ControlNet作者又出新作:百萬數據訓練,AI圖像生成迎來圖層設計
盡管用于生成圖像的大模型已經成為計算機視覺和圖形學的基礎,但令人驚訝的是,分層內容生成或透明圖像(是指圖像的某些部分是透明的,允許背景或者其他圖層的圖像通過這些透明部分顯示出來)生成領域獲得的關注極少。這與市場的實際需求形成了鮮明對比。大多數視覺內容編輯軟件和工作流程都是基于層的,嚴重依賴透明或分層元素來組合和創建內容。
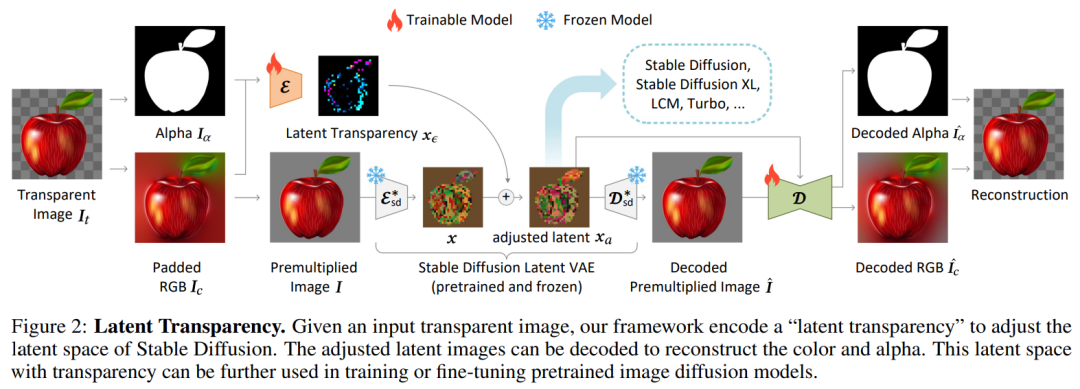
來自斯坦福大學的研究者提出了一種「latent transparency(潛在透明度)」方法,使得經過大規模預訓練的潛在擴散模型能夠生成透明圖像以及多個透明圖層。

- 論文地址:https://arxiv.org/pdf/2402.17113.pdf
- 論文標題:Transparent Image Layer Diffusion using Latent Transparency
舉例來說,對于給定的文本提示(如頭發凌亂的女人,在臥室里),該研究提出的方法能夠生成具有透明度的多個圖層。也就是說該模型不僅能根據提示生成圖片,還能將前景和背景進行分層,背景丟失的信息也能很好的補充。

此外,本文還采用人機交互的方式來訓練模型框架并同時收集數據,最終數據集的規模達到 100 萬張透明圖像,涵蓋多種內容主題和風格。然后,該研究將數據集擴展到多圖層樣本。該數據集不僅可以訓練透明圖像生成器,還可以用于不同的應用,例如背景 / 前景條件生成、結構引導生成、風格遷移等。
實驗表明,在絕大多數情況下 (97%),用戶更喜歡由本文方法生成的透明內容,而不是以前的解決方案(例如先生成然后摳圖)。當研究者將生成的質量與 Adobe Stock 等商業網站的搜索結果進行比較時,也取得了不錯的成績。
這項研究作者共有兩位 Lvmin Zhang 以及 Maneesh Agrawala ,其中 Lvmin Zhang 還是 ContorlNet 的作者。
有網友表示:「能生成透明圖層的意義絕不僅僅是摳圖。這是現在動畫、視頻制作最核心的工序之一。這一步能夠過,可以說 SD 一致性就不再是問題了。」

方法介紹
本文的目標是為像 Stable Diffusion (SD) 這樣的大規模潛在擴散模型添加透明度支持,這些模型通常使用一個潛在編碼器(VAE)將 RGB 圖像轉換為潛在圖像,然后再將其輸入到擴散模型中。在此過程中,VAE 和擴散模型應共享相同的潛在分布,因為任何重大不匹配都可能顯著降低潛在擴散框架的推理 / 訓練 / 微調性能。
潛在透明度:當調整潛在空間以支持透明度時,必須盡可能保留原始的潛在分布。這個看似不明確的目標可以通過一個直接的測量來確定:可以檢查修改后的潛在分布被原始預訓練的凍結潛在解碼器解碼的如何 —— 如果解碼修改后的潛在圖像創建了嚴重的人工痕跡,那么潛在分布就是不對齊或損壞的。這一過程可視化結果如下圖所示:
生成多個圖層:該研究進一步使用注意力共享和 LoRA 將基礎模型擴展為多圖層模型,如圖 3-(b) 所示。圖 3-(a) 為訓練可視化結果。

