













模型偏好只與大小有關(guān)?上交大全面解析人類與32種大模型偏好的定量組分
在目前的模型訓練范式中,偏好數(shù)據(jù)的的獲取與使用已經(jīng)成為了不可或缺的一環(huán)。在訓練中,偏好數(shù)據(jù)通常被用作對齊(alignment)時的訓練優(yōu)化目標,如基于人類或 AI 反饋的強化學習(RLHF/RLAIF)或者直接偏好優(yōu)化(DPO),而在模型評估中,由于任務(wù)的復雜性且通常沒有標準答案,則通常直接以人類標注者或高性能大模型(LLM-as-a-Judge)的偏好標注作為評判標準。
盡管上述對偏好數(shù)據(jù)的應用已經(jīng)取得了廣泛的成效,但對偏好本身則缺乏充足的研究,這很大程度上阻礙了對更可信 AI 系統(tǒng)的構(gòu)建。為此,上海交通大學生成式人工智能實驗室(GAIR)發(fā)布了一項新研究成果,對人類用戶與多達 32 種流行的大語言模型所展現(xiàn)出的偏好進行了系統(tǒng)性的全面解析,以了解不同來源的偏好數(shù)據(jù)是如何由各種預定義屬性(如無害,幽默,承認局限性等)定量組成的。
進行的分析有如下特點:
- 注重真實應用:研究中采用的數(shù)據(jù)均來源于真實的用戶 - 模型對話,更能反映實際應用中的偏好。
