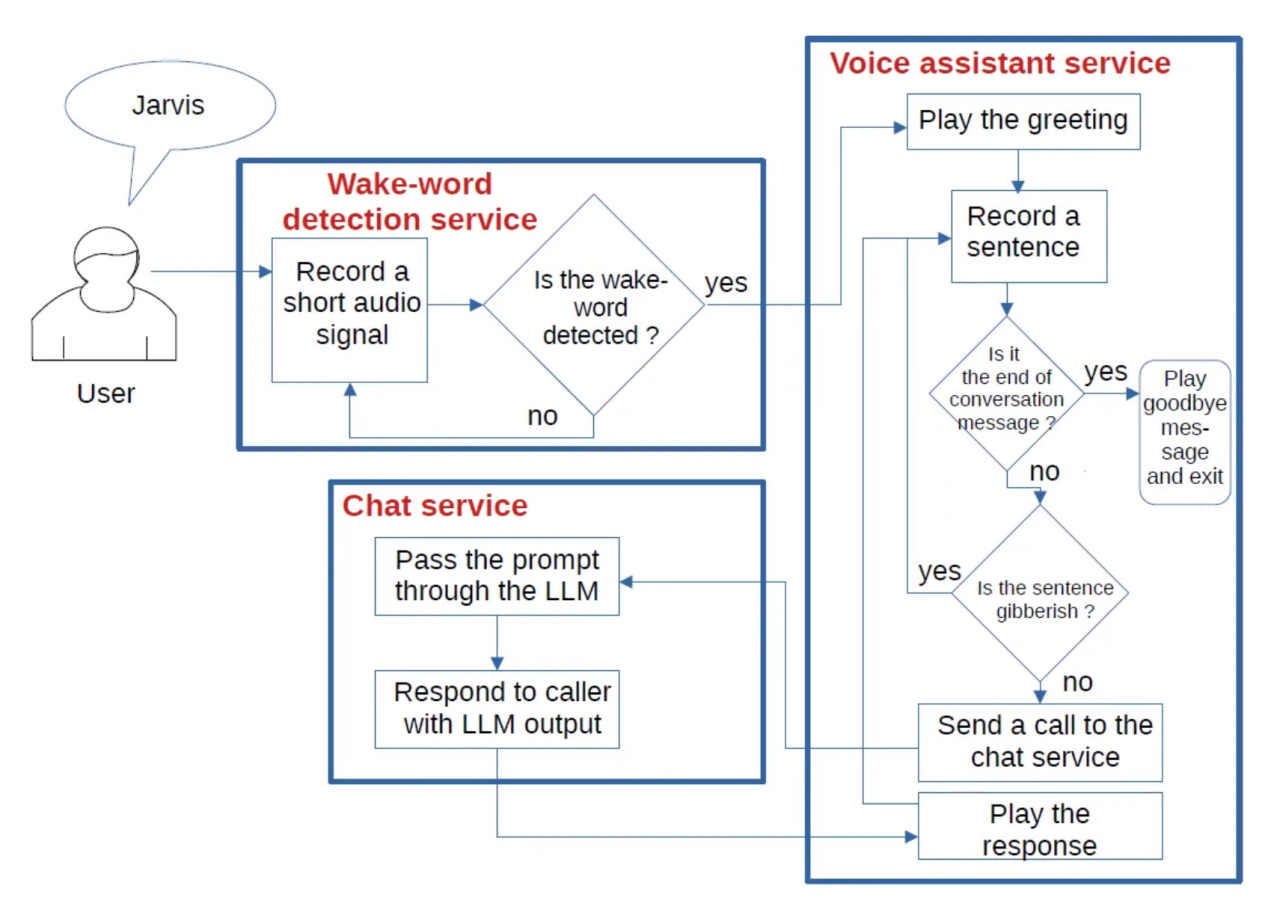
由三部分組成的系統架構流程圖(作者本人提供的圖片)
注意,這三個組件是獨立的項目,每個都有自己獨立的Github存儲倉庫。下面,讓我們分析一下每個組件,并了解一下它們是如何相互作用的。
聊天服務
該聊天服務運行一個名為HuggingFaceH4/zephyr-7b-alpha(https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha)的開源LLM。該服務通過POST調用接收提示,通過LLM傳遞提示,并將輸出作為調用響應返回。
你可以從鏈接https://github.com/sebastiengilbert73/chat_service處找到此服務相關代碼。
在路徑…/chat_service/server/中,我們將文件chat_server_config.xml.example重命名為chat_server/config.xml。
然后,您可以使用以下命令啟動聊天服務器:
python .\chat_server.py
當該服務首次運行時,需要幾分鐘才能啟動,因為大型文件會從HuggingFace網站下載并存儲在本地緩存目錄中。
最后,您將從終端觀察到服務正在運行的確認信息:
確認聊天服務正在運行(作者本人提供的圖片)
如果您想測試與LLM的交互,請轉到…/chat_service/chainlit_interface/路徑下,將文件app_config.xml.example重命名為app_config.xml。然后,使用如下命令啟動Web聊天服務:
.\start_interface.sh
然后,你可以從本地地址localhost:8000進行瀏覽。一切正常的話,您應該能夠通過文本界面與本地運行的LLM進行交互:
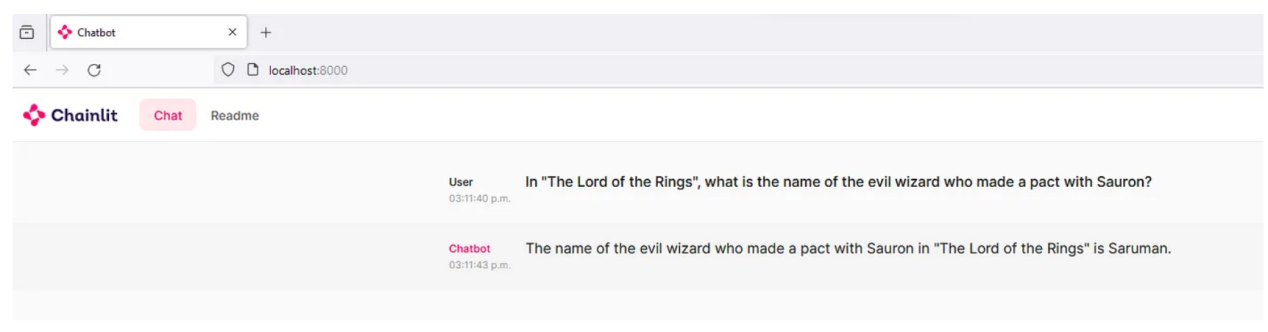
與本地運行的LLM進行文本交互(作者本人提供的圖片)
語音助理服務
語音助理服務是進行語音到文本和文本到語音轉換的地方。你可以從鏈接https://github.com/sebastiengilbert73/voice_assistant處下載到這個語音助理服務完整的代碼。
切換到如下路徑:
…/voice_assistant/server/
然后,將文件voice_assistant_service_config.xml.example重命名為voice_aassistant_service-config.xml。
助理首先播放問候語,表示正在聆聽用戶說話。其中,問候語相應的文本配置在voice_assistant_config.xml中的元素<welcome_message>下:
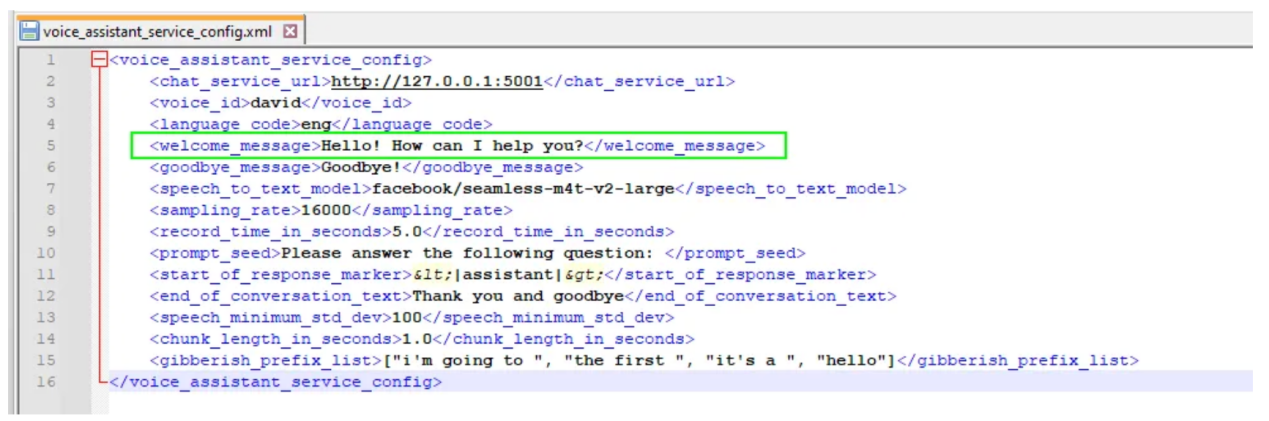
voice_assistant_config.xml文件關鍵內容(作者本人提供的圖片)
文本到語音引擎是pyttsx3(https://pypi.org/project/pyttsx3/),它允許程序將文本轉換為您可以通過音頻輸出設備聽到的口語音頻。根據我的經驗,無論是英語還是法語,這個引擎的聲音都相當自然。與其他依賴API調用的軟件包不同,它在本地運行。
一個名為facebook/seamless-m4t-v2-lage(https://huggingface.co/facebook/seamless-m4t-v2-large)的模型負責執行語音到文本的推理。首次運行voice_assistant_service.py時會下載模型權重。
