增加索引 + 異步 + 不落地后,從 12h 優化到 15 min
在開發中,我們經常會遇到這樣的需求,將數據庫中的圖片導出到本地,再傳給別人。
一、一般我會這樣做:
- 通過接口或者定時任務的形式。
- 讀取Oracle或者MySQL數據庫。
- 通過FileOutputStream將Base64解密后的byte[]存儲到本地。
- 遍歷本地文件夾,將圖片通過FTP上傳到第三方服務器。

現場炸鍋了!
實際的數據量非常大,據統計差不多有400G的圖片需要導出。
現場人員的反饋是,已經跑了12個小時了,還在繼續,不知道啥時候能導完。
停下來呢?之前的白導了,不停呢?不知道要等到啥時候才能導完。
這不行啊,速度太慢了,一個簡單的任務,不能被這東西耗死吧?
@Value("${months}")
private String months;
@Value("${imgDir}")
private String imgDir;
@Resource
private UserDao userDao;
@Override
public void getUserInfoImg() {
try {
// 獲取需要導出的月表
String[] monthArr = months.split(",");
for (int i = 0; i < monthArr.length; i++) {
// 獲取月表中的圖片
Map<String, Object> map = new HashMap<String, Object>();
String tableName = "USER_INFO_" + monthArr[i];
map.put("tableName", tableName);
map.put("status", 1);
List<UserInfo> userInfoList = userDao.getUserInfoImg(map);
if (userInfoList == null || userInfoList.size() == 0) {
return;
}
for (int j = 0; j < userInfoList.size(); j++) {
UserInfo user = userInfoList.get(j);
String userId = user.getUserId();
String userName = user.getUserName();
byte[] content = user.getImgContent;
// 下載圖片到本地
FileUtil.dowmloadImage(imgDir + userId+"-"+userName+".png", content);
// 將下載好的圖片,通過FTP上傳給第三方
FileUtil.uploadByFtp(imgDir);
}
}
} catch (Exception e) {
serviceLogger.error("獲取圖片異常:", e);
}
}二、誰寫的?趕緊加班優化,會追責嗎?
經過1小時的深思熟慮,慢的原因可能有以下幾點:
- 查詢數據庫
- 程序串行
- base64解密
- 圖片落地
- FTP上傳到服務器


使用 索引 + 異步 + 不解密 + 不落地 后,40G圖片的導出上傳,從 12+小時 優化到 15 分鐘,你敢信?
差不多的代碼,效率差距竟如此之大。
下面貼出導出圖片不落地的關鍵代碼。
@Resource
private UserAsyncService userAsyncService;
@Override
public void getUserInfoImg() {
try {
// 獲取需要導出的月表
String[] monthArr = months.split(",");
for (int i = 0; i < monthArr.length; i++) {
userAsyncService.getUserInfoImgAsync(monthArr[i]);
}
} catch (Exception e) {
serviceLogger.error("獲取圖片異常:", e);
}
}@Value("${months}")
private String months;
@Resource
private UserDao userDao;
@Async("async-executor")
@Override
public void getUserInfoImgAsync(String month) {
try {
// 獲取月表中的圖片
Map<String, Object> map = new HashMap<String, Object>();
String tableName = "USER_INFO_" + month;
map.put("tableName", tableName);
map.put("status", 1);
List<UserInfo> userInfoList = userDao.getUserInfoImg(map);
if (userInfoList == null || userInfoList.size() == 0) {
return;
}
for (int i = 0; i < userInfoList.size(); i++) {
UserInfo user = userInfoList.get(i);
String userId = user.getUserId();
String userName = user.getUserName();
byte[] content = user.getImgContent;
// 不落地,直接通過FTP上傳給第三方