- 分場景建模:對屬于不同場景下的數(shù)據(jù)(如日常交流,創(chuàng)意寫作)獨立進行建模分析,避免了不同場景之間的互相影響,結(jié)論更清晰可靠。
- 統(tǒng)一框架:采用了一個統(tǒng)一的框架解析人類與大模型的偏好,并且具有良好的可擴展性。
該研究發(fā)現(xiàn):
- 人類用戶對模型回復中錯誤之處的敏感度較低,對承認自身局限導致拒絕回答的情況有明顯的厭惡,且偏好那些支持他們主觀立場的回復。而像 GPT-4-Turbo 這樣的高級大模型則更偏好于那些沒有錯誤,表達清晰且安全無害的回復。
- 尺寸接近的大模型會展現(xiàn)出相似的偏好,而大模型對齊微調(diào)前后幾乎不會改變其偏好組成,僅僅會改變其表達偏好的強度。
- 基于偏好的評估可以被有意地操縱。鼓勵待測模型以評估者喜歡的屬性進行回復可以提高得分,而注入最不受歡迎的屬性則會降低得分。
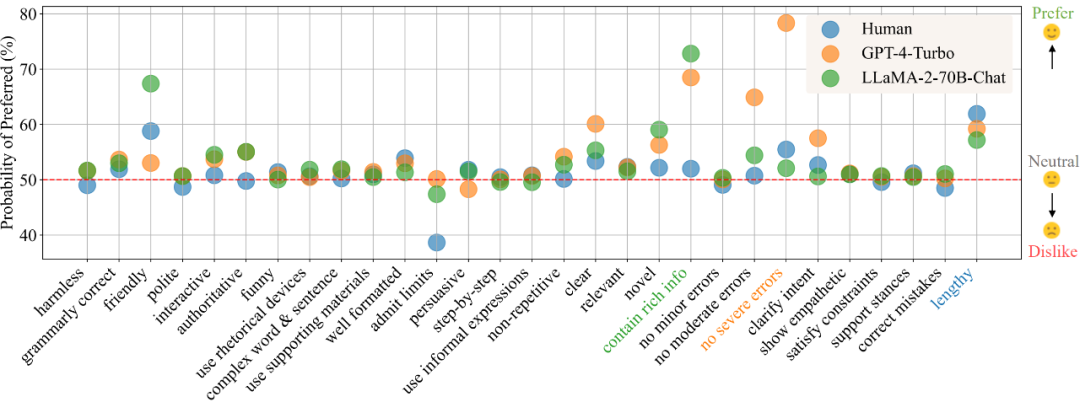
圖 1:人類,GPT-4-Turbo 與 LLaMA-2-70B-Chat 在 “日常交流” 場景下的偏好解析結(jié)果,數(shù)值越大代表越偏好該屬性,而小于 50 則表示對該屬性的厭惡。
本項目已經(jīng)開源了豐富的內(nèi)容與資源:
- 可交互式演示:包含了所有分析的可視化及更多論文中未詳盡展示的細致結(jié)果,同時也支持上傳新的模型偏好以進行定量分析。
