













從模型、數(shù)據(jù)和框架三個視角出發(fā),這里有份54頁的高效大語言模型綜述
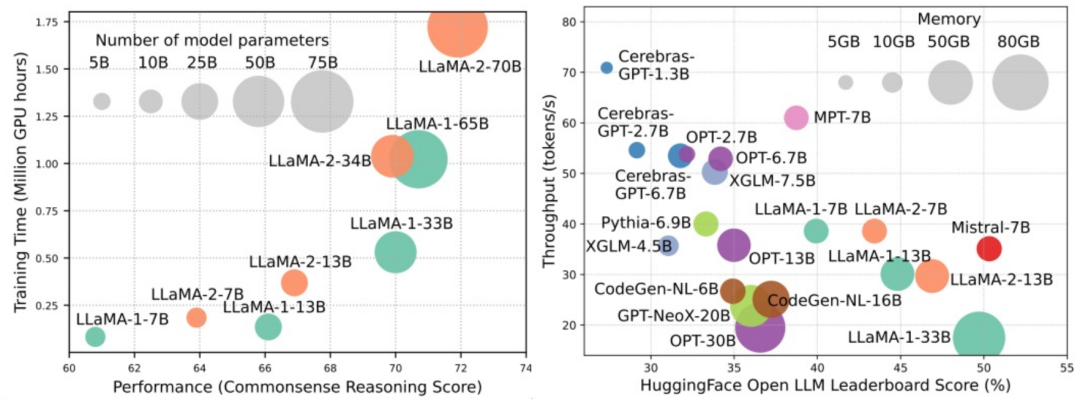
大規(guī)模語言模型(LLMs)在很多關鍵任務中展現(xiàn)出顯著的能力,比如自然語言理解、語言生成和復雜推理,并對社會產(chǎn)生深遠的影響。然而,這些卓越的能力伴隨著對龐大訓練資源的需求(如下圖左)和較長推理時延(如下圖右)。因此,研究者們需要開發(fā)出有效的技術手段去解決其效率問題。
同時,我們從圖右還可以看出,近來較為火熱的高效 LLMs,例如 Mistral-7B,在確保和 LLaMA1-33B 相近的準確度的情況下可以大大減少推理內(nèi)存和降低推理時延,可見已有部分可行的高效手段被成功應用于 LLMs 的設計和部署中。
在本綜述中,來自俄亥俄州立大學、帝國理工學院、密歇根州立大學、密西根大學、亞馬遜、谷歌、Boson AI、微軟亞研院的研究者提供了對高效 LLMs 研究的系統(tǒng)全面調(diào)查。他們將現(xiàn)有優(yōu)化 LLMs 效率的技術分成了三個類別,包括以模型為中心、以數(shù)據(jù)為中心和以框架為中心,總結并討論了當下最前沿的相關技術。

- 論文:https://arxiv.org/abs/2312.03863
- GitHub: https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
