深入理解Prometheus:Kubernetes監控實戰
一、Prometheus簡介

Prometheus, 作為一個開源系統監控和警報工具包,自從2012年誕生以來,已經成為云原生生態系統中不可或缺的組成部分。
Prometheus的核心概念
Prometheus的設計初衷是為了應對動態的云環境中的監控挑戰。它采用了多維數據模型,其中時間序列數據由metric name和一系列的鍵值對(即標簽)標識。這種設計使得Prometheus非常適合于存儲和查詢大量的監控數據,特別是在微服務架構的環境中。
與傳統監控工具不同,Prometheus采用的是主動拉取(pull)模式來收集監控指標,即定期從配置好的目標(如HTTP端點)拉取數據。這種方式簡化了監控配置,并使得Prometheus能夠更靈活地適應各種服務的變化。
此外,Prometheus的另一個顯著特點是其強大的查詢語言PromQL。PromQL允許用戶通過簡潔的表達式來檢索和處理時間序列數據,支持多種數學運算、聚合操作和時間序列預測等功能。
Prometheus的架構特點
Prometheus的架構設計獨特且具有高度的靈活性。它主要包括以下幾個組件:
- 數據收集組件(Prometheus Server):負責數據的收集、存儲和查詢處理。
- 客戶端庫(Client Libraries):用于各種語言和應用程序,方便集成監控指標。
- 推送網關(Pushgateway):適用于短期作業,可將指標推送至Prometheus。
- 數據可視化組件(如Grafana):與Prometheus集成,用于數據的可視化展示。
Prometheus的存儲機制是另一個亮點。它采用了時間序列數據庫來存儲數據,這種數據庫優化了時間序列數據的讀寫效率。盡管Prometheus提供了一定的持久化機制,但它的主要設計目標還是在于可靠性和實時性,而不是長期數據存儲。
在現代云服務中的作用
Prometheus在微服務架構中尤為重要。隨著容器化和微服務的普及,傳統的監控系統往往難以應對頻繁變化的服務架構和動態的服務發現需求。Prometheus的設計正好適應了這種環境,它能夠有效地監控成千上萬的端點,及時反饋系統狀態,并支持快速的故障檢測和定位。
綜上所述,Prometheus不僅僅是一個監控工具,更是微服務環境中不可或缺的基礎設施組件。通過其高效的數據收集、強大的查詢能力和靈活的架構設計,Prometheus為現代云服務提供了強大的監控和警報能力,成為了云原生生態系統中的一個關鍵角色。
二、Prometheus組成
 圖片
圖片
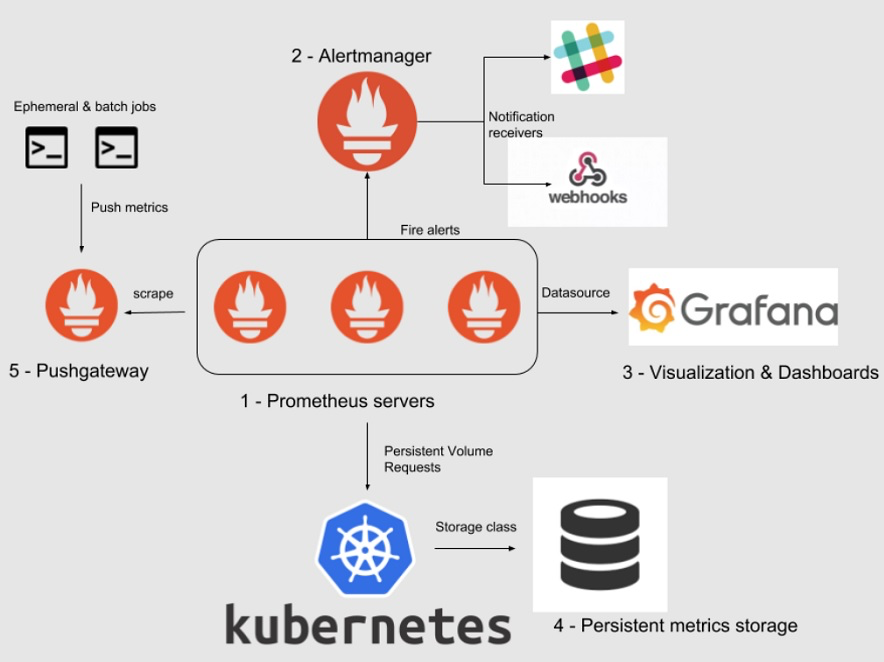
Prometheus架構與組件
Prometheus的架構設計獨特,涵蓋了從數據采集到存儲、查詢及警報的全過程。核心組件包括:
1. Prometheus Server
Prometheus Server是整個架構的核心,它負責數據的收集(通過拉取模式)、存儲和處理時間序列數據。Server內部由幾個關鍵組件構成:
- 數據采集器(Retrieval):負責從配置的目標中拉取監控數據。
- 時間序列數據庫(TSDB):用于存儲拉取的監控數據。
- PromQL引擎:處理所有的查詢請求。
2. 客戶端庫
Prometheus提供了多種語言的客戶端庫,如Go、Java、Python等,允許用戶在自己的服務中導出指標。
3. 推送網關(Pushgateway)
對于那些不適合或不能直接被Prometheus Server拉取數據的場景(如批處理作業),Pushgateway作為一個中間層允許這些作業將數據推送至此。
4. 導出器(Exporters)
對于不能直接提供Prometheus格式指標的服務,Exporters可以用來導出這些服務的指標,例如:Node exporter、MySQL exporter等。
5. Alertmanager
用于處理由Prometheus Server發送的警報,支持多種通知方式,并且可以對警報進行分組、抑制和靜默等處理。
Prometheus的數據模型
Prometheus的數據模型是理解其功能的關鍵。在Prometheus中,所有的監控數據都被存儲為時間序列,每個時間序列都由唯一的metric name和一系列的標簽(鍵值對)來標識。
1. Metric Types
Prometheus支持多種類型的指標,包括:
- Counter:一個累加值,常用于表示請求數、任務完成數等。
- Gauge:可以任意增減的值,常用于表示溫度、內存使用量等。
- Histogram:用于表示觀測值的分布,如請求持續時間。
- Summary:與Histogram類似,但提供更多的統計信息。
2. 時間序列數據