FileUtil.uploadByFtp(content);
}
} catch (Exception e) {
serviceLogger.error("獲取圖片異常:", e);
}
}4、異步線程池工具類
- 在方法上添加@Async,表示此方法是異步方法。
- 在類上添加@Async,表示類中的所有方法都是異步方法。
- 使用此注解的類,必須是Spring管理的類。
- 需要在啟動類或配置類中加入@EnableAsync注解,@Async才會生效。
在使用@Async時,如果不指定線程池的名稱,也就是不自定義線程池,@Async是有默認線程池的,使用的是Spring默認的線程池SimpleAsyncTaskExecutor。
默認線程池的默認配置如下:
- 默認核心線程數:8。
- 最大線程數:Integet.MAX_VALUE。
- 隊列使用LinkedBlockingQueue。
- 容量是:Integet.MAX_VALUE。
- 空閑線程保留時間:60s。
- 線程池拒絕策略:AbortPolicy。
從最大線程數可以看出,在并發情況下,會無限制的創建線程,我勒個嗎啊。
spring:
task:
execution:
pool:
max-size: 10
core-size: 5
keep-alive: 3s
queue-capacity: 1000
thread-name-prefix: my-executor也可以自定義線程池,下面通過簡單的代碼來實現以下@Async自定義線程池。
@EnableAsync// 支持異步操作
@Configuration
public class AsyncTaskConfig {
/**
* com.google.guava中的線程池
* @return
*/
@Bean("my-executor")
public Executor firstExecutor() {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("my-executor").build();
// 獲取CPU的處理器數量
int curSystemThreads = Runtime.getRuntime().availableProcessors() * 2;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(curSystemThreads, 100,
200, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), threadFactory);
threadPool.allowsCoreThreadTimeOut();
return threadPool;
}
/**
* Spring線程池
* @return
*/
@Bean("async-executor")
public Executor asyncExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
// 核心線程數
taskExecutor.setCorePoolSize(24);
// 線程池維護線程的最大數量,只有在緩沖隊列滿了之后才會申請超過核心線程數的線程
taskExecutor.setMaxPoolSize(200);
// 緩存隊列
taskExecutor.setQueueCapacity(50);
// 空閑時間,當超過了核心線程數之外的線程在空閑時間到達之后會被銷毀
taskExecutor.setKeepAliveSeconds(200);
// 異步方法內部線程名稱
taskExecutor.setThreadNamePrefix("async-executor-");
/**
* 當線程池的任務緩存隊列已滿并且線程池中的線程數目達到maximumPoolSize,如果還有任務到來就會采取任務拒絕策略
* 通常有以下四種策略:
* ThreadPoolExecutor.AbortPolicy:丟棄任務并拋出RejectedExecutionException異常。
* ThreadPoolExecutor.DiscardPolicy:也是丟棄任務,但是不拋出異常。
* ThreadPoolExecutor.DiscardOldestPolicy:丟棄隊列最前面的任務,然后重新嘗試執行任務(重復此過程)
* ThreadPoolExecutor.CallerRunsPolicy:重試添加當前的任務,自動重復調用 execute() 方法,直到成功
*/
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.initialize();
return taskExecutor;
}
}三、告別劣質代碼,優化從何入手?
我覺得優化有兩個大方向:
- 業務優化
- 代碼優化
1、業務優化
業務優化的影響力非常大,但它一般屬于產品和項目經理的范疇,CRUD程序員很少能接觸到。
比如上面說的圖片導出上傳需求,經過產品經理和項目經理的不懈努力,這個需求不做了,這優化力度,史無前例啊。
2、代碼優化
- 數據庫優化
- 復用優化
- 并行優化
- 算法優化
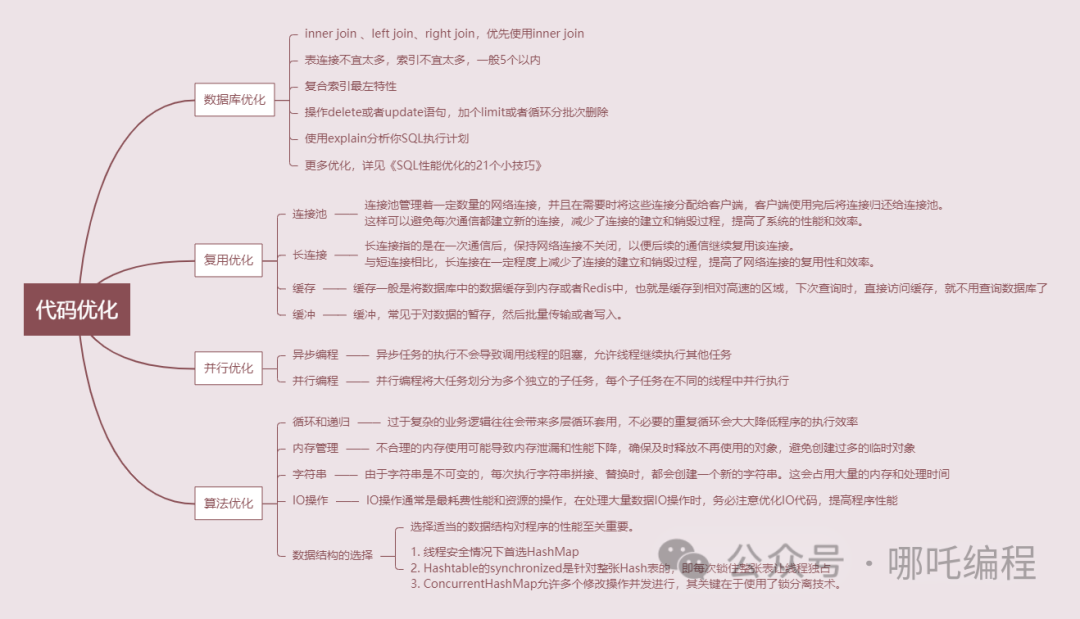
四、數據庫優化
- inner join 、left join、right join,優先使用inner join
- 表連接不宜太多,索引不宜太多,一般5個以內
- 復合索引最左特性
- 操作delete或者update語句,加個limit或者循環分批次刪除
- 使用explain分析你SQL執行計劃
- ...