同時,研究者建立了一個 GitHub 倉庫,用于整理綜述中涉及的論文,并將積極維護這個倉庫,隨著新的研究涌現(xiàn)而不斷更新。研究者希望這篇綜述能夠幫助研究人員和從業(yè)者系統(tǒng)地了解高效 LLMs 研究和發(fā)展,并激發(fā)他們?yōu)檫@一重要而令人興奮的領域做出貢獻。
倉庫網(wǎng)址:https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
以模型為中心
以模型為中心的方法關注算法層面和系統(tǒng)層面的高效技術,其中模型本身是焦點。由于 LLMs 具有數(shù)十億甚至數(shù)萬億的參數(shù),與規(guī)模較小的模型相比,它們具有諸如涌現(xiàn)等獨特的特征,因此需要開發(fā)新的技術來優(yōu)化 LLMs 的效率。本文詳細討論了五類以模型為中心的方法,包括模型壓縮、高效預訓練、高效微調(diào)、高效推理和高效模型架構設計。
1. 模型壓縮
模型壓縮技術主要分為了四類:量化、參數(shù)剪枝、低秩估計和知識蒸餾(參見下圖),其中量化會把模型的權重或者激活值從高精度壓縮到低精度,參數(shù)剪枝會搜索并刪除模型權重中較為冗余的部分,低秩估計會將模型的權重矩陣轉化為若干低秩小矩陣的乘積,知識蒸餾則是直接用大模型來訓練小模型,從而使得小模型在做某些任務的時候具有替代大模型的能力。

2. 高效預訓練
預訓練 LLMs 的成本非常昂貴。高效預訓練旨在提高效率并降低 LLMs 預訓練過程的成本。高效預訓練又可以分為混合精度加速、模型縮放、初始化技術、優(yōu)化策略和系統(tǒng)層級的加速。
