













Depth Anything:釋放大規(guī)模無標注數(shù)據(jù)的深度估計
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
24年1月論文“Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data“,來自香港大學、字節(jié)、浙江實驗室和浙江大學。

這項工作提出了Depth Anything,這是一種用于魯棒單目深度估計的解決方案。目標是建立一個簡單而強大的基礎(chǔ)模型,在任何情況下處理任何圖像。為此,設(shè)計一個數(shù)據(jù)引擎來收集和自動注釋大規(guī)模未標記數(shù)據(jù)(~62M),從而大大擴大了數(shù)據(jù)覆蓋范圍,這樣能夠減少泛化誤差,從而擴大數(shù)據(jù)集的規(guī)模。作者研究了兩種簡單而有效的策略,這兩種策略使數(shù)據(jù)增強更有希望。首先,利用數(shù)據(jù)增強工具創(chuàng)建了一個更具挑戰(zhàn)性的優(yōu)化目標。它迫使模型積極尋求額外的視覺知識并獲得穩(wěn)健的表示。其次,開發(fā)了一種輔助監(jiān)督,強制該模型從預(yù)訓(xùn)練的編碼器繼承豐富的語義先驗。作者對其零樣本功能進行了廣泛評估,包括六個公共數(shù)據(jù)集和隨機拍攝的照片。它展示了很好的泛化能力。此外,利用來自NYUv2和KITTI的深度信息對其進行微調(diào),設(shè)置新的SOTA。更好的深度模型也產(chǎn)生了更好的以深度為條件模型ControlNet。
如圖所示是一些深度估計的例子:

單目深度估計(MDE)是一個在機器人[65]、自主駕駛[63,79]、虛擬現(xiàn)實[47]等領(lǐng)域有廣泛應(yīng)用的基本問題,它還需要一個基礎(chǔ)模型來估計單個圖像的深度信息。然而,由于難以構(gòu)建具有數(shù)千萬深度標簽的數(shù)據(jù)集,這一點一直沒有得到充分的探索。MiDaS[45]通過在混合標記數(shù)據(jù)集上訓(xùn)練MDE模型,沿著這一方向進行了開創(chuàng)性的研究。盡管表現(xiàn)出一定水平的零樣本能力,但MiDaS受其數(shù)據(jù)覆蓋范圍的限制,因此在某些情況下表現(xiàn)不佳。
傳統(tǒng)上,深度數(shù)據(jù)集主要通過從傳感器[18,54]、立體匹配[15]或SfM[33]獲取深度數(shù)據(jù)來創(chuàng)建,這在特定情況下是昂貴、耗時甚至難以處理的。相反,本文關(guān)注大規(guī)模的未標記數(shù)據(jù)。與立體圖像或深度傳感器的標記圖像相比,單目未標記圖像具有三個優(yōu)點:(i)(獲取簡單且便宜)單目圖像幾乎無處不在,因此易于收集,無需專門的設(shè)備。(ii)(多樣性)單目圖像可以覆蓋更廣泛的場景,這對模型的泛化能力和可擴展性至關(guān)重要。(iii)(易于注釋)簡單地使用預(yù)訓(xùn)練的MDE模型為未標記的圖像分配深度標簽,這只需要前饋推理步驟。更高效的是,這還產(chǎn)生了比激光雷達[18]更密集的深度圖,并省略了計算密集的立體匹配過程。
Depth Anything
