













WidthFormer:實時自動駕駛!助力基于Transformer的BEV方案量產
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&行業理解
基于BEV的transformer方案今年量產的主要方案,transformer結構和CNN相比,特征提取能力更強,但需要較多的算力,這也是為什么許多車上都是1~2顆orin芯片支持。所以如何輕量化基于Transformer的BEV方案,成為各大自動駕駛公司后面優化的重點,地平線的最新工作,將Transformer+BVE輕量化,保持了性能領先和速度領先。
WidthFormer有哪些優勢?
WidthFormer是一種輕量級且易于部署的BEV變換方法,它使用單層transformer解碼器來計算BEV表示。除此之外,還提出了參考位置編碼(RefPE),這是一種新的用于3D對象檢測的位置編碼機制,以輔助WidthFormer的視圖轉換,重點來啦!它還可以用于以即插即用的方式提高稀疏3D檢測器的性能。在nuScenes 3D檢測數據集上評估了所提出的模塊,結果表明RefPE可以顯著提高稀疏目標檢測器的性能。此外,WidthFormer在一系列3D檢測架構中的性能和效率都優于以前的BEV變換方法。
代碼:https://github.com/ChenhongyiYang/WidthFormer
WidthFormer在不同的3D檢測架構中優于以前的方法。當使用256×704輸入圖像時,它在NVIDIA 3090 GPU和地平線J5芯片上實現了1.5毫秒和2.8毫秒的延遲。此外,WidthFormer對不同程度的相機擾動也表現出較強的魯棒性。這個研究為在現實世界復雜的道路環境中部署BEV transformation方法提供了寶貴的見解。
基于BEV變換的方法一覽
直觀的基于IPM的方法通過3D-2D投影和插值計算BEV特征。其中的一個問題是,當平坦地面假設不成立時,BEV特征的質量將受到嚴重損害。在基于Lift Splat的方法中,BEV特征是通過垂直匯集投影的點云特征,并根據其預測深度進行加權來計算的。盡管Lift splat工藝具有高性能,但其效率遠遠不夠。BEVFusion通過多線程機制加速了這個池化過程!

M2BEV通過假設均勻的深度分布來節省存儲器使用。MatrixVT通過在垂直維度上壓縮視覺特征來提高整體效率,然后使用有效的極坐標變換來計算BEV特征。BEVDepth結合了點云,用于改進深度估計。基于transformer的VT方法通過注意力機制直接輸出BEV表示。PYVA使用交叉注意力來學習BEV特征,并使模型具有周期一致性。CVT和PETR依賴于3D位置編碼來向模型提供3D幾何信息。為了提高效率,最近的許多方法采用了可變形注意力。
網絡結構
如圖3所示,WidthFormer將多視圖圖像作為輸入,并輸出轉換后的BEV特征。它首先通過合并圖像的高度維度將圖像特征壓縮為寬度特征。然后使用RefineTransformer對寬度特征進行細化,以補償潛在的信息損失。在添加了參考位置編碼后,寬度特征被輸入到轉換器解碼器中,用作key和value,這些key和value由根據預定義的BEV極坐標計算的BEV查詢向量進行查詢!

1)參考位置編碼 (RefPE)
作者為基于transformer的3D檢測器(例如,PETR)和本文的BEV視圖變換模塊設計了一種新的3D位置編碼機制:參考位置編碼(RefPE)。RefPE有一個旋轉部分和一個距離部分。對于稀疏的3D檢測器,它有另一個高度部分。旋轉編碼簡單地通過對BEV平面上的相機射線的旋轉度進行編碼來計算。如(a)所示,為了計算逐點距離PE和高度PE,利用從視覺特征預測的參考系數來聚合相機射線上參考點的距離和高度PE。如(b)所示,對于寬度特征,去除高度PE,并通過使用預測的高度分布沿著圖像列聚合所有逐點距離PE來計算它們的距離PE。