每個時間序列由metric name和一系列標簽唯一確定。標簽使得Prometheus非常適合于處理多維度的監控數據,為用戶提供了豐富的查詢能力。
PromQL:Prometheus查詢語言
PromQL是Prometheus的強大查詢語言,它允許用戶執行復雜的數據查詢和聚合操作。PromQL的關鍵特點包括:
- 支持多種類型的查詢,包括即時查詢、范圍查詢等。
- 支持多種數據聚合操作,如sum、avg、histogram_quantile等。
- 能夠處理不同時間序列之間的數學運算。
PromQL的高級特性使得用戶能夠從龐大的監控數據中提取出有價值的信息,并進行深入的性能分析。
Prometheus的數據采集
Prometheus采用主動拉取(pull)模式來采集監控數據。這意味著Prometheus Server會定期從配置的目標(如HTTP端點)拉取數據。這種方式與傳統的被動推送(push)模式相比,具有以下優勢:
- 簡化了監控配置,因為所有的配置都集中在Prometheus Server端。
- 提高了監控的可靠性,因為Server端可以控制采集頻率和重試邏輯。
Prometheus的存儲機制
Prometheus使用自帶的時間序列數據庫來存儲監控數據。這個數據庫專門為處理時間序列數據而優化,具有高效的數據壓縮和快速的查詢能力。然而,Prometheus的存儲并不適用于長期數據存儲。對于需要長期存儲監控數據的場景,通常需要與其他外部存儲系統(如Thanos或Cortex)集成。
Prometheus的監控和警報
監控和警報是Prometheus的核心功能之一。Prometheus允許用戶定義復雜的警報規則,并在規則被觸發時發送通知。Alertmanager作為警報的管理組件,支持多種通知方式,包括郵件、Webhook、Slack等。
三、Kubernetes與Prometheus的集成
 圖片
圖片
在這一部分中,我們將深入探討如何將Prometheus與Kubernetes(K8s)集成,以便實現對Kubernetes集群的有效監控。我們將從集成的基本概念開始,探索Prometheus在Kubernetes環境中的部署方式,以及如何配置和使用Prometheus來監控Kubernetes集群。
Kubernetes簡介
在深入Prometheus與Kubernetes的集成之前,首先簡要回顧一下Kubernetes的核心概念。Kubernetes是一個開源的容器編排平臺,用于自動化容器的部署、擴展和管理。它提供了高度的可擴展性和靈活性,使得它成為微服務和云原生應用的理想選擇。
核心組件
- 控制平面(Control Plane):集群管理相關的組件,如API服務器、調度器等。
- 工作節點(Nodes):運行應用容器的機器。
- Pods:Kubernetes的基本運行單位,可以容納一個或多個容器。
部署Prometheus到Kubernetes
將Prometheus部署到Kubernetes中,主要涉及到以下幾個步驟:
1. 使用Helm Chart
Helm是Kubernetes的包管理工具,類似于Linux的apt或yum。通過Helm,可以快速部署Prometheus。Prometheus的Helm chart包括了所有必要的Kubernetes資源定義,如Deployments、Services和ConfigMaps。
# 示例:使用Helm部署Prometheus
helm install stable/prometheus --name my-prometheus --namespace monitoring2. 配置服務發現
為了監控Kubernetes集群中的節點和服務,Prometheus需要配置適當的服務發現機制。Kubernetes服務發現使Prometheus能夠自動發現集群中的服務和Pods。
# 示例:Prometheus配置文件中的服務發現部分
scrape_configs:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node3. 設置RBAC規則
由于Prometheus需要訪問Kubernetes API來發現服務,因此需要配置相應的RBAC(基于角色的訪問控制)規則,以賦予Prometheus所需的權限。
# 示例:Kubernetes RBAC配置
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources: ["nodes", "services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]監控Kubernetes集群