作者的工作利用標記和未標記的圖像來促進更好的單目深度估計(MDE)。形式上,標記集和未標記集分別表示為Dl和Du。工作目標是從Dl學習教師模型T。然后,利用T為Du分配偽深度標簽。最后,在標記集和偽標記集的組合上訓(xùn)練了一個學生模型S。如圖提供了一個簡短的說明,流水線包括如下。實線:標記的圖像流,虛線:未標記的圖像,特別強調(diào)大規(guī)模未標記圖像的價值,S表示添加強擾動。為了使深度估計模型具有豐富的語義先驗,在在線的學生模型和凍結(jié)的編碼器之間強制執(zhí)行輔助約束,保持語義能力。
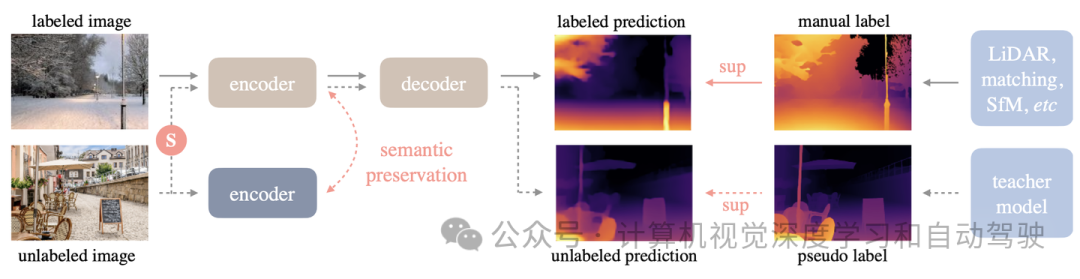
學習標記的圖像
這個過程類似于MiDaS[5,45]的訓(xùn)練。然而,由于MiDaS沒有發(fā)布代碼,首先復(fù)現(xiàn)算法。具體地說,深度值首先通過d=1/t轉(zhuǎn)換到視差空間,然后在每個深度圖上歸一化為0~1。在訓(xùn)練中,其采用仿射不變性損失。
為了獲得穩(wěn)健的單目深度估計模型,從6個公共數(shù)據(jù)集收集了1.5M的標記圖像。下表列出了這些數(shù)據(jù)集的詳細信息。
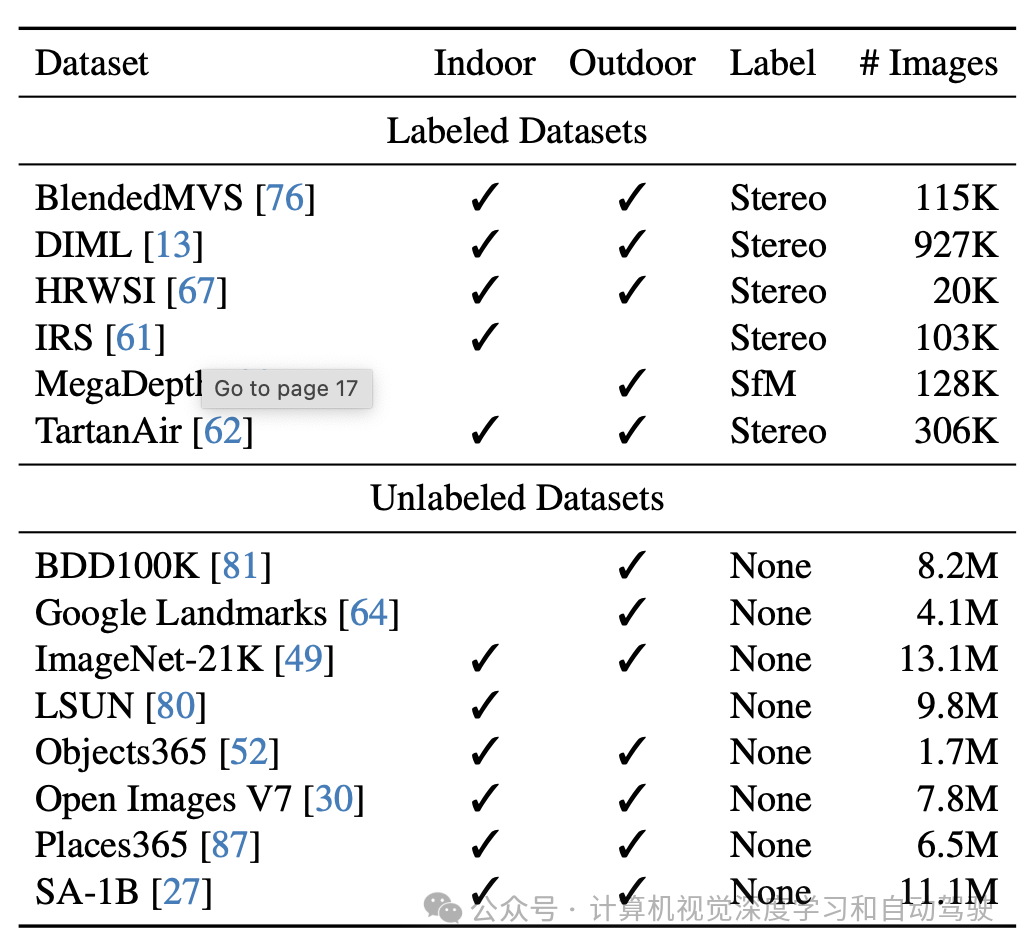
與MiDaS v3.1[5](12個訓(xùn)練數(shù)據(jù)集)相比,本文使用的標記數(shù)據(jù)集更少,因為1)不使用NYUv2[54]和KITTI[18]數(shù)據(jù)集來確保對其進行零樣本評估,2)一些數(shù)據(jù)集(不可用),例如Movies[45]和WSVD[60],以及3)一些數(shù)據(jù)集中表現(xiàn)出較差的質(zhì)量,例如RedWeb(也是低分辨率)[66]。盡管使用了更少的標記圖像,易于獲取和多樣化的未標記圖像將提高數(shù)據(jù)覆蓋率,并大大增強模型的泛化能力和穩(wěn)健性。
此外,為了加強從這些標記圖像中學習的教師模型T,采用DINOv2[42]預(yù)訓(xùn)練的權(quán)重來初始化編碼器。在實踐中,用預(yù)訓(xùn)練的語義分割模型[69]來檢測天空區(qū)域,并將其視差值設(shè)置為0(最遠)。
釋放無標記圖像的能力
與之前費力構(gòu)建不同標記數(shù)據(jù)集的工作不同,本文強調(diào)未標記圖像在增強數(shù)據(jù)覆蓋率方面的價值。如今可以從互聯(lián)網(wǎng)或各種任務(wù)的公共數(shù)據(jù)集中實際構(gòu)建一個多樣化的、大規(guī)模的未標記集合。此外,可以毫不費力地獲得單目未標記圖像的密集深度圖,只需將它們轉(zhuǎn)發(fā)到預(yù)訓(xùn)練的、性能良好的MDE模型即可。這比對立體圖像或視頻執(zhí)行立體匹配或SfM重建要方便和高效得多。選擇了八個大規(guī)模的公共數(shù)據(jù)集作為其不同場景的未標記來源。它們總共包含6200多萬張圖片。
不幸的是,在試點研究中,未能通過這種自訓(xùn)練流水線獲得改進,這確實與只有少數(shù)標記圖像時的觀察結(jié)果相矛盾[55]。對于已經(jīng)足夠的標記圖像,從額外的未標記圖像中獲取的額外知識是相當有限的。特別是考慮到教師和學生共享相同的預(yù)訓(xùn)練和架構(gòu),即使沒有明確的自訓(xùn)練程序,也傾向于對未標記集Du做出類似的正確或錯誤預(yù)測。