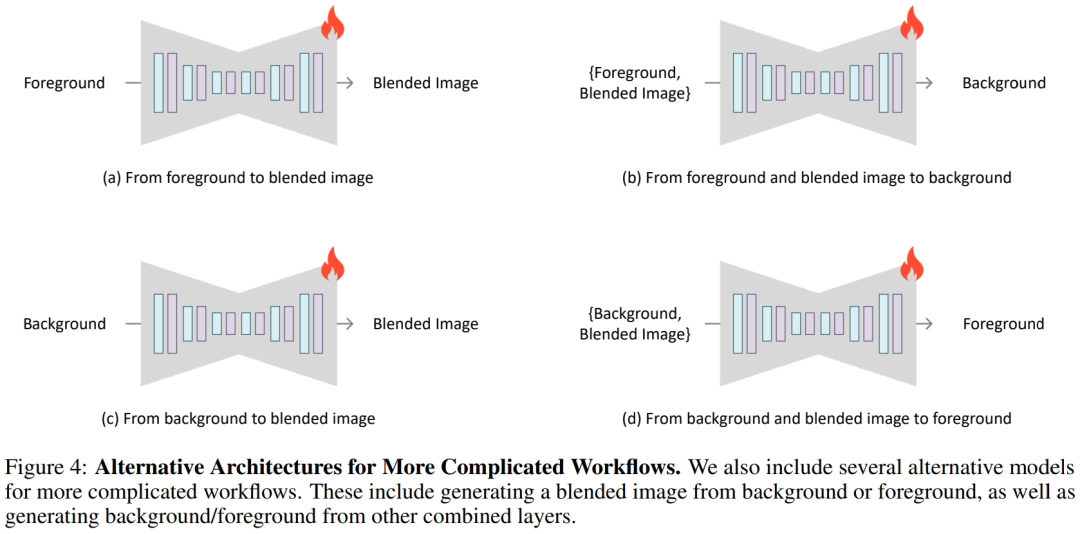
圖 4 引入了幾種替代架構,以實現更復雜的工作流程。研究者可以向 UNet 添加零初始化通道,并使用 VAE(有或沒有潛在透明度)將前景、背景或圖層組合編碼為條件,并訓練模型生成前景或背景(例如,圖 4-( b,d)),或直接生成混合圖像(例如,圖 4-(a,c))。
數據準備及其訓練細節
訓練數據集包括基礎數據集(圖 5-(a))以及多圖層數據集 (5-(b)) 。
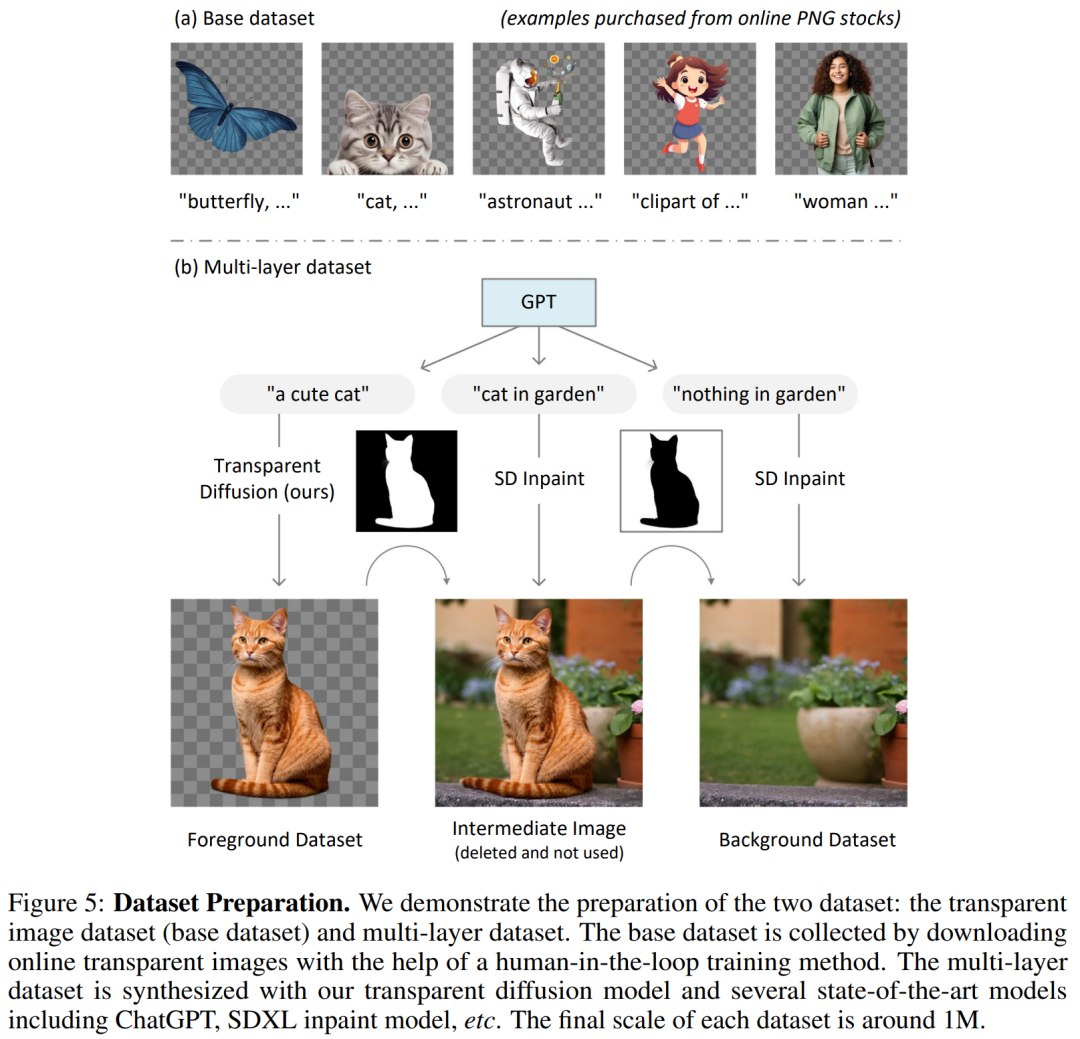
訓練設備為 4 × A100 80G NV-link,整個訓練時間為一周(為了減少預算,在人工收集下一輪優化數據時暫停訓練),實際 GPU 時間約為 350 A100 小時。該方法適合個人規模或實驗室規模的研究,因為 350 個 GPU 小時預算通常在 1K 美元內。
實驗
圖 6 展示了使用單圖像基礎模型生成的圖像定性結果。這些結果展示了該模型可以生成原生透明圖像,如生成高質量的玻璃透明度、頭發、毛發、發光、火焰、魔法等效果。這些結果還證明了該模型可以泛化到不同的場景。