一旦Prometheus成功部署到Kubernetes,并配置了服務發現,它就可以開始監控Kubernetes集群了。監控的關鍵點包括:
1. 監控節點和Pods
Prometheus可以收集關于Kubernetes節點和Pods的各種指標,如CPU和內存使用情況、網絡流量等。
2. 監控Kubernetes內部組件
除了標準的節點和Pods監控,Prometheus還可以監控Kubernetes的內部組件,如etcd、API服務器、調度器等。
3. 自定義監控指標
對于Kubernetes中運行的應用,可以通過Prometheus的客戶端庫來導出自定義的監控指標,從而實現對應用的細粒度監控。
Prometheus與Kubernetes的高級集成
隨著集群的增長和應用的復雜化,對監控系統的要求也會隨之提高。Prometheus與Kubernetes的集成可以進一步擴展,以適應更復雜的監控需求。例如,使用Prometheus Operator可以簡化和自動化監控配置的管理。Prometheus Operator定義了一系列自定義資源定義(CRD),如ServiceMonitor,這些CRD可以更為靈活和動態地配置Prometheus監控目標。
配置Prometheus監控Kubernetes
配置Prometheus以監控Kubernetes涉及多個方面,確保監控覆蓋到集群的各個組件,并且能夠提供實時的反饋和預警。
1. 采集Kubernetes指標
Kubernetes暴露了豐富的指標,可以通過Prometheus收集,這些指標包括節點性能、資源使用情況等。配置Prometheus采集這些指標,需要在Prometheus的配置文件中指定Kubernetes的API作為數據源。
# 示例:配置Prometheus采集Kubernetes指標
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod2. 監控Kubernetes API服務器
Kubernetes API服務器是集群的核心,監控其性能和健康狀態對于維護集群穩定性至關重要。通過配置Prometheus,可以收集API服務器的響應時間、請求量等關鍵指標。
3. 使用ServiceMonitor管理監控目標
在使用Prometheus Operator時,ServiceMonitor資源可以用來更加靈活地管理監控目標。通過定義ServiceMonitor,可以自動發現并監控符合特定標簽規則的服務。
# 示例:使用ServiceMonitor定義監控目標
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-service
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: webPrometheus在Kubernetes中的高可用性部署
隨著監控的重要性日益增加,確保Prometheus在Kubernetes中的高可用性(HA)也變得至關重要。
1. 多副本部署
在Kubernetes中部署多個Prometheus副本,可以提高服務的可用性。通過配置StatefulSet和Persistent Volume,可以保證Prometheus的數據持久性和一致性。
2. 負載均衡和服務發現
使用Kubernetes的負載均衡和服務發現機制,可以確保流量在多個Prometheus副本之間正確分配,并保持監控系統的穩定性。
監控Kubernetes集群的最佳實踐
為了最大化Prometheus在Kubernetes中的效能,遵循以下最佳實踐至關重要:
1. 精細化監控指標
選擇適當的指標進行監控,避免數據過載。重點關注那些對系統性能和健康狀況最為關鍵的指標。
2. 利用標簽和注釋
充分利用Kubernetes的標簽和注釋功能,以組織和管理監控目標。這樣可以更容易地過濾和查詢相關指標。
3. 定期審查和調整告警規則
隨著系統的發展和變化,定期審查和調整告警規則是必要的,以確保告警的準確性和及時性。
四、Prometheus監控與告警實戰
在這一部分中,我們將深入探討如何在實際環境中應用Prometheus進行監控和告警,包括設置監控指標、配置告警規則、集成告警通知系統,以及進行監控數據的可視化。
監控策略的設定
有效的監控始于明智地選擇和配置監控指標。在Prometheus中,監控策略的設定包括以下關鍵方面:
1. 確定監控目標
明確監控的關鍵組件,如服務器、數據庫、應用程序等。對于每個組件,確定哪些指標是關鍵的,如CPU使用率、內存占用、網絡流量等。
2. 配置指標收集
使用Prometheus的配置文件或客戶端庫來收集這些關鍵指標。例如,對于一個Web服務,可以收集HTTP請求的數量、響應時間等。