混合精度加速通過使用低精度權重計算梯度、權重和激活值,然后在將其轉換回高精度并應用于更新原始權重,從而提高預訓練的效率。模型縮放通過使用小型模型的參數(shù)來擴展到大型模型,加速預訓練的收斂并降低訓練成本。初始化技術通過設計模型的初始化取值來加快模型的收斂速度。優(yōu)化策略是重在設計輕量的優(yōu)化器來降低模型訓練過程中的內(nèi)存消耗,系統(tǒng)層級的加速則是通過分布式等技術來從系統(tǒng)層面加速模型的預訓練。

3. 高效微調(diào)
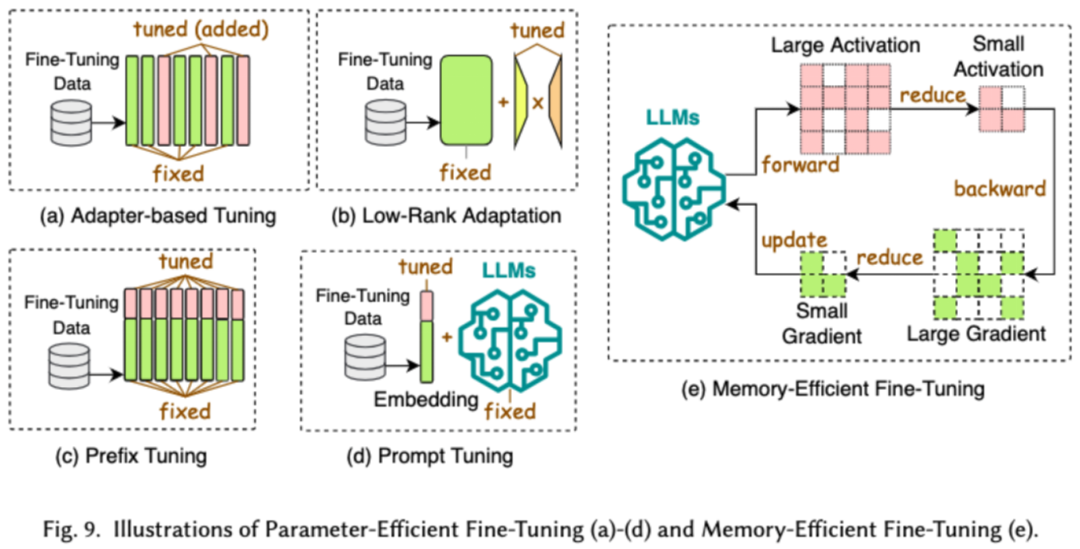
高效微調(diào)旨在提高 LLMs 微調(diào)過程的效率。常見的高效微調(diào)技術分為了兩類,一類是基于參數(shù)高效的微調(diào),一類是基于內(nèi)存高效的微調(diào)。
基于參數(shù)高效微調(diào)(PEFT)的目標是通過凍結整個 LLM 主干,僅更新一小組額外的參數(shù),將 LLM 調(diào)整到下游任務。在論文中,我們又將 PEFT 詳細分成了基于適配器的微調(diào)、低秩適配、前綴微調(diào)和提示詞微調(diào)。
基于內(nèi)存的高效微調(diào)則是重在降低整個 LLM 微調(diào)過程中的內(nèi)存消耗,比如減少優(yōu)化器狀態(tài)和激活值等消耗的內(nèi)存。
4. 高效推理
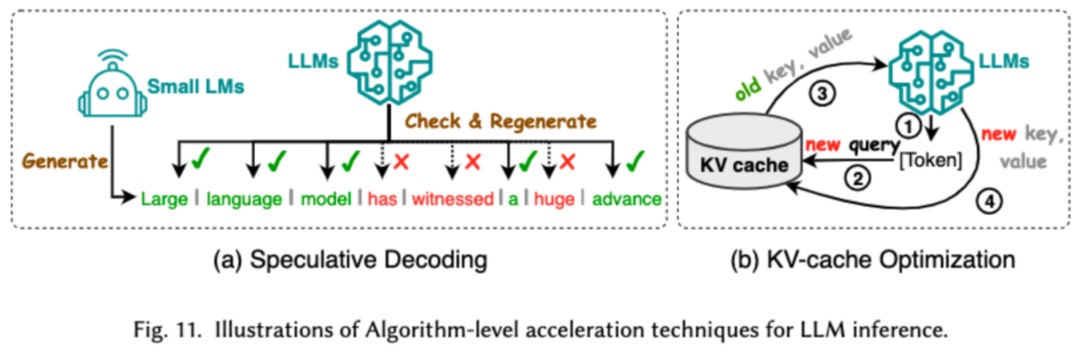
