













GPT-4時代已過?全球網友實測Claude 3,只有震撼
大模型的純文本方向,已經卷到頭了?
昨晚,OpenAI 最大的競爭對手 Anthropic 發布了新一代 AI 大模型系列 ——Claude 3。
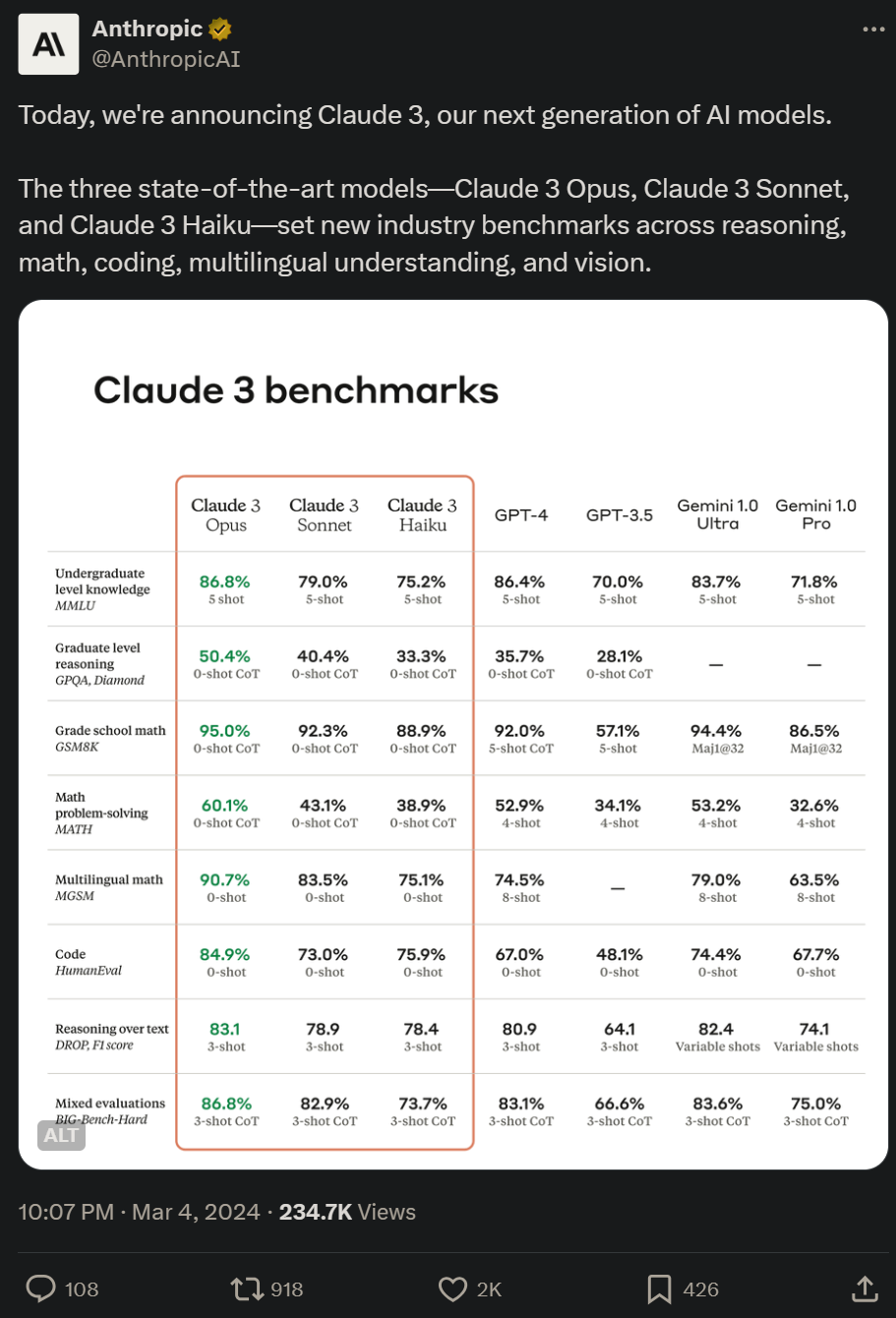
該系列包含三個模型,按能力由弱到強排列分別是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。其中,能力最強的 Opus 在多項基準測試中得分都超過了 GPT-4 和 Gemini 1.0 Ultra,在數學、編程、多語言理解、視覺等多個維度樹立了新的行業基準。
Anthropic 表示,Claude 3 Opus 擁有人類本科生水平的知識。
在新模型發布后,Claude 首次帶來了對多模態能力的支持(Opus 版本的 MMMU 得分為 59.4%,超過 GPT-4V,與 Gemini 1.0 Ultra 持平)。用戶現在可以上傳照片、圖表、文檔和其他類型的非結構化數據,讓 AI 進行分析和解答。
此外,這三個模型也延續了 Claude 系列模型的傳統強項 —— 長上下文窗口。其初始階段支持 200K token 上下文窗口,不過,Anthropic 表示,三者都支持 100 萬 token 的上下文輸入(向特定客戶開放),這大約是英文版《白鯨》或《哈利?波特與死亡圣器》的長度。
不過,在定價上,能力最強的 Claude 3 也比 GPT-4 Turbo 要貴得多:GPT-4 Turbo 每百萬 token 輸入 / 輸出收費為 10/30 美元 ;而 Claude 3 Opus 為 15/75 美元。
Opus 和 Sonnet 現可在 claude.ai 和 Claude API 中使用,Haiku 也將于不久后推出。亞馬遜云科技也第一時間宣布新模型登陸了 Amazon Bedrock。以下是 Anthropic 發布的官方 demo:
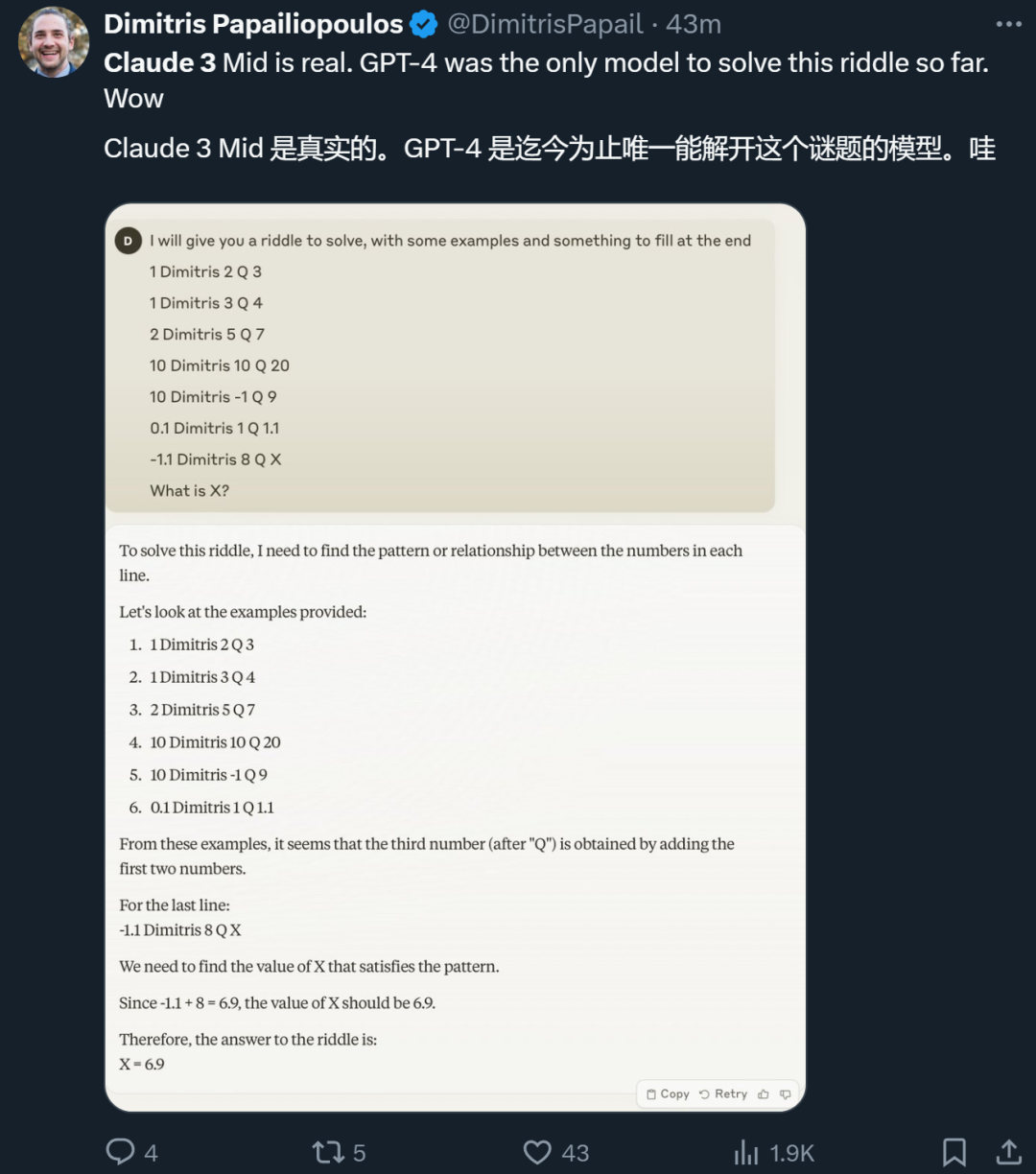
在 Anthropic 官宣之后,不少得到試用機會的研究者也曬出了自己的體驗。有人說,Claude 3 Sonnet 解出了一道此前只有 GPT-4 才能解開的謎題。
不過,也有人表示,在實際體驗方面,Claude 3 并沒有徹底擊敗 GPT-4。
第一手實測Claude3
地址:https://claude.ai/
Claude 3 是否真的像官方所宣稱的那樣,性能全面超越了 GPT-4?目前大多數人認為,確實有那么點意思。
以下是部分實測效果:
首先來一個腦筋急轉彎,哪一個月有二十八天?實際正確答案是每個月都有。看來 Claude 3 還不擅長做這種題。