函數voice_assistant_service.main()中的主循環執行以下任務:
- 從麥克風中獲取一句話。使用語音到文本模型將其轉換為文本。
- 檢查用戶是否說出了配置文件中<end_of_enversation_text>元素中定義的消息。在這種情況下,對話結束,并且程序在播放完再見消息后終止。
- 檢查句子是否是胡言亂語。語音轉文本引擎通常會輸出一個有效的英語句子,即使我什么都沒說。在偶然的情況下,這些不受歡迎的輸出往往會重復出現。例如,胡言亂語句子有時會以“[”或“i’m going to”開頭。我在配置文件的<gibbish_prefix_list>元素中收集了一個前綴列表,這些前綴通常與胡言亂語語句相關(該列表可能會因另一個語音到文本模型而更改)。每當音頻輸入以列表中的一個前綴開頭時,該句子就會被忽略。
- 如果句子看起來沒有胡言亂語,就會向聊天服務發送請求,然后播放回應。
end_of_conversation = False
while not end_of_conversation:
transcription = get_sentence(
mic_stream, stt_processor, stt_model, device, config.sampling_rate,
config
)
if transcription.lower().replace('.', '').replace('!', '') == config.end_of_conversation_text.lower():
logging.info(f"voice_assistant_service.main(): End of conversation")
end_of_conversation = True
else:
sentence_is_gibberish = False
if transcription[0] == '[':
sentence_is_gibberish = True
for prefix in config.gibberish_prefix_list:
if transcription.lower().startswith(prefix):
sentence_is_gibberish = True
if len(transcription) > 15 and not sentence_is_gibberish:
response = send_request_to_chat_service(config, transcription)
logging.info(f"voice_assistant_service.main(): response = {response}")
play_message(response, engine, config)
goodbye(engine, config)voice_assistant_service.main()函數中的主循環(作者本人編寫的代碼)
喚醒詞服務
最后一個組件是持續監聽用戶麥克風的服務。當用戶說出喚醒詞時,系統呼叫啟動語音助理服務。喚醒詞服務運行的模型比語音助理服務模型更小。因此,讓喚醒詞服務持續運行是有意義的,而語音助理服務只在我們需要的時候啟動。
你可以從鏈接https://github.com/sebastiengilbert73/wakeword_service處找到喚醒詞服務代碼。