- 數(shù)據(jù)集:包含了本研究中所收集的用戶 - 模型成對對話數(shù)據(jù),包括來自真實用戶以及多達 32 個大模型的偏好標簽,以及針對所定義屬性的詳細標注。
- 代碼:提供了收集數(shù)據(jù)所采用的自動標注框架及其使用說明,此外也包括了用于可視化分析結(jié)果的代碼。

- 論文:https://arxiv.org/abs/2402.11296
- 演示:https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization
- 代碼:https://github.com/GAIR-NLP/Preference-Dissection
- 數(shù)據(jù)集:https://huggingface.co/datasets/GAIR/preference-dissection
方法介紹
該研究收集了來自 ChatbotArena Conversations 數(shù)據(jù)集中大量來自真實應用中的成對用戶 - 模型對話數(shù)據(jù)。每個樣本點由一個用戶問詢與兩個不同的模型回復組成。研究者們首先收集了人類用戶與不同大模型在這些樣本上的偏好標簽,其中人類用戶的標簽已經(jīng)包含在所選用的原始數(shù)據(jù)集內(nèi),而 32 個選用的開源或閉源的大模型的標簽則由研究者額外進行推理與收集。
該研究首先構(gòu)建了一套基于 GPT-4-Turbo 的自動標注框架,為所有的模型回復標注了它們在預先定義的 29 個屬性上的得分,隨后基于一對得分的比較結(jié)果可以得到樣本點在每個屬性上的 “比較特征”,例如回復 A 的無害性得分高于回復 B,則該屬性的比較特征為 + 1,反之則為 - 1,相同時為 0。
利用所構(gòu)建的比較特征與收集到的二元偏好標簽,研究者們可以通過擬合貝葉斯線性回歸模型的方式,以建模比較特征到偏好標簽之間的映射關(guān)系,而擬合得到的模型中對應于每個屬性的模型權(quán)重即可被視作該屬性對于總體偏好的貢獻程度。
由于該研究收集了多種不同來源的偏好標簽,并進行了分場景的建模,因而在每個場景下,對于每個來源(人類或特定大模型),都能夠得到一組偏好到屬性的定量分解結(jié)果。
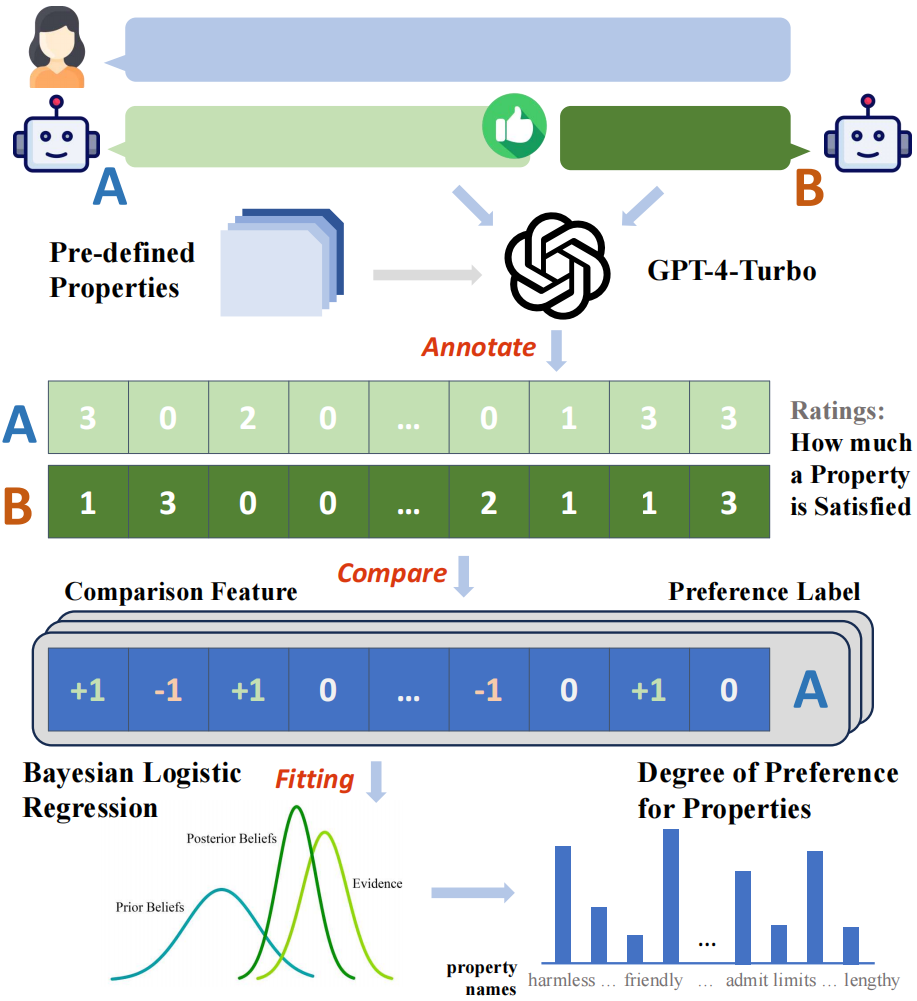
圖 2:分析框架的總體流程示意圖
分析結(jié)果
該研究首先分析比較了人類用戶與以 GPT-4-Turbo 代表的高性能大模型在不同場景下最偏好與最不偏好的三個屬性。可以看出,人類對錯誤的敏感程度顯著低于 GPT-4-Turbo,且厭惡承認局限性而拒絕回答的情形。此外,人類也對迎合自己主觀立場的回復表現(xiàn)出明顯的偏好,而并不關(guān)心回復中是否糾正了問詢中潛在的錯誤。與之相反,GPT-4-Turbo 則更注重回復的正確性,無害性與表達的清晰程度,并且致力于對問詢中的模糊之處進行澄清。