接著我們又測試了一下 Claude 3 比較擅長的領域,從官方介紹可以看出 Claude 擅長「理解和處理圖像」,包括從圖像中提取文本、將 UI 轉換為前端代碼、理解復雜的方程、轉錄手寫筆記等。
對于大模型來說,經常分不清炸雞和泰迪,當我們輸入一張含有泰迪和炸雞的圖片時,Claude 3 給出了這樣的答案「這張圖片是一組拼貼畫,包含狗和炸雞塊或雞塊,它們與狗本身有著驚人的相似之處……」,這一題算過關。

接著問它里面有幾個人,Claude 3 也回答正確,「這幅動畫描繪了七個小卡通人物。」

Claude 3 可以從照片中提取文本,即使是中文、日文的豎行順序也可以正確識別:

如果我用網上的梗圖,它又要如何應對?有關視覺誤差的圖片,GPT-4 和 Claude3 給出了相反的猜測:
哪種是對的呢?
除了理解圖像外,Claude 處理長文本的能力也比較強,此次發布的全系列大模型可提供 200k 上下文窗口,并接受超過 100 萬 token 輸入。
效果如何呢?我們丟給它微軟、國科大新出不久的論文《 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits 》,讓它按照 1、2、3 的方式總結文章要點,我們記錄了一下時間,輸出整體答案的時間大概有 15 秒左右。
不過這只是 Claude 3 Sonnet 的輸出效果,假如使用 Claude Pro 版本的話,速度會更快,不過要 20 美元一個月。
值得注意的是,現在 Claude 要求上傳的文章大小不超過 10MB,超過會有提示:

在 Claude 3 的博客中,Anthropic 提出新模型的代碼能力有大幅提升,有人直接拿基礎 ASCII 碼丟給 Claude,結果發現它毫無壓力:
我們應該可以確認,Claude 3 有比 GPT-4 更強的代碼能力。
前段時間,剛剛從 OpenAI 離職的 Karpathy 提出過一個「分詞器」挑戰。具體來說,就是將他錄制的 2 小時 13 分的教程視頻放進 LLM,讓其翻譯為關于分詞器的書籍章節或博客文章的格式。
面對這項任務,Claude 3 接住了,以下是 AnthropicAI 研究工程師 Emmanuel Ameisen 曬出的結果:
 圖
圖

或許是不再利益相關,Karpathy 給出了比較充分、客觀的評價:
從風格上看,確實相當不錯!如果仔細觀察,會發現一些微妙的問題 / 幻覺。不管怎么說,這個幾乎現成就能使用的系統還是令人印象深刻的。我很期待能多玩 Claude 3,它看起來是一個強大的模型。
如果說有什么相關的事情我必須說出來的話,那就是人們在進行評估比較時應該格外小心,這不僅是因為評估結果本身比你想象的要糟糕,還因為許多評估結果都以未定義的方式被過擬合了,還因為所做的比較可能是誤導性的。GPT-4 的編碼率(HumanEval)不是 67%。每當我看到這種比較被用來代替編碼性能時,我的眼角就會開始抽搐。
根據以上各種刁鉆的測試結果,有人已經喊出「Anthropic is so back」了。
最后,anthropic 還推出了一個包含多個方向提示內容的 prompt 庫。如果你想要深入了解 Claude 3 的新功能,可以嘗試一下。
鏈接:https://docs.anthropic.com/claude/prompt-library
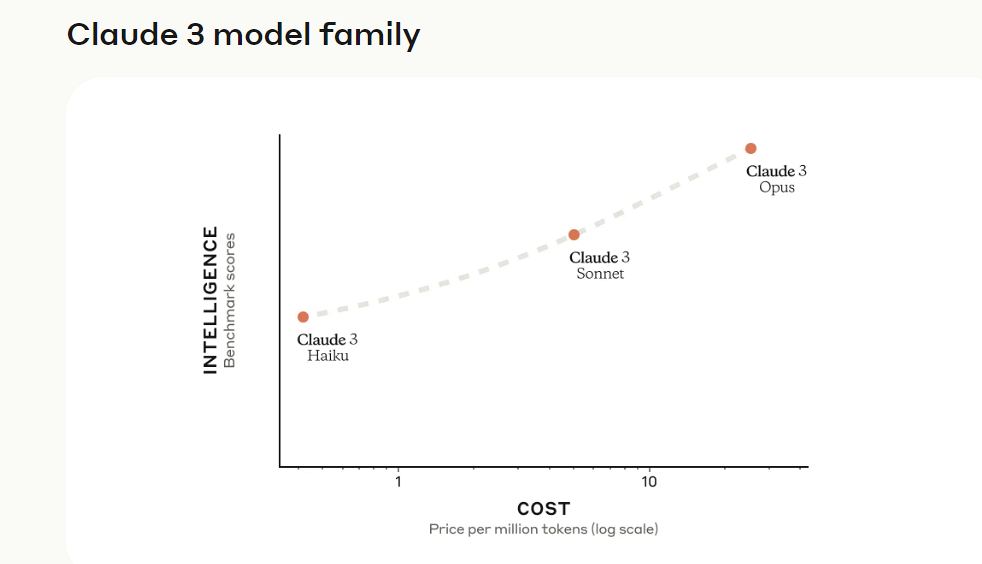
Claude 3 系列模型
Claude 3 系列模型的三個版本分別是 Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku。
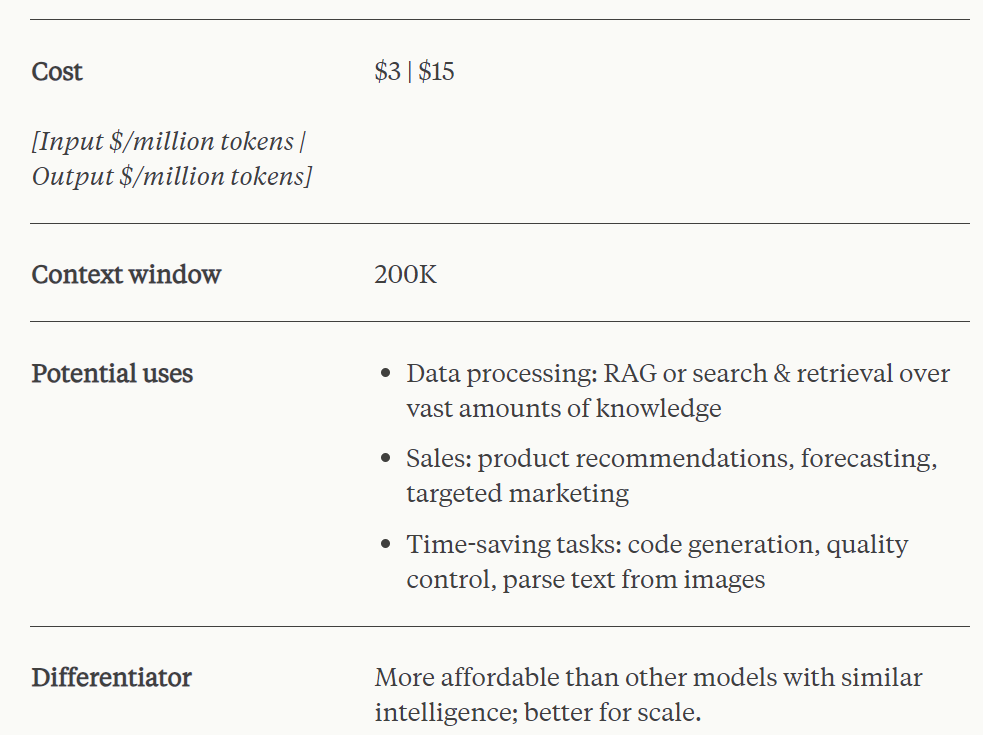
其中 Claude 3 Opus 是智能程度最高的模型,支持 200k tokens 上下文窗口,在高度復雜的任務上實現了當前 SOTA 的性能。該模型能夠以絕佳的流暢度和人類水平的理解能力來處理開放式 prompt 和未見過的場景。Claude 3 Opus 向我們展示了生成式 AI 可能達到的極限。