克隆完項目后,轉到路徑…/wakeword_service/server下,并將文件wakeword_service_gui_config.xml.example重命名為wakeword.service_gui-config.xml。
然后,將另一個文件command.bat.example重命名為command.bat。這里,您需要編輯一個文件command.bat,以便虛擬環境激活和對voice_assistant_service.py的調用與您的目錄結構相對應。
您可以通過以下調用來啟動服務:
python gui.py
喚醒詞檢測服務的核心是openwakeword項目(https://github.com/dscripka/openWakeWord)。在幾個喚醒詞模型中,我選擇了“hey jarvis”模型。我發現簡單地說“Jarvis?”就會觸發檢測。
每當檢測到喚醒字時,就會調用如配置文件的<command_on_wakeword>元素中所指定的一個命令文件。在我們的例子中,command.bat文件激活虛擬環境并啟動語音助理服務。
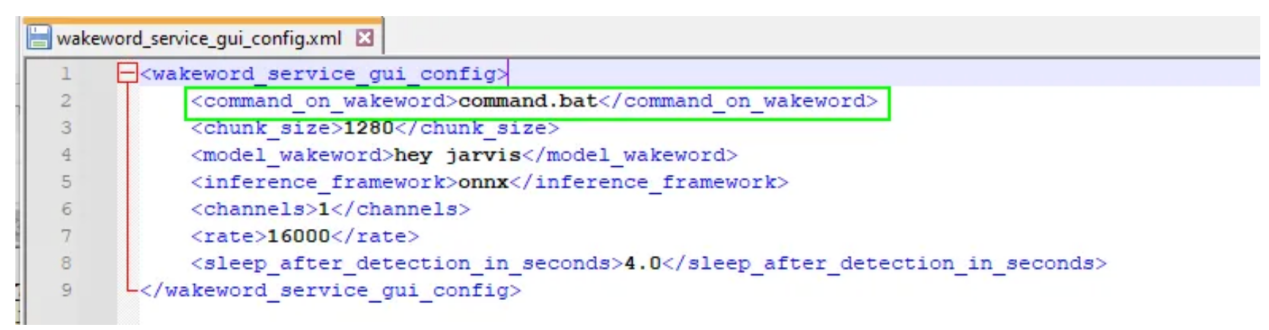
喚醒詞檢測服務GUI的配置文件(作者本人提供的圖片)
如果您想將喚醒詞檢測服務用于其他用途的話,可以編輯一下command.bat文件,使其啟動您想要啟動的任何程序即可。
當檢測到喚醒詞時,喚醒詞檢測服務會發出兩聲蜂鳴聲音頻信號,指示其已被觸發。這種快速反饋告訴用戶,他們必須等待,直到文本到語音和語音到文本模型加載到計算機的GPU中,這可能需要幾秒鐘的時間。當兩種型號都加載后,語音助理服務會播放問候語,對話就可以開始了。會話結束后,語音助理服務終止,喚醒詞檢測服務發出另一個兩聲蜂鳴聲信號。
當上述三個組件都安裝并測試完成后,我們就可以啟動聊天和喚醒詞檢測服務。喚醒詞檢測服務將不斷收聽麥克風。當檢測到喚醒詞(“Jarvis?”)時,它將啟動語音助理服務。然后,你可以大聲提問并得到口頭回答。當檢測到會話結束語(“Thank you and goodbye”)時,語音助理服務將結束。
與助理互動的示例
以下是與語音助理交互的示例:
“Jarvis?” [嘟嘟]
[語音助手模型加載時保持幾秒鐘的靜音]
“Hello! How can I help you?”
[中文意思]“你好,我能幫你什么?”
“What are Saturn’s rings made of?”
[中文意思]“土星環是由什么組成的?”
“Saturn’s rings are primarily composed of ice particles, with the majority being made up of water ice. However, there are also smaller amounts of other ices, such as ammonia ice and rocky debris, in the rings. The exact composition of the rings varies depending on the distance from Saturn, with the inner rings being denser and made up of smaller particles, while the outer rings are more spread out and contain larger ice particles.”
[中文意思]“土星環主要由冰顆粒組成,大部分由水冰組成。然而,環中也有少量的其他冰,如氨冰和巖石碎片。環的確切組成取決于與土星的距離,內環密度更大,由更小的顆粒組成,而外環則更為分散并含有更大的冰粒。”