高效推理旨在提高 LLMs 推理過程的效率。研究者將常見的高效推理技術分成了兩大類,一類是算法層級的推理加速,一類是系統(tǒng)層級的推理加速。
算法層級的推理加速又可以分成兩類:投機解碼和 KV - 緩存優(yōu)化。投機解碼通過使用較小的草稿模型并行計算令牌,為較大目標模型創(chuàng)建猜測性前綴,從而以加速采樣過程。KV - 緩存優(yōu)化指的是優(yōu)化在 LLMs 推理過程中 Key-Value(KV)對的重復計算。
系統(tǒng)層級的推理加速則是在指定硬件上優(yōu)化內(nèi)存訪問次數(shù),增大算法并行量等來加速 LLM 的推理。
5. 高效模型架構設計
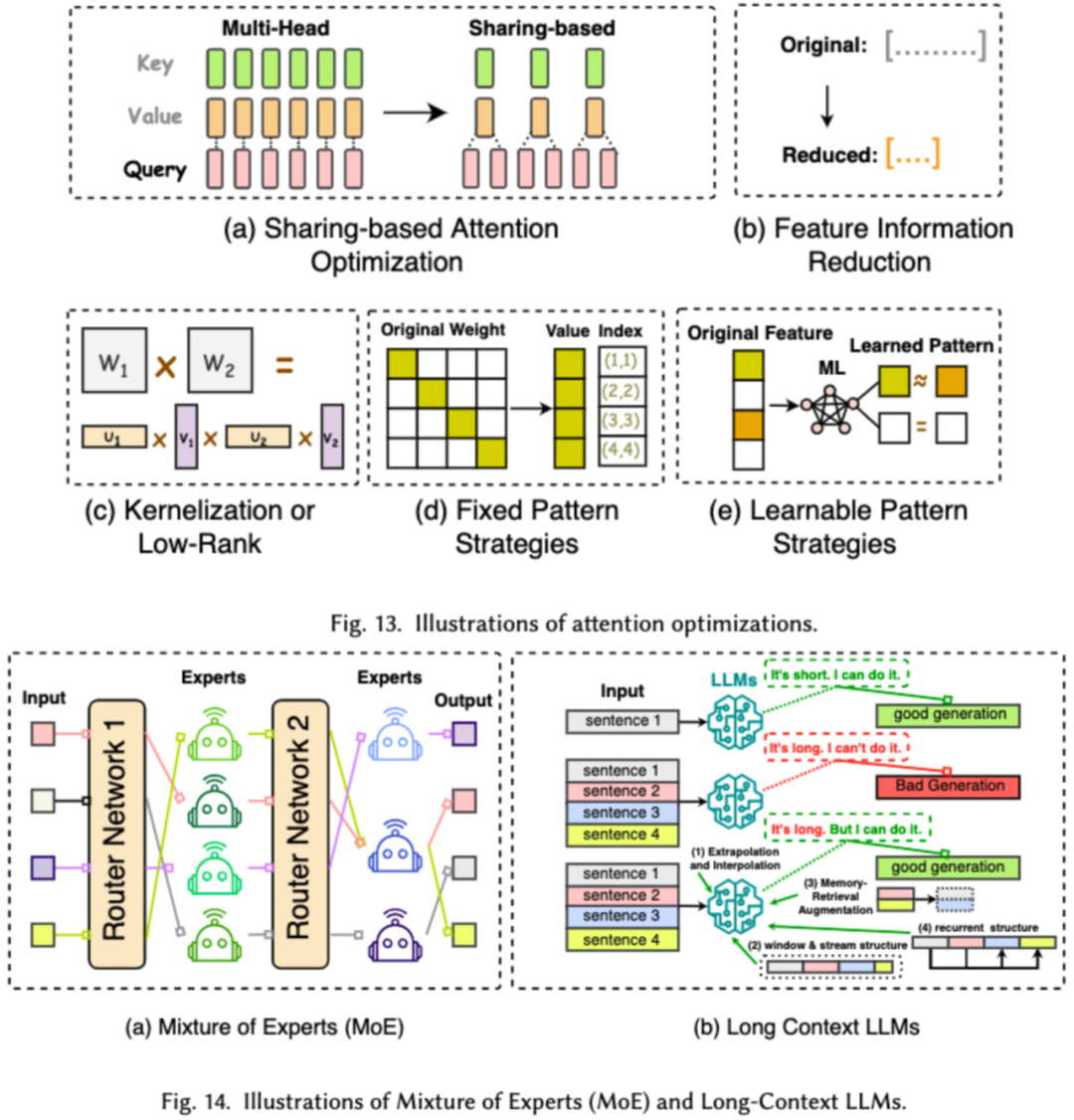
對 LLMs 進行高效架構設計是指通過策略性優(yōu)化模型結構和計算過程,以提高性能和可擴展性,同時最小化資源消耗。我們將高效的模型架構設計依據(jù)模型的種類分成了四大類:高效注意力模塊、混合專家模型、長文本大模型以及可替代 transformer 的架構。
高效注意力模塊旨在優(yōu)化注意力模塊中的復雜計算及內(nèi)存占用,混合專家模型(MoE)則是通過將 LLMs 的某些模塊的推理決策使用多個小的專家模型來替代從而達到整體的稀疏化,長文本大模型是專門設計來高效處理超長文本的 LLMs, 可替代 transformer 的架構則是通過重新設計模型架構,來降低模型的復雜度并達到后 transformer 架構相當?shù)耐评砟芰Α?/span>