Claude 3 Sonnet 在智能程度與運行速度之間實現了理想的平衡,尤其是對于企業工作負載而言。與同類模型相比,它以更低的成本提供了強大的性能,并專為大規模 AI 部署中的高耐用性而設計。Claude 3 Sonnet 支持的上下文窗口為 200k tokens。
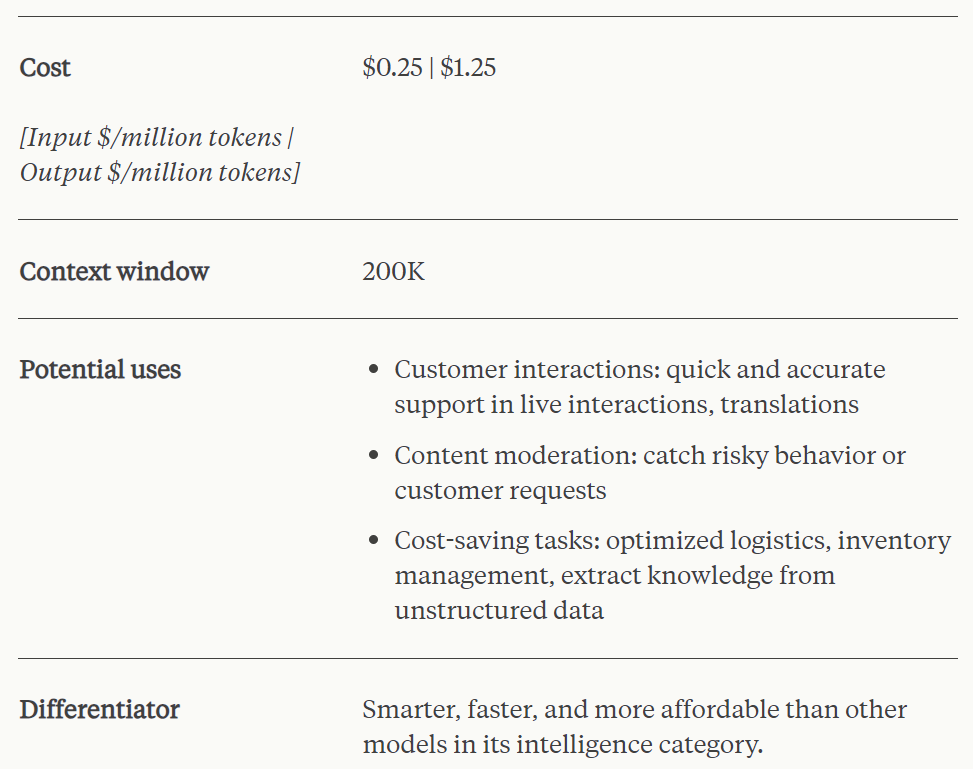
Claude 3 Haiku 是速度最快、最緊湊的模型,具有近乎實時的響應能力。有趣的是,它支持的上下文窗口同樣是 200k。該模型能夠以無與倫比的速度回答簡單的查詢和請求,用戶通過它可以構建模仿人類交互的無縫 AI 體驗。
接下來我們詳看一下 Claude 3 系列模型的特性和性能表現。
全面超越 GPT-4,實現智能水平新 SOTA
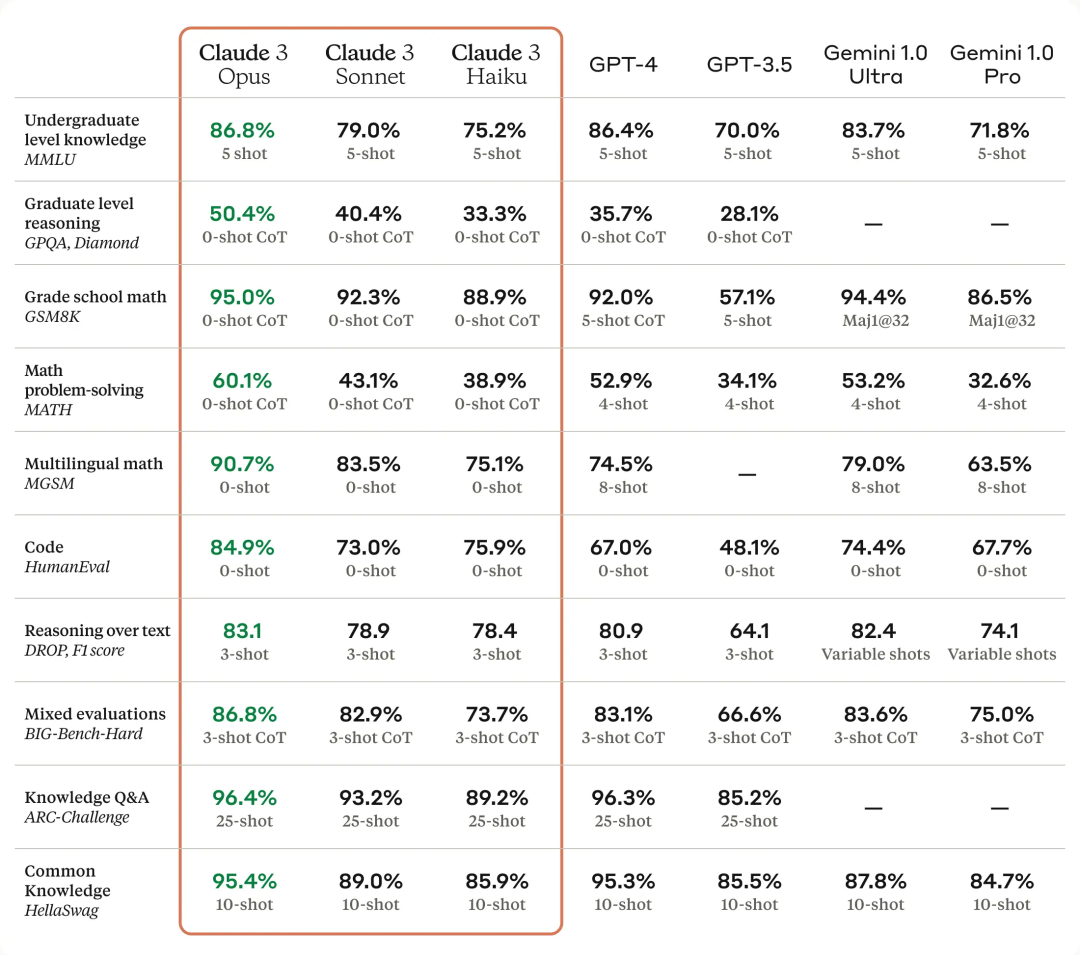
作為 Claude 3 系列中智能水平最高的模型,Opus 在 AI 系統的大多數評估基準上都優于競品,包括本科水平專家知識(MMLU)、研究生水平專家推理(GPQA) 、基礎數學(GSM8K)等基準。并且,Opus 在復雜任務上表現出接近人類水平的理解力和流暢度,引領通用智能的前沿。
此外,包括 Opus 在內,所有 Claude 3 系列模型都在分析和預測、細致內容創建、代碼生成以及西班牙語、日語和法語等非英語語言對話方面實現了能力增強。
下圖為 Claude 3 模型與競品模型在多個性能基準上的比較,可以看到,最強的 Opus 全面優于 OpenAI 的 GPT-4。
近乎實時響應
Claude 3 模型可以支持實時客戶聊天、自動補充和數據提取等響應必須立即且實時的任務。
Haiku 是智能類別市場上速度最快且最具成本效益的型號。它可以在不到三秒的時間內讀完一篇包含密集圖表和圖形信息的 arXiv 平臺論文(約 10k tokens)。
對于絕大多數工作,Sonnet 的速度比 Claude 2 和 Claude 2.1 快 2 倍,且智能水平更高。它擅長執行需要快速響應的任務,例如知識檢索或銷售自動化。Opus 的速度與 Claude 2 和 2.1 相似,但智能水平更高。
強大的視覺能力
Claude 3 具有與其他頭部模型相當的復雜視覺功能。它們可以處理各種視覺格式數據,包括照片、圖表、圖形和技術圖表。
Anthropic 表示,它們的一些客戶 50% 以上的知識庫以各種數據格式進行編程,例如 PDF、流程圖或演示幻燈片。因此,新模型強大的視覺能力非常有幫助。