五、復用優化
寫代碼的時候,大家一般都會將重復性的代碼提取出來,寫成工具方法,在下次用的時候,就不用重新編碼,直接調用就可以了。
這個就是復用。
數據庫連接池、線程池、長連接也都是復用手段,這些對象的創建和銷毀成本過高,復用之后,效率提升顯著。
1、連接池
連接池是一種常見的優化網絡連接復用性的方法。連接池管理著一定數量的網絡連接,并且在需要時將這些連接分配給客戶端,客戶端使用完后將連接歸還給連接池。這樣可以避免每次通信都建立新的連接,減少了連接的建立和銷毀過程,提高了系統的性能和效率。
在Java開發中,常用的連接池技術有Apache Commons Pool、Druid等。使用連接池時,需要合理設置連接池的大小,并根據實際情況進行調優。連接池的大小過小會導致連接不夠用,而過大則會占用過多的系統資源。
2、長連接
長連接是另一種優化網絡連接復用性的方法。長連接指的是在一次通信后,保持網絡連接不關閉,以便后續的通信繼續復用該連接。與短連接相比,長連接在一定程度上減少了連接的建立和銷毀過程,提高了網絡連接的復用性和效率。
在Java開發中,可以通過使用Socket編程實現長連接。客戶端在建立連接后,通過設置Socket的Keep-Alive選項,使得連接保持活躍狀態。這樣可以避免頻繁地建立新的連接,提高網絡連接的復用性和效率。
3、緩存
緩存也是比較常用的復用,屬于數據復用。
緩存一般是將數據庫中的數據緩存到內存或者Redis中,也就是緩存到相對高速的區域,下次查詢時,直接訪問緩存,就不用查詢數據庫了,緩存主要針對的是讀操作。
4、緩沖
緩沖常見于對數據的暫存,然后批量傳輸或者寫入。多使用順序方式,用來緩解不同設備之間頻繁地、緩慢地隨機寫,緩沖主要針對的是寫操作。
六、并行優化
1、異步編程
上面的優化方式就是異步優化,充分利用多核處理器的性能,將串行的程序改為并行,大大提高了程序的執行效率。
異步編程是一種編程模型,其中任務的執行不會阻塞當前線程的執行。通過將任務提交給其他線程或線程池來處理,當前線程可以繼續執行其他操作,而不必等待任務完成。
2、異步編程的特點
- 非阻塞:異步任務的執行不會導致調用線程的阻塞,允許線程繼續執行其他任務;
- 回調機制:異步任務通常會注冊回調函數,當任務完成時,會調用相應的回調函數進行后續處理;
- 提高響應性:異步編程能夠提高程序的響應性,尤其適用于處理IO密集型任務,如網絡請求、數據庫查詢等;
Java 8引入了CompletableFuture類,可以方便地進行異步編程。
3、并行編程
并行編程是一種利用多個線程或處理器同時執行多個任務的編程模型。它將大任務劃分為多個子任務,并發地執行這些子任務,從而加速整體任務的完成時間。
4、并行編程的特點
- 分布式任務:并行編程將大任務劃分為多個獨立的子任務,每個子任務在不同的線程中并行執行;
- 數據共享:并行編程需要考慮多個線程之間的數據共享和同步問題,以避免出現競態條件和數據不一致的情況;
- 提高性能:并行編程能夠充分利用多核處理器的計算能力,加速程序的執行速度。
5、并行編程如何實現?