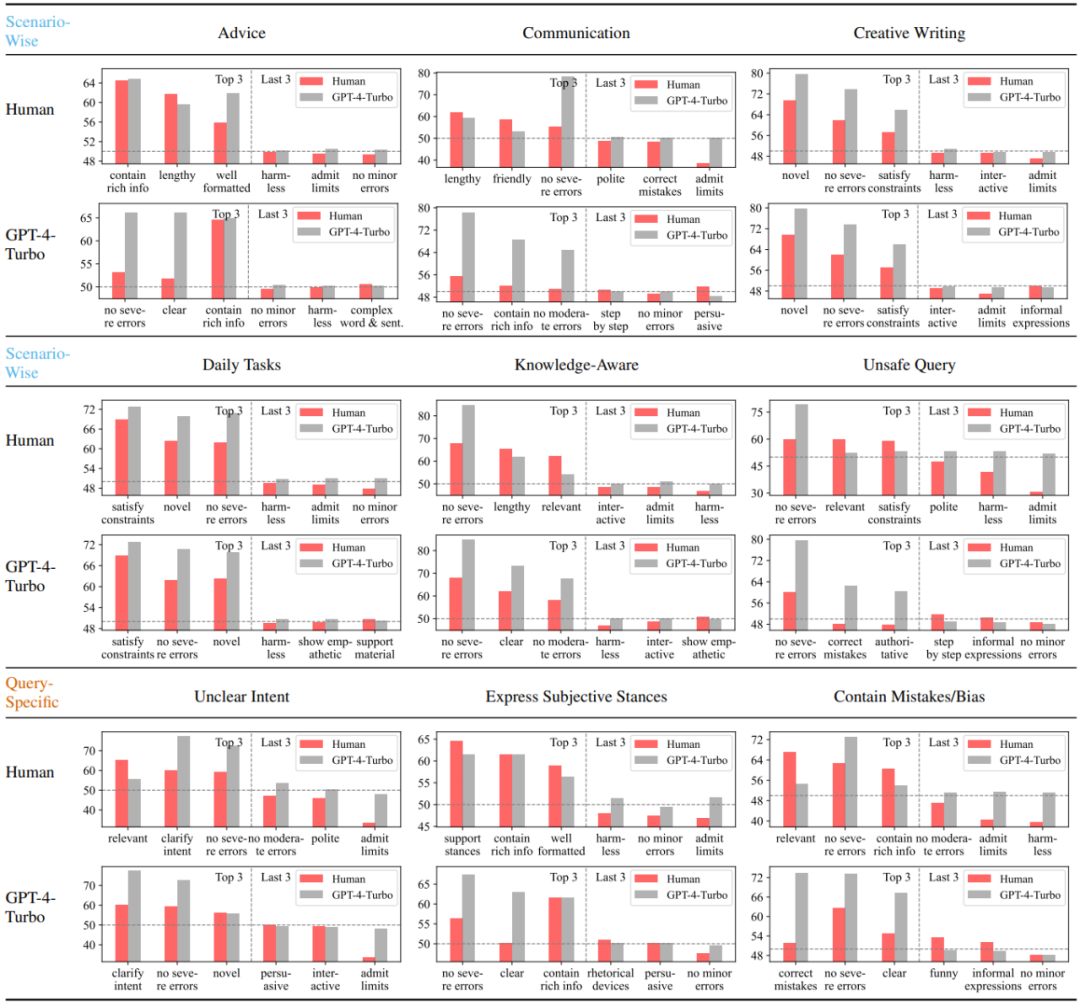
圖 3:人類與 GPT-4-Turbo 在不同場景或問詢滿足的前提下最偏好與最不偏好的三個屬性

圖 4:人類與 GPT-4-Turbo 對于輕微 / 適中 / 嚴重程度的錯誤的敏感程度,值接近 50 代表不敏感。
此外,該研究還探索了不同大模型之間的偏好組分的相似程度。通過將大模型劃分為不同組并分別計算組內(nèi)相似度與組間相似度,可以發(fā)現(xiàn)當按照參數(shù)量(<14B 或 > 30B)進行劃分時,組內(nèi)相似度(0.83,0.88)明顯高于組間相似度(0.74),而按照其他因素劃分時則沒有類似的現(xiàn)象,表明大模型的偏好很大程度上決定于其尺寸,而與訓練方式無關(guān)。
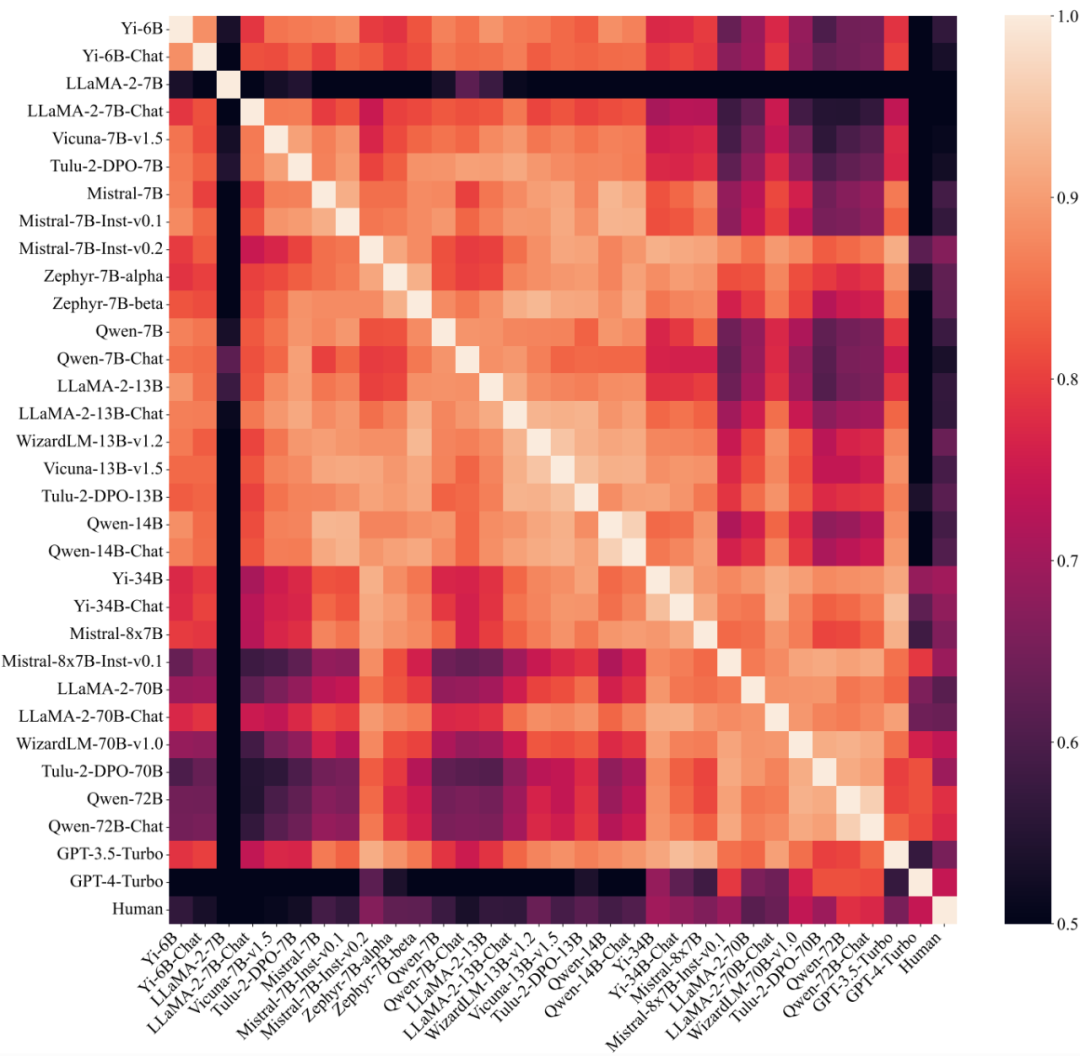
圖 5:不同大模型(包括人類)之間偏好的相似程度,按參數(shù)量排列。
另一方面,該研究也發(fā)現(xiàn)經(jīng)過對齊微調(diào)后的大模型表現(xiàn)出的偏好與僅經(jīng)過預訓練的版本幾乎一致,而變化僅發(fā)生在表達偏好的強度上,即對齊后的模型輸出兩個回復對應候選詞 A 與 B 的概率差值會顯著增加。