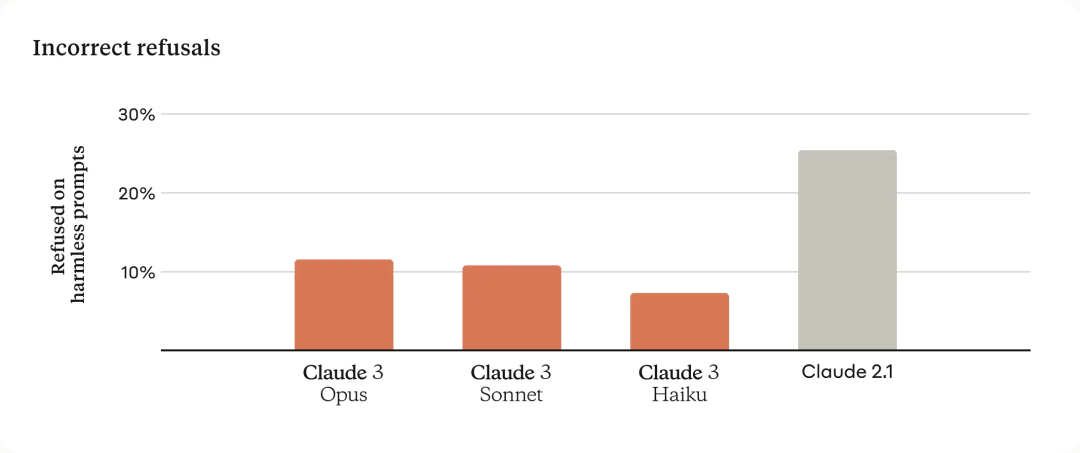
更少拒絕回復
以前的 Claude 模型經常做出不必要的拒絕,這表明模型缺乏語境理解。Anthropic 在這一領域取得了有意義的進展:與前幾代模型相比,即使用戶 prompt 接近系統底線,Opus、Sonnet 和 Haiku 拒絕回答的可能性明顯降低。如下所示,Claude 3 模型對請求表現出更細致的理解,能夠識別真正的有害 prompt,并且拒絕回答無害 prompt 的頻率要少得多。
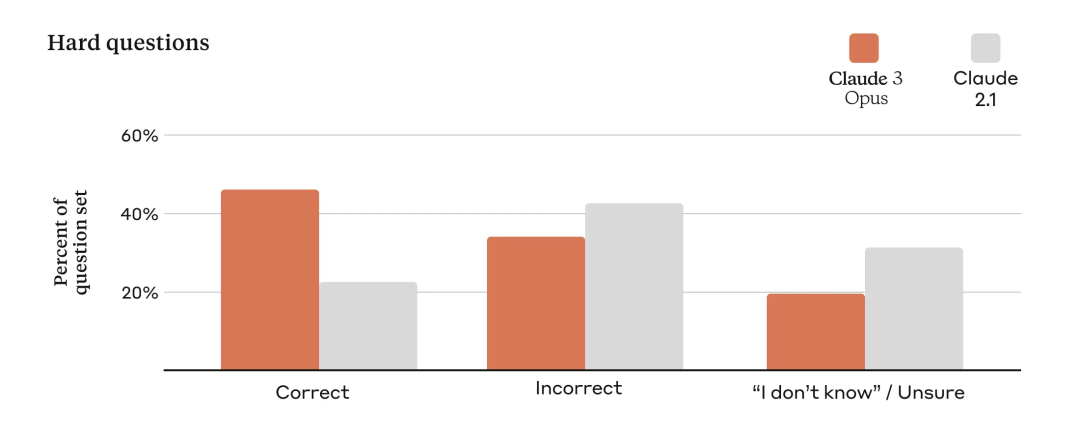
準確率提高
為了評估模型的準確率,Anthropic 使用了大量復雜的、事實性問題來解決當前模型中的已知弱點。Anthropic 將答案分為正確答案、錯誤答案(或幻覺)和不確定性回答,也就是模型不知道答案,而不是提供不正確的信息。與 Claude 2.1 相比,Opus 在這些具有挑戰性的開放式問題上的準確性(或正確答案)提高了一倍,同時也減少了錯誤回答。
除了產生更值得信賴的回復之外,Anthropic 還將在 Claude 3 模型中啟用引用,以便模型可以指向參考材料中的精確句子來證實回答。
長上下文和近乎完美的召回能力
Claude 3 系列型號在發布時最初將提供 200K 上下文窗口。然而,官方表示所有三種模型都能夠接收超過 100 萬 token 的輸入,此能力會被提供給需要增強處理能力的特定用戶。
為了有效地處理長上下文提示,模型需要強大的召回能力。Needle In A Haystack(NIAH)評估衡量模型可以從大量數據中準確回憶信息的能力。Anthropic 通過在每個提示中使用 30 個隨機 Needle/question 對在不同的眾包文檔庫上進行測試,增強了該基準的穩健性。Claude 3 Opus 不僅實現了近乎完美的召回率,超過 99% 的準確率。而且在某些情況下,它甚至識別出了評估本身的局限性,意識到「針」句子似乎是人為插入到原始文本中的。