“Tell me the plot of the movie ‘Back to the Future’.”
[中文意思]“告訴我電影《回到未來》的情節。”
“The movie ‘Back to the Future’ follows the story of Marty McFly, a high school student who is accidentally transported back to 1955 in a time-traveling DeLorean car created by his eccentric scientist friend, Doc Brown. Marty must navigate the challenges of the past while trying to repair the damage to the present and prevent his teenage mother from falling in love with his teenage father. Along the way, Marty befriends a younger version of Doc Brown and helps him overcome a personal tragedy. The movie explores themes of fate, family, and the consequences of altering the past.”
[中文意思]“電影《回到未來》講述了高中生Marty McFly的故事,他意外地被一輛由他古怪的科學家朋友Doc Brown駕駛的穿越DeLorean的汽車帶回了1955年。Marty必須應對過去的挑戰,同時努力修復對現在的傷害,防止他十幾歲的母親愛上他十多歲的父親。一路上,Marty與年輕版的Doc Brown交上了朋友,并幫助他克服了一場個人悲劇。這部電影探討了命運、家庭以及改變過去的后果等主題。”
“Thank you and goodbye”
[中文意思]“謝謝你,再見”
“Goodbye” [嘟嘟]
結論
在本文的項目中,我們實現了一個由喚醒詞檢測服務、語音助理服務和聊天服務組成的語音助理系統。這些組件中的每一個都是可用于其他項目的獨立構建組件。
在我開發這個語音助理時遇到的許多驚喜中,最讓我印象深刻的是語音到文本轉換的質量。如果你和我一樣,你可能也遇到過自動語音識別系統無法轉錄簡單命令(如“調低音量”)的問題!其實,我已經預計到語音到文本的轉換將成為整個項目開發的主要障礙。在嘗試了一些不很令人滿意的模型后,我登陸到模型facebook/seamless-m4t-v2-lage(https://huggingface.co/facebook/seamless-m4t-v2-large),此模型輸出結果的質量給我留下了深刻的印象。我甚至可以用法語說話,神經網絡會自動將其翻譯成英語。簡直太神奇了!
最后,我希望你也能嘗試一下這個有趣的項目,并讓我知道你會用它做什么!
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Build a Locally Running Voice Assistant,作者:Sébastien Gilbert
鏈接:https://towardsdatascience.com/build-a-locally-running-voice-assistant-2f2ead904fe9