- 多線程:Java提供了Thread類和Runnable接口,用于創建和管理多個線程。通過創建多個線程并發執行任務,可以實現并行編程。
- 線程池:Java的Executor框架提供了線程池的支持,可以方便地管理和調度多個線程。通過線程池,可以復用線程對象,減少線程創建和銷毀的開銷;
- 并發集合:Java提供了一系列的并發集合類,如ConcurrentHashMap、ConcurrentLinkedQueue等,用于在并行編程中實現線程安全的數據共享。
異步編程和并行編程是Java中處理任務并提高程序性能的兩種重要方法。
異步編程通過非阻塞的方式處理任務,提高程序的響應性,并適用于IO密集型任務。
而并行編程則是通過多個線程或處理器并發執行任務,充分利用計算資源,加速程序的執行速度。
在Java中,可以使用CompletableFuture和回調接口實現異步編程,使用多線程、線程池和并發集合實現并行編程。通過合理地運用異步和并行編程,我們可以在Java中高效地處理任務和提升程序的性能。
6、代碼示例
public static void main(String[] args) {
// 創建線程池
ExecutorService executor = Executors.newFixedThreadPool(10);
// 使用線程池創建CompletableFuture對象
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
// 一些不為人知的操作
return "result"; // 返回結果
}, executor);
// 使用CompletableFuture對象執行任務
CompletableFuture<String> result = future.thenApply(result -> {
// 一些不為人知的操作
return "result"; // 返回結果
});
// 處理任務結果
String finalResult = result.join();
// 關閉線程池
executor.shutdown();
}7、Java 8 parallel
(1)parallel()是什么
Stream.parallel() 方法是 Java 8 中 Stream API 提供的一種并行處理方式。在處理大量數據或者耗時操作時,使用 Stream.parallel() 方法可以充分利用多核 CPU 的優勢,提高程序的性能。
Stream.parallel() 方法是將串行流轉化為并行流的方法。通過該方法可以將大量數據劃分為多個子任務交由多個線程并行處理,最終將各個子任務的計算結果合并得到最終結果。使用 Stream.parallel() 可以簡化多線程編程,減少開發難度。
需要注意的是,并行處理可能會引入線程安全等問題,需要根據具體情況進行選擇。
(2)舉一個簡單的demo
定義一個list,然后通過parallel() 方法將集合轉化為并行流,對每個元素進行i++,最后通過 collect(Collectors.toList()) 方法將結果轉化為 List 集合。
使用并行處理可以充分利用多核 CPU 的優勢,加快處理速度。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
System.out.println(list);
List<Integer> result = list.stream().parallel().map(i -> i++).collect(Collectors.toList());
System.out.println(result);
}
}我勒個去,什么情況?

(3)parallel()的優缺點
① 優點:
- 充分利用多核 CPU 的優勢,提高程序的性能;
- 可以簡化多線程編程,減少開發難度。
② 缺點:
- 并行處理可能會引入線程安全等問題,需要根據具體情況進行選擇;
- 并行處理需要付出額外的開銷,例如線程池的創建和銷毀、線程切換等,對于小數據量和簡單計算而言,串行處理可能更快。
(4)何時使用parallel()?
在實際開發中,應該根據數據量、計算復雜度、硬件等因素綜合考慮。
比如:
- 數據量較大,有1萬個元素;
- 計算復雜度過大,需要對每個元素進行復雜的計算;
- 硬件夠硬,比如多核CPU。
七、算法優化
在上面的例子中,避免base64解密,就應該歸類于算法優化。
程序就是由數據結構和算法組成,一個優質的算法可以顯著提高程序的執行效率,從而減少運行時間和資源消耗。相比之下,一個低效的算法就可能導致運行非常緩慢,并占用大量系統資源。
很多問題都可以通過算法優化來解決,比如:
1、循環和遞歸
循環和遞歸是Java編程中常見的操作,然而,過于復雜的業務邏輯往往會帶來多層循環套用,不必要的重復循環會大大降低程序的執行效率。
遞歸是一種函數自我調用的技術,類似于循環,雖然遞歸可以解決很多問題,但是,遞歸的效率有待提高。
2、內存管理
Java自帶垃圾收集器,開發人員不用手動釋放內存。
但是,不合理的內存使用可能導致內存泄漏和性能下降,確保及時釋放不再使用的對象,避免創建過多的臨時對象。
3、字符串
我覺得字符串是Java編程中使用頻率最高的技術,很多程序員恨不得把所有的變量都定義成字符串。
然而,由于字符串是不可變的,每次執行字符串拼接、替換時,都會創建一個新的字符串。這會占用大量的內存和處理時間。
使用StringBuilder來處理字符串的拼接可以顯著的提高性能。
4、IO操作
IO操作通常是最耗費性能和資源的操作。在處理大量數據IO操作時,務必注意優化IO代碼,提高程序性能,比如上面提高的圖片不落地就是徹底解決IO問題。
5、數據結構的選擇
選擇適當的數據結構對程序的性能至關重要。
比如Java世界中用的第二多的Map,比較常用的有HashMap、HashTable、ConcurrentHashMap。
- HashMap,底層數組+鏈表實現,可以存儲null鍵和null值,線程不安全;
- HashTable,底層數組+鏈表實現,無論key還是value都不能為null,線程安全,實現線程安全的方式是在修改數據時鎖住整個HashTable,效率低,ConcurrentHashMap做了相關優化;
- ConcurrentHashMap,底層采用分段的數組+鏈表實現,線程安全,通過把整個Map分為N個Segment,可以提供相同的線程安全,但是效率提升N倍,默認提升16倍。
Hashtable的synchronized是針對整張Hash表的,即每次鎖住整張表讓線程獨占,ConcurrentHashMap允許多個修改操作并發進行,其關鍵在于使用了鎖分離技術。