Elasticsearch實現(xiàn)MySQL的Like效果
在Mysql數(shù)據(jù)庫中,模糊搜索通常使用LIKE關(guān)鍵字。然而,隨著數(shù)據(jù)量的不斷增加,Mysql在處理模糊搜索時可能面臨性能瓶頸。因此,引入Elasticsearch(ES)作為搜索引擎,以提高搜索性能和用戶體驗成為一種合理的選擇。

一、客戶的訴求
在ES中,影響搜索結(jié)果的因素多種多樣,包括分詞器、Match搜索、Term搜索、組合搜索等。有些用戶已經(jīng)養(yǎng)成了在Mysql中使用LIKE進行模糊搜索的習(xí)慣。若ES返回的搜索結(jié)果不符合用戶的預(yù)期,可能會引發(fā)抱怨,甚至認(rèn)為系統(tǒng)存在Bug。
誰讓客戶是上帝,客戶是金主爸爸呢,客戶有訴求,我們就得安排上。下面我們就聊聊如何用ES實現(xiàn)Mysql的like模糊匹配效果。
二、短語匹配match_phrase
1.定義
為實現(xiàn)模糊匹配的搜索效果,通常有兩種方式,其中之一是match_phrase,先說說match_phrase。
match_phrase短語匹配會對檢索內(nèi)容進行分詞,要求這些分詞在被檢索內(nèi)容中全部存在,并且順序必須一致。默認(rèn)情況下,這些詞必須是連續(xù)的。
2.實驗
場景1:創(chuàng)建一個mapping,采用默認(rèn)分詞器(即每個字都當(dāng)做分詞),然后插入兩條數(shù)據(jù)。注意:被搜索的字段先采用text類型。
# 創(chuàng)建mapping,這里的customerName先使用text類型
PUT /search_test
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"customerName": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
# 插入2條數(shù)據(jù)
PUT /search_test/_create/1
{
"id": "111",
"customerName": "都是生產(chǎn)醫(yī)院的人"
}
PUT /search_test/_create/2
{
"id": "222",
"customerName": "家電清洗"
}
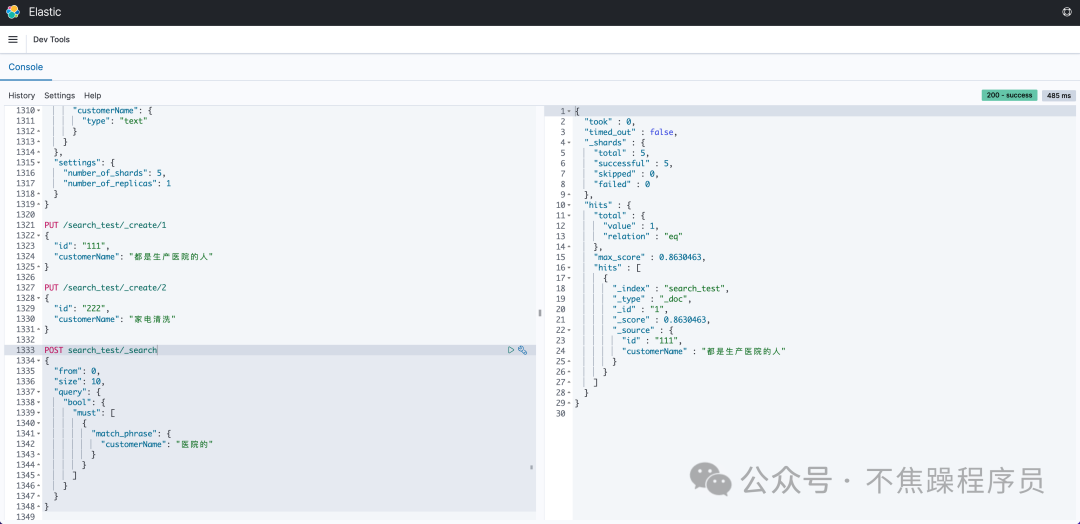
# match_phrase短語匹配查詢,可以查出結(jié)果
POST search_test/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "醫(yī)院的"
}
}
]
}
}
}以上操作結(jié)果顯示可以查詢到數(shù)據(jù)。如下圖:
場景2:創(chuàng)建一個mapping,采用默認(rèn)分詞器,然后插入兩條數(shù)據(jù)。注意:被搜索的字段先采用keyword類型。
# 創(chuàng)建mapping,這里的customerName先使用text類型
PUT /search_test2
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"customerName": {
"type": "keyword"
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
# 插入2條數(shù)據(jù)
PUT /search_test2/_create/1
{