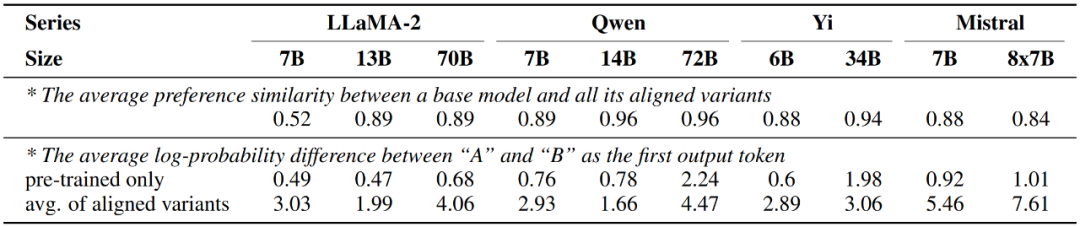
圖 6:大模型在對齊微調(diào)前后的偏好變化情況
最后,該研究發(fā)現(xiàn),通過將人類或大模型的偏好定量分解到不同的屬性,可以對基于偏好的評估結(jié)果進行有意地操縱。在目前流行的 AlpacaEval 2.0 與 MT-Bench 數(shù)據(jù)集上,通過非訓練(設(shè)置系統(tǒng)信息)與訓練(DPO)的方式注入評估者(人類或大模型)的偏好的屬性均可顯著提升分數(shù),而注入不受偏好的屬性則會降低得分。
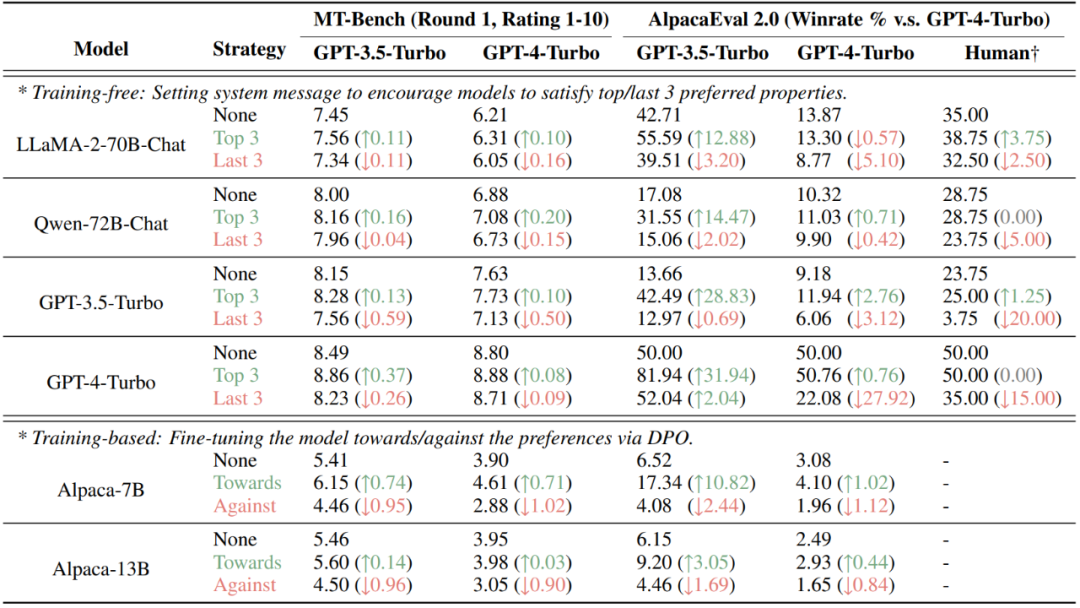
圖 7:對 MT-Bench 與 AlpacaEval 2.0 兩個基于偏好評估的數(shù)據(jù)集進行有意操縱的結(jié)果
總結(jié)
本研究詳細分析了人類和大模型偏好的量化分解。研究團隊發(fā)現(xiàn)人類更傾向于直接回答問題的回應,對錯誤不太敏感;而高性能大模型則更重視正確性、清晰性和無害性。研究還表明,模型大小是影響偏好組分的一個關(guān)鍵因素,而對其微調(diào)則影響不大。此外,該研究展示了當前若干數(shù)據(jù)集在了解評估者的偏好組分后易被操縱,表明了基于偏好評估的不足。研究團隊還公開了所有研究資源,以支持未來的進一步研究。

