為了解決這一困境,建議用一個更難的優(yōu)化目標來挑戰(zhàn)學生,獲得未標記圖像上的額外視覺知識。在訓(xùn)練過程中向未標記的圖像注入強擾動。它迫使學生模型積極尋求額外的視覺知識,并從這些未標記的圖像中獲得不變的表示。這些優(yōu)勢有助于模型更有力地應(yīng)對開放世界。作者引入兩種形式的擾動:一種是強顏色失真,包括顏色抖動和高斯模糊,另一種是強烈的空間失真,即CutMix[83]。盡管簡單,但這兩個修改使大規(guī)模未標記圖像顯著提高了標記圖像的基線。
CutMix的訓(xùn)練采用無標記圖像損失,來自隨機內(nèi)插的一對無標記圖像。
語義輔助感知
有一些工作[9,21,28,71]通過輔助語義分割任務(wù)來改進深度估計。這種高級語義相關(guān)信息在深度估計模型上是有益的。此外,在用未標記圖像的特定背景下,這些來自其他任務(wù)的輔助監(jiān)督信號也可以對抗偽深度標簽中的潛在噪聲。
因此,初步嘗試用RAM[85]+GroundingDINO[37]+HQ-SAM[26]模型的組合,仔細地為未標記的圖像分配語義分割標簽。在后處理之后,這產(chǎn)生了一個包含4K類別的類空間。在聯(lián)合訓(xùn)練階段,該模型通過共享編碼器和兩個單獨的解碼器來產(chǎn)生深度和分割預(yù)測。不幸的是,經(jīng)過反復(fù)試驗,仍然無法提高原始MDE模型的性能。將圖像解碼到離散類空間中確實會丟失太多的語義信息。這些語義掩碼中的有限信息很難進一步提升深度模型,尤其是當深度模型建立了非常有競爭力的結(jié)果。
因此,工作目標是尋找更多信息的語義信號,作為深度估計任務(wù)的輔助監(jiān)督。對DINOv2模型[42]在語義相關(guān)任務(wù)中的強大性能感到非常驚訝,例如,圖像檢索和語義分割,即使在沒有任何微調(diào)的情況下使用凍結(jié)權(quán)重。受這些線索的啟發(fā),建議將其強大的語義能力轉(zhuǎn)移到具有輔助特征對齊損失的深度模型中。特征空間是高維和連續(xù)的,因此包含比離散掩碼更豐富的語義信息。
作者沒有遵循一些工作[19]將在線特征f投影到一個新空間中進行對齊,因為隨機初始化的投影器在早期階段造成的大對齊損失主導(dǎo)了整體損失。
特征對齊的另一個關(guān)鍵點是,像DINOv2這樣的語義編碼器傾向于為目標的不同部分產(chǎn)生相似的特征,例如汽車的前部和后部。然而,在深度估計中,不同部分甚至同一部分內(nèi)的像素可以具有不同的深度。因此,窮盡性地強制深度模型產(chǎn)生與凍結(jié)編碼器完全相同的特征,是無益的。
為了解決這個問題,作者為特征對齊設(shè)置了容忍差α。如果余弦相似性已經(jīng)超過α,則在特征對齊損失中不考慮該像素。這使得該方法既可以享受來自DINOv2的語義-覺察表示,也可以享受來自深度監(jiān)督的部件-級鑒別表示。作為副作用,產(chǎn)生的編碼器不僅在下游MDE數(shù)據(jù)集中表現(xiàn)良好,而且在語義分割任務(wù)中也取得了很好的效果。它還表明了編碼器作為一種通用的多任務(wù)編碼器用于中級和高級感知任務(wù)的潛力。
最后,總損失是仿射不變性損失、無標記損失和特征對齊損失的平均組合。

原文鏈接:https://mp.weixin.qq.com/s/jyAvjoonk557UwZci1zdBQ