安全易用
Anthropic 表示,其已建立專門團隊來跟蹤和減少安全風險。該公司也在開發 Constitutional AI 等方法來提高模型的安全性和透明度,并減輕新模式可能引發的隱私問題。
雖然與之前的模型相比,Claude 3 模型系列在生物知識、網絡相關知識和自主性的關鍵指標方面取得了進步,但根據研究,新模型處于 AI 安全級別 2(ASL-2)以內。
在使用體驗上,Claude 3 比以往模型更加擅長遵循復雜的多步驟指令,更加可以遵守品牌和響應準則,從而可以更好地開發可信賴的應用。此外,Anthropic 表示 Claude 3 模型現在更擅長以 JSON 等格式生成流行的結構化輸出,從而可以更輕松地指導 Claude 進行自然語言分類和情感分析等用例。
技術報告里寫了什么
目前,Anthropic 已經放出了 42 頁的技術報告《The Claude 3 Model Family: Opus, Sonnet, Haiku》。

報告地址:https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
我們看到了 Claude 3 系列模型的訓練數據、評估標準以及更詳細的實驗結果。
在訓練數據方面,Claude 3 系列模型接受了截至 2023 年 8 月互聯網公開可用的專用混合數據的訓練,以及來自第三方的非公開數據、數據標簽服務商和付費承包商提供的數據、Claude 內部的數據。
Claude 3 系列模型在以下多個指標上接受了廣泛的評估,包括:
- 推理能力
- 多語言能力
- 長上下文
- 可靠性 / 事實性
- 多模態能力
首先是推理、編程和問答任務上的評估結果,Claude 3 系列模型在一系列推理、閱讀理解、數學、科學和編程的行業標準基準上與競品模型展開了比較,結果顯示不僅超越了自家以往模型,還在大多數情況下實現了新 SOTA。

Anthropic 在法學院入學考試 (LSAT) 、多州律師考試 (MBE)、美國數學競賽 2023 年數學競賽和研究生入學考試 (GRE) 普通考試中評估了 Claude 3 系列模型,具體結果如下表 2 所示。

Claude 3 系列模型具備多模態(圖像和視頻幀輸入)能力,并且在解決超越簡單文本理解的復雜多模態推理挑戰方面取得了重大進展。
一個典型的例子是 Claude 3 模型在 AI2D 科學圖表基準上的表現,這是一種視覺問答評估,涉及圖表解析并以多項選擇格式回答相應的問題。
Claude 3 Sonnet 在 0-shot 設置中達到了 SOTA 水平 —— 89.2%,其次是 Claude 3 Opus(88.3%)和 Claude 3 Haiku(80.6%),具體結果如下表 3 所示。