圖 7 展示了使用具有不同主題的提示來生成圖片的定性結果。每個示例會顯示混合圖像和兩個輸出層。這些圖層不僅在照明和幾何關系方面保持一致,而且還展示了穩定擴散的美學品質(例如,背景和前景的顏色選擇,看起來和諧且美觀)。

條件層生成。研究者在圖 8 中展示了條件層生成結果(即以前景為條件的背景生成和以背景為條件的前景生成)。可以看到,本文的模型可以生成具有一致幾何和照明效果的連貫構圖。在「教堂中懸掛的燈泡」示例中,該模型嘗試通過一種對稱性審美設計來匹配前景。而在「坐在長登上或坐在沙發上」示例中,該模型可以推斷前景和背景之間的交互,并生成相應的幾何。

迭代生成。如圖 9 所示,研究者可以迭代使用以背景為條件的前景生成模型,以實現構圖或任意數量的層。對于每個新的層,他們將之前生成的所有層融入到一個 RGB 圖像,并饋入到以背景為條件的前景模型。研究者還觀察到,該模型能夠在背景圖像的上下文中解釋自然語言,比如在一只貓的面前生成一本書。該模型展現了強大的幾何構圖能力,比如生成一個人坐在箱子上的組合圖像。

可控生成。如圖 10 所示,研究者展示了 ControlNet 等現有可控模型可以用于他們的模型,以提供豐富的功能。可以看到,本文的模型可以基于 ControlNet 信號來保留全局結構,以生成具有一致照明效果的和諧構圖。研究者也通過一個「反射球」示例展示了本文的模型可以與前景和背景的內容進行交互,從而生成反光等一致性照明效果。