# 示例:配置Prometheus監控Web服務
scrape_configs:
- job_name: 'web-service'
static_configs:
- targets: ['localhost:9090']3. 自定義指標
對于特定的業務邏輯或應用程序性能,可以使用Prometheus的客戶端庫來定義和導出自定義指標。
告警規則的配置
在監控系統中,告警是及時響應問題的關鍵。在Prometheus中,告警規則的配置包括:
1. 定義告警規則
使用PromQL定義告警條件。例如,如果某個服務的響應時間超過預設閾值,則觸發告警。
# 示例:告警規則定義
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency2. 設置告警的持續時間
確定告警條件持續多久后觸發告警。這可以防止短暫的指標波動導致的誤報。
3. 配置告警標簽和注釋
通過設置標簽和注釋來分類告警,并提供更多告警詳情,以幫助快速定位問題。
Alertmanager的集成和配置
Alertmanager負責處理由Prometheus發送的告警,并將告警通知發送到不同的接收器,如郵件、Slack等。
1. 配置告警路由
根據告警的嚴重性和類型配置不同的告警路由,確保告警信息能被正確地發送到相應的處理人或團隊。
# 示例:Alertmanager告警路由配置
route:
group_by: ['alertname', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: 'team-X-mails'2. 集成多種通知方式
配置不同的通知方式,如郵件、Slack、Webhook等,以適應不同團隊的需求。
3. 告警的抑制和靜默
在某些情況下,可以配置告警的抑制規則來避免冗余告警,或設置告警靜默,以在維護期間停止告警通知。
監控數據的可視化
數據的可視化是監控系統的重要組成部分,它可以幫助團隊更直觀地理解系統的狀態和性能。
1. 使用Grafana集成Prometheus
Grafana是一個流行的開源儀表板工具,可以與Prometheus集成,提供豐富的數據可視化功能。通過Grafana,可以創建實時的監控儀表板,展示關鍵指標的趨勢、分布等。
2. 構建儀表板
在Grafana中構建儀表板,選擇合適的圖表類型來展示不同的監控指標。可以根據需要創建多個儀表板,針對不同的用戶或團隊展示相關的監控數據。
3. 設置儀表板告警
Grafana也支持基于儀表板指標的告警功能。可以在Grafana中設置告警規則,并配置告警通知。
實際監控場景應用
實際監控場景中,Prometheus的應用需要根據具體的業務需求和環境進行調整。以下是一些常見的監控場景應用:
1. 微服務監控
在微服務架構中,Prometheus可以監控每個服務的性能和健康狀態。通過收集服務響應時間、錯誤率等指標,可以及時發現和定位問題。
2. 數據庫性能監控
對于數據庫服務,重要的監控指標包括查詢響應時間、事務吞吐量、連接數等。Prometheus可以幫助識別數據庫性能瓶頸和潛在的問題。
3. 容器和Kubernetes集群監控
在容器化環境中,Prometheus可以監控容器的資源使用情況,以及Kubernetes集群的整體健康狀態,包括節點健康、Pod狀態等。
告警優化策略
為了提高告警的有效性和準確性,需要采用一些優化策略:
1. 動態告警閾值
根據歷史數據和業務周期性波動,動態調整告警閾值,可以減少誤報和漏報。
2. 相關性分析
通過分析不同告警之間的相關性,可以識別出根本原因,防止同一問題產生大量冗余告警。
3. 告警收斂
對于由同一根本原因引起的多個告警,可以將它們合并為一個綜合告警,以簡化問題的響應和處理。
監控數據的深入分析
除了基本的監控和告警,深入分析監控數據可以提供更多洞察,幫助優化系統性能和資源使用。
1. 長期趨勢分析
通過分析長期的監控數據,可以識別系統的性能趨勢,預測未來的資源需求,從而進行更有效的容量規劃。
2. 異常檢測
利用Prometheus收集的數據進行異常檢測,可以及時發現系統的異常行為,甚至在問題發生前采取預防措施。
3. 故障診斷
通過詳細的監控數據和日志,可以快速定位故障發生的原因,縮短故障恢復時間。
高級數據可視化技巧
高級的數據可視化技巧可以幫助更直觀地理解監控數據,包括:
1. 復合圖表
使用復合圖表顯示相關指標的對比和關聯,如將CPU使用率和內存使用率在同一圖表中展示。
2. 儀表板模板
創建可重用的儀表板模板,可以快速部署到不同的監控場景,提高監控設置的效率。
3. 交互式探索
利用Grafana的交互式探索功能,可以動態地調整查詢參數,深入分析特定的監控數據。