針對這份技術報告,愛丁堡大學博士生符堯在第一時間給出了自己的分析。
首先,在他看來,被評估的幾個模型在 MMLU / GSM8K / HumanEval 等幾項指標上基本沒有區分度,真正需要關心的是為什么最好的模型在 GSM8K 上依然有 5% 的錯誤。
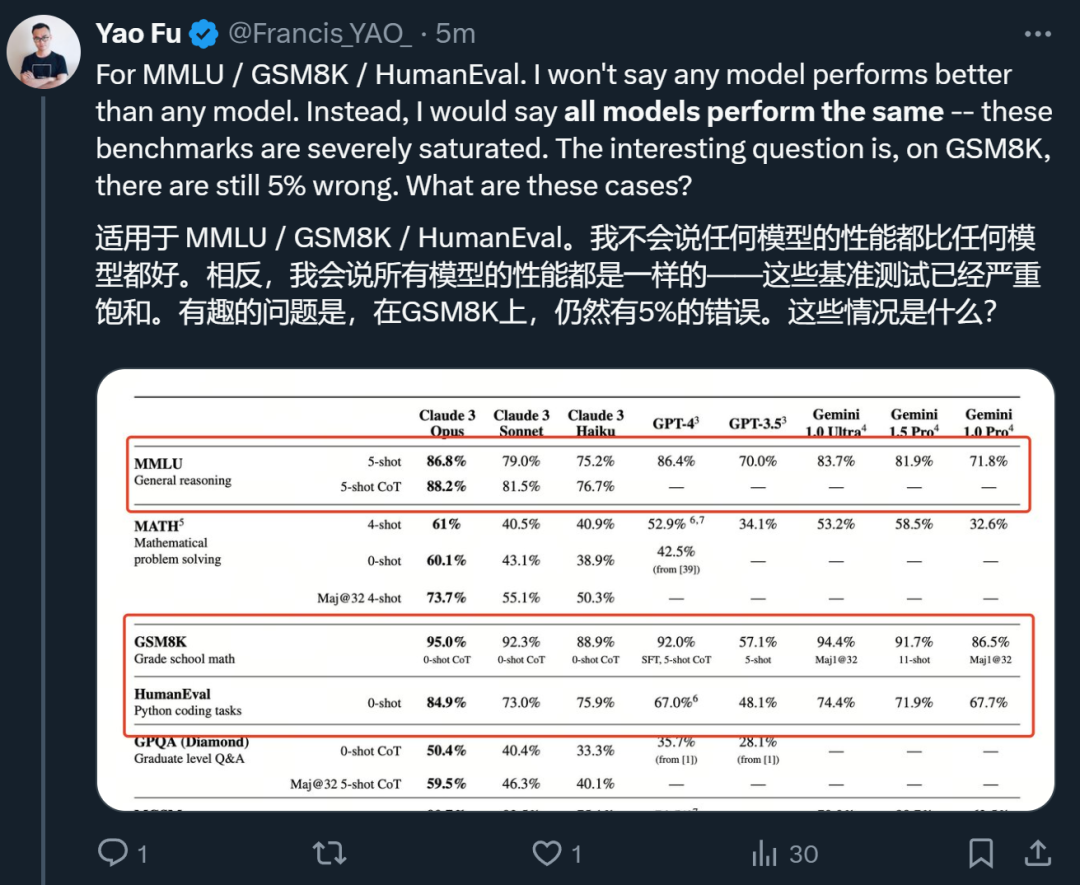
他認為,真正能夠把模型區分開的是 MATH 和 GPQA,這些超級棘手的問題是 AI 模型下一步應該瞄準的目標。
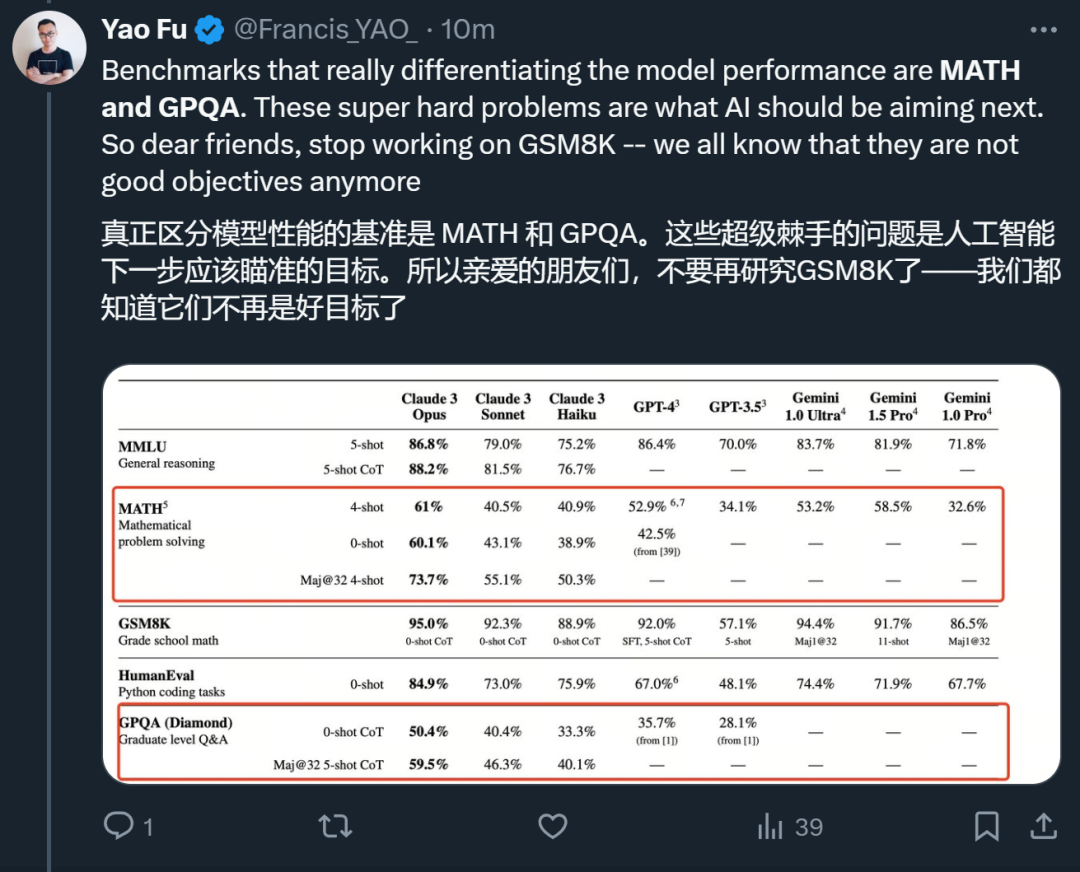
與 Claude 之前的模型相比,改進比較大的領域是金融和醫學。