2) 使用WidthForme完成BEV Transformation
WidthFormer將多視圖圖像作為輸入,并輸出轉換后的BEV特征。它首先通過合并圖像的高度維度將圖像特征壓縮為寬度特征。然后使用RefineTransformer對寬度特征進行細化,以補償潛在的信息損失。在添加了我們的參考位置編碼后,寬度特征被輸入到轉換器解碼器中,用作關鍵字和值,這些關鍵字和值由根據預定義的BEV極坐標計算的BEV查詢向量進行查詢。在所提出的RefPE的支持下,設計了一種新的基于transformer的BEV視圖轉換模塊WidthFormer。形式上,WidthFormer的輸入是多視圖圖像特征,輸出是統一的BEV表示,WidthFormer的概述如圖3所示!
3)細化Width特征
雖然將二維特征壓縮為一維特征可以極大地提高模型的效率和可擴展性,但是不可避免的引入了信息丟失,那么有什么方法可以補償這個丟失的信息呢?
Refine transformer。Refine Transformer是一種輕量級的transformer解碼器。它通過關注其他寬度特征和原始圖像特征并從中檢索信息來細化初始寬度特征。如圖3所示,通過MaxPooling圖像特征的高度維度來計算初始寬度特征。在Refine Transformer中,寬度特征首先通過自注意操作從其他寬度特征中檢索信息;然后它從相應的 使用交叉注意力操作的圖像列。最后,使用前饋網絡來計算最終的寬度特征。
補充任務。為了進一步提高寬度特征的表示能力,在訓練過程中,用互補任務訓練模型,將任務相關信息直接注入寬度特征,這是由BEVFormer v2推動的。如圖3(a)所示,互補任務包括單目3D檢測任務和高度預測任務。為這兩個任務附加了一個FCOS3D樣式的Head。頭部采用1D寬度特征作為輸入,并以單目方式檢測3D目標。為了使其能夠以1D寬度特征作為輸入,進行了兩個修改:(1)將所有2D卷積操作更改為1D卷積;(2) 在標簽編碼過程中,忽略了高度范圍,只限制了寬度范圍。為了使互補任務與WidthFormer保持一致,將原來的回歸深度估計改為分類風格。對于高度預測,在FCOS3D頭部添加了一個額外的分支,以預測目標在原始圖像特征中的高度位置,這可以補充高度pooling中丟失的信息。注意,負責補充任務在模型推理過程中可以完全去除,不會影響推理效率。此外,訓練輔助頭只消耗<10M的額外GPU內存,因此對訓練效率的影響最小!
實驗結果對比