"id": "111",
"customerName": "都是生產(chǎn)醫(yī)院的人"
}
PUT /search_test2/_create/2
{
"id": "222",
"customerName": "家電清洗"
}
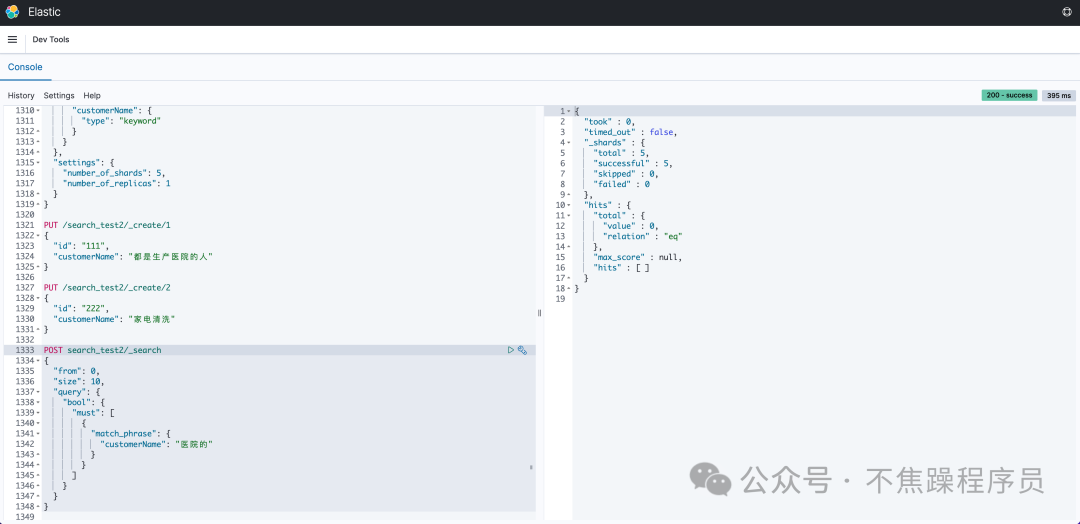
# match_phrase短語匹配查詢,可以查出結(jié)果
POST search_test2/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "醫(yī)院的"
}
}
]
}
}
}以上操作結(jié)果顯示查不到數(shù)據(jù)。如下圖:
3.小結(jié)
match_phrase短語匹配適用于text類型的字段,實現(xiàn)了類似Mysql的like模糊匹配。然而,它并不適用于keyword類型的字段。
三、通配符匹配Wildcard
為實現(xiàn)模糊匹配的搜索效果,Wildcard通配符匹配是另一種常見的方式。下面我們詳細(xì)介紹wildcard通配符查詢。下面接著說Wildcard通配符查詢。
1.定義
Wildcard Query 是使用通配符表達式進行查詢匹配。Wildcard Query 支持兩個通配符:
- ?,使用 ? 來匹配任意字符。
- *,使用 * 來匹配 0 或多個字符。
使用示例:
POST search_test/_search
{
"query": {
"wildcard": {
"customerName": "*測試*"
}
}
}2.實驗
場景1:創(chuàng)建一個mapping,采用默認(rèn)分詞器,然后插入兩條數(shù)據(jù)。注意:被搜索的字段先采用text類型。使用上文已經(jīng)創(chuàng)建的索引search_test。
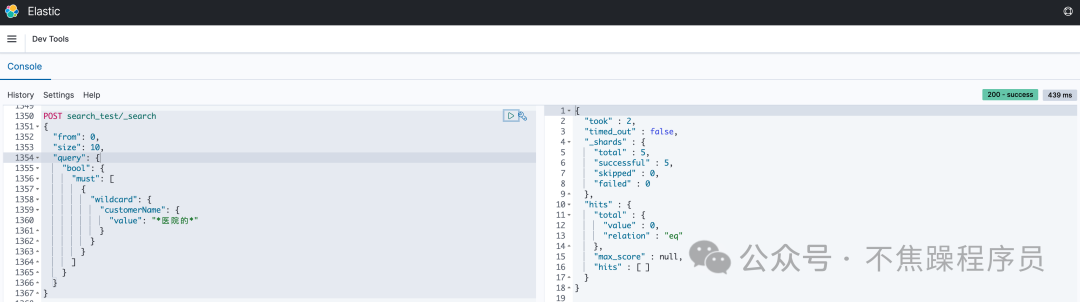
# wildcard查詢
POST search_test/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*醫(yī)院的*"
}
}
}
]
}
}
}以上操作結(jié)果顯示查不到數(shù)據(jù),如下圖:
注意:如果將DSL查詢語句改成只查“醫(yī)”,就可以查到數(shù)據(jù),這與分詞器有關(guān)。默認(rèn)分詞器將每個字都切成分詞。
# Wildcard查詢
POST search_test/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*醫(yī)*"
}
}
}
]
}
}
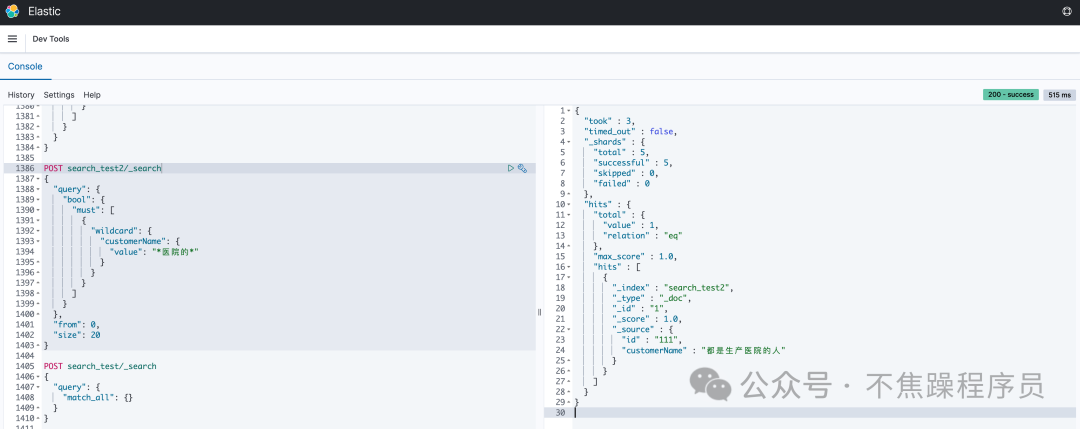
}場景2:創(chuàng)建一個mapping,采用默認(rèn)分詞器,然后插入兩條數(shù)據(jù)。注意:被搜索的字段先采用keyword類型。使用上文已經(jīng)創(chuàng)建的索引search_test2。
POST search_test2/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*醫(yī)院的*"
}
}
}
]
}
}
}以上操作結(jié)果顯示可以查到數(shù)據(jù),如下圖:
3.小結(jié)
Wildcard通配符查詢適用于keyword類型的字段,實現(xiàn)了類似Mysql的like模糊匹配。然而,它不太適用于text類型的字段。
四、選擇分詞器