視覺方面,Claude 3 表現出的視覺 OCR 能力讓人看到了它在數據收集方面的巨大潛力。
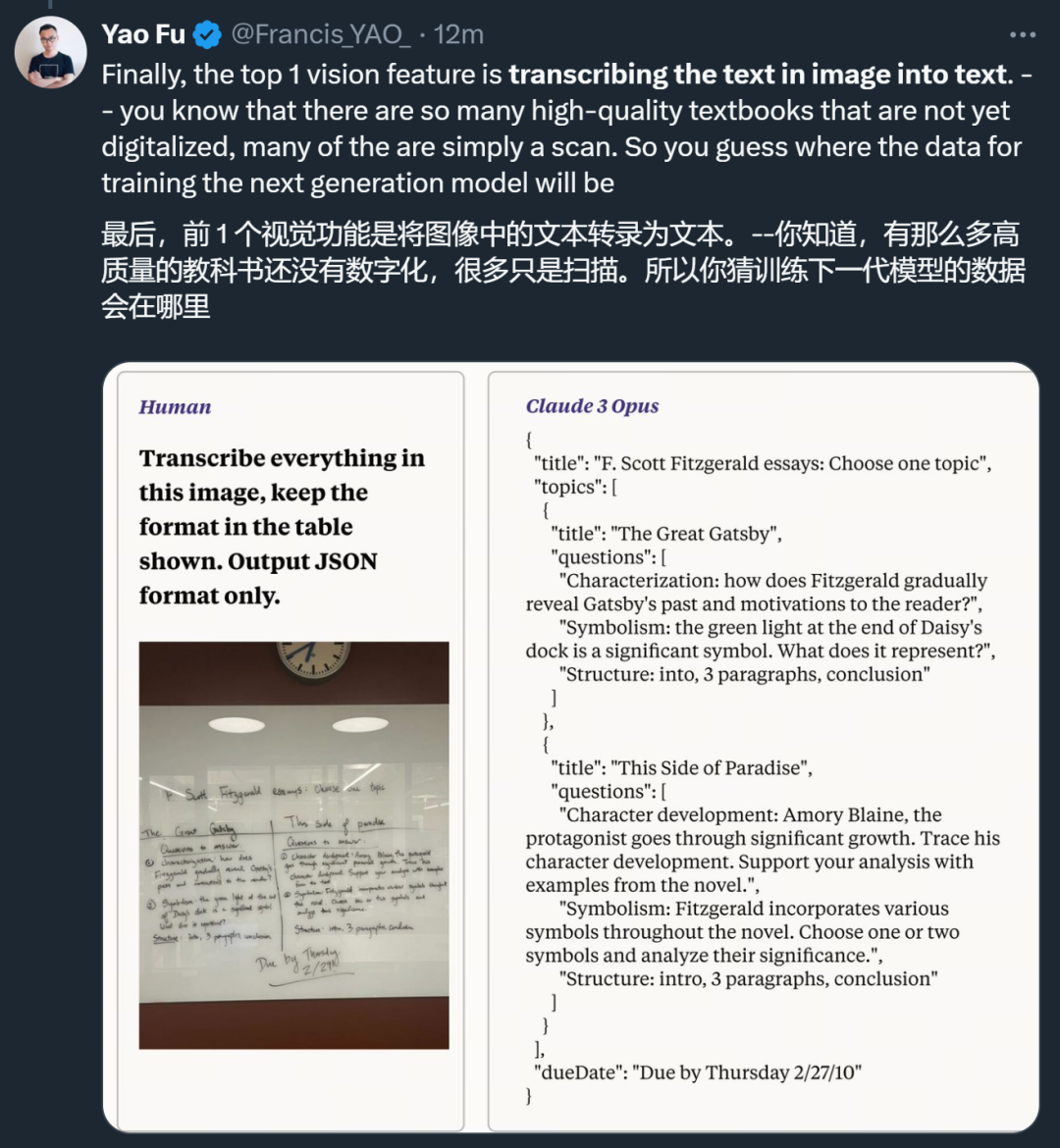
此外,他還發現了其他一些趨勢:


從目前的評測基準和體驗看來,Claude 3 在智能水平、多模態能力和速度上都取得了長足的進步。隨著新系列模型的進一步優化和應用,我們或許將看到更加多元化的大模型生態。
博客地址:https://www.anthropic.com/news/claude-3-family






