在常用的nuScenes數據集上對提出的方法進行了基準測試,該數據集分為700、150和150個場景(分別用于訓練、驗證和測試)。每個場景包含6個視圖的圖像,這些圖像覆蓋了整個周圍環境。這里遵循官方評估協議,對3D檢測任務,除了常用的平均精度(mAP)之外,評估度量還包括nuScenes(TP)誤差,其包括平均平移誤差(mATE)、平均尺度誤差(mASE)、平均方向誤差(mAOE)、平均速度誤差(mAVE)和平均屬性誤差(mAAE),除此之外還有nuScenes檢測分數(NDS)!
這里使用兩種3D檢測架構:BEVDet和BEVDet4D來測試提出的WidthFormer,其涵蓋單幀和多幀設置。采用了BEVDet代碼庫中所有三個檢測器的實現方式。除非另有規定,否則使用BEVDet的默認數據預處理和擴充設置。將BEV特征大小設置為128×128,將BEV通道大小設置為64。對于BEVDet4D和BEVDepth4D實驗,遵循僅使用一個歷史幀的原始BEVDet4D實現。所有模型都使用CBGS進行了24個epoch的訓練,ImageNet預訓練的ResNet-50用作默認骨干網絡。所有訓練和CUDA延遲測量均使用NVIDIA 3090 GPU進行。
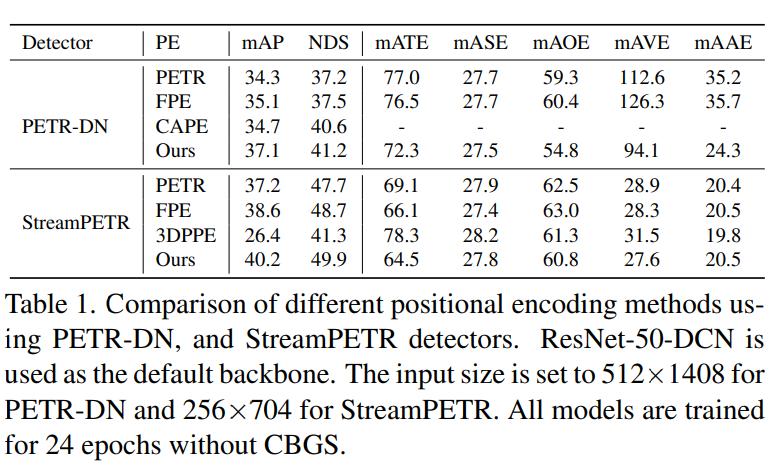
使用PETR-DN和StreamPETR檢測器的不同位置編碼方法的比較。ResNet-50-DCN用作默認主干網。輸入大小對于PETR-DN設置為512×1408,對于StreamPETR設置為256×704。所有模型都在沒有CBGS的情況下訓練了24個epoch。
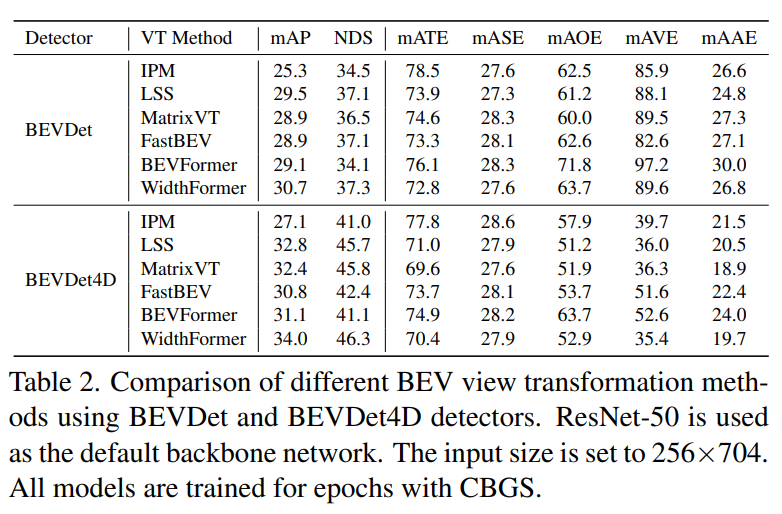
使用BEVDet和BEVDet4D檢測器的不同BEV視圖轉換方法的比較。ResNet-50被用作默認的骨干網絡。輸入大小設置為256×704。所有模型都使用CBGS進行了劃時代訓練。
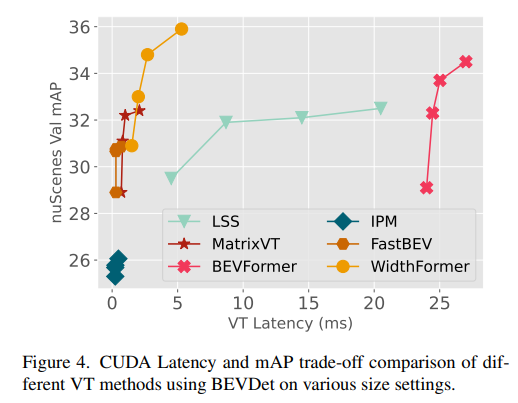
在不同尺寸設置下使用BEVDet的不同VT方法的CUDA延遲和mAP權衡比較:
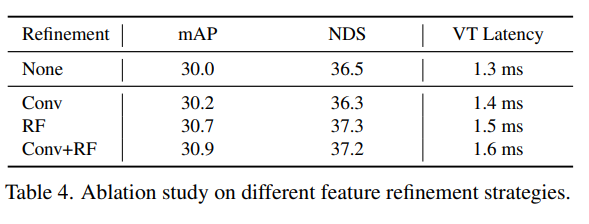
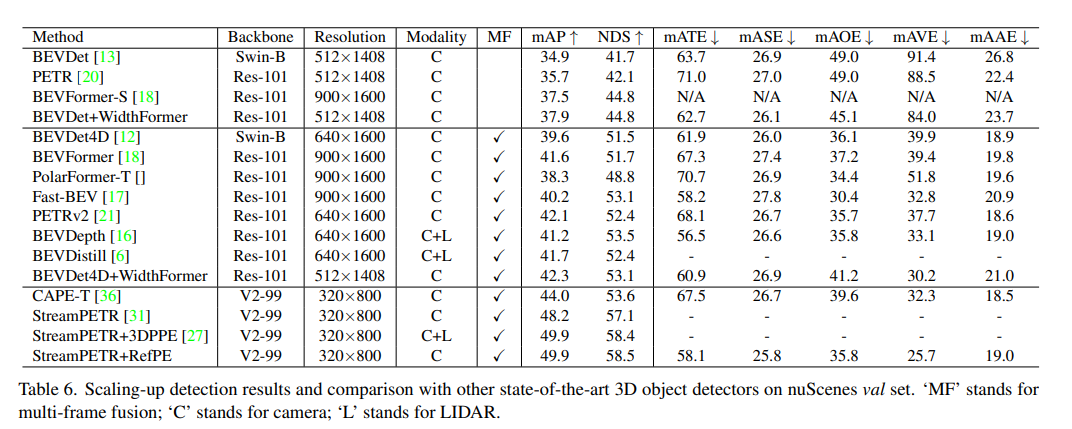
放大檢測結果,并與nuScenes val-set上其他最先進的3D檢測器進行比較。‘MF’代表多幀融合,’C'代表相機;'L'代表LIDAR!

原文鏈接:https://mp.weixin.qq.com/s/avoZwvY7H6kKk_4NlbTyjg
