上述實驗中均使用了默認(rèn)分詞器的結(jié)果。接下來,我們嘗試使用IK中文分詞器進行實驗。
1.實驗
創(chuàng)建一個名為search_test3的mapping,采用IK中文分詞器,然后插入兩條數(shù)據(jù)。注意:被搜索的字段先采用text類型。
PUT /search_test3
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"customerName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
PUT /search_test3/_create/1
{
"id": "111",
"customerName": "都是生產(chǎn)醫(yī)院的人"
}
PUT /search_test3/_create/2
{
"id": "222",
"customerName": "家電清洗"
}執(zhí)行搜索,比如搜索“醫(yī)院的”,無論是match_phrase還是wildcard兩種方式都查不到數(shù)據(jù)。
POST search_test3/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "醫(yī)院的"
}
}
]
}
}
}
POST search_test3/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*醫(yī)院的*"
}
}
}
]
}
},
"from": 0,
"size": 20
}執(zhí)行搜索,比如搜索“醫(yī)院”,match_phrase和wildcard兩種方式都可以查到數(shù)據(jù)。
POST search_test3/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customerName": "醫(yī)院"
}
}
]
}
}
}
POST search_test3/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"customerName": {
"value": "*醫(yī)院*"
}
}
}
]
}
},
"from": 0,
"size": 20
}4.小結(jié)
無論是match_phrase還是wildcard兩種方式,它們的效果與選擇的分詞器密切相關(guān)。因為兩者都是對分詞進行匹配,只有匹配到了分詞,才能找到對應(yīng)的文檔。
如果搜索內(nèi)容正好命中了對應(yīng)的分詞,就可以查詢到數(shù)據(jù)。如果沒有命中分詞,則查不到。在遇到問題時,可以使用DSL查詢查看ES的分詞情況:
POST _analyze
{
"analyzer": "ik_smart",
"text": "院的人"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "醫(yī)院的"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "都是生產(chǎn)醫(yī)院的人"
}五、總結(jié)
match_phrase和wildcard都能實現(xiàn)類似Mysql的like效果。然而,需要注意以下幾點:
- 如果要完全實現(xiàn)Mysql的like效果,最好使用默認(rèn)分詞器,即每個字都切成分詞。
- match_phrase短語匹配,適合于text類型的字段。
- Wildcard通配符查詢,適合于keyword類型的字段。