以數(shù)據(jù)為中心
以數(shù)據(jù)為中心方法側重于數(shù)據(jù)的質(zhì)量和結構在提高 LLMs 效率方面的作用。研究者在本文中詳細討論了兩類以數(shù)據(jù)為中心的方法,包括數(shù)據(jù)選擇和提示詞工程。
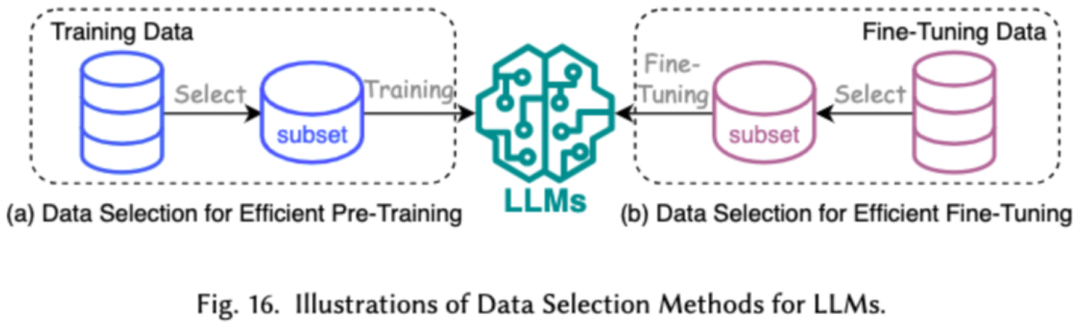
1. 數(shù)據(jù)選擇
LLMs 的數(shù)據(jù)選擇旨在對預訓練 / 微調(diào)數(shù)據(jù)進行清洗和選擇,例如去除冗余和無效數(shù)據(jù),達到加快訓練過程的目的。
2. 提示詞工程
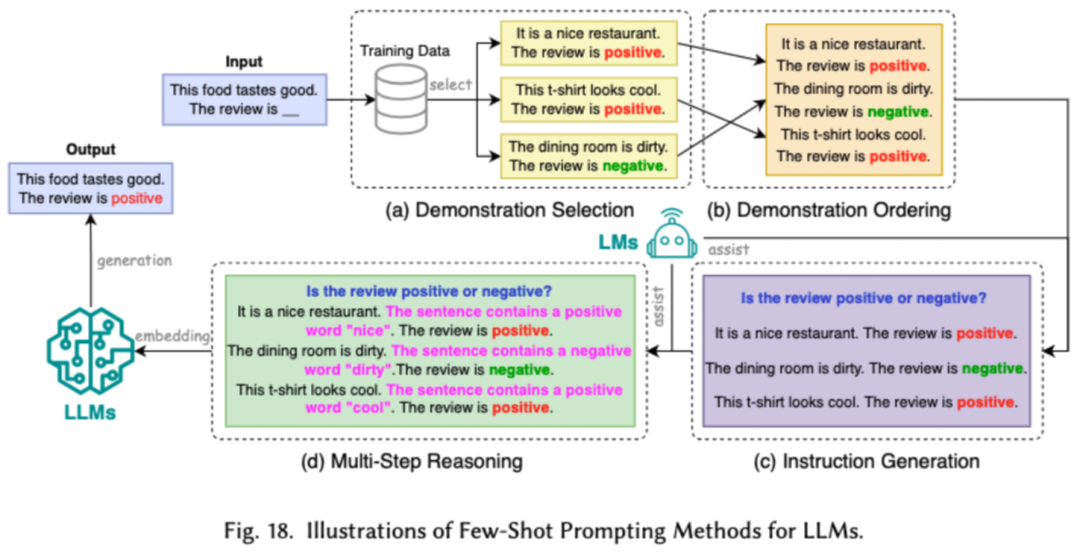
提示詞工程通過設計有效的輸入(提示詞)來引導 LLMs 生成期望的輸出,它的高效之處在于可以通過設計提示詞,來達到和經(jīng)過將繁瑣的微調(diào)相當?shù)哪P捅憩F(xiàn)。研究者將常見的的提示詞工程技術分成了三大類:少樣本的提示詞工程、提示詞壓縮和提示詞生成。
少樣本的提示詞工程通過向 LLM 提供有限的示例集以引導其對需要執(zhí)行的任務進行理解。提示詞壓縮是通過壓縮冗長的提示輸入或?qū)W習和使用提示表示,加速 LLMs 對輸入的處理。提示詞生成旨在自動創(chuàng)建有效的提示,引導模型生成具體且相關的響應,而不是使用手動標注的數(shù)據(jù)。

以框架為中心
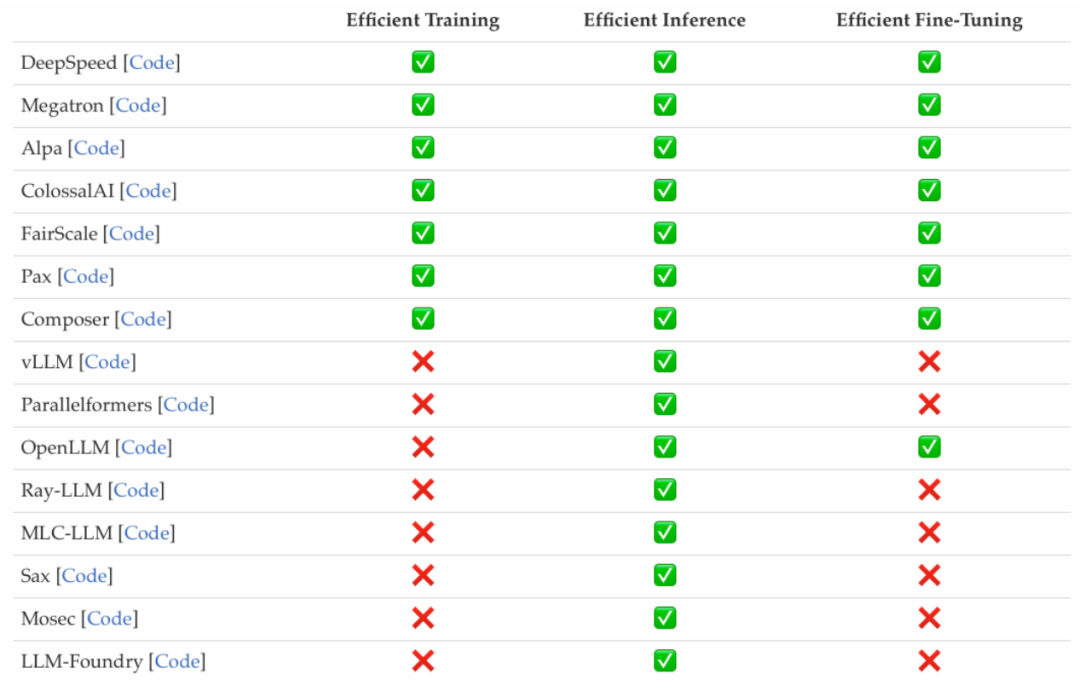
研究者調(diào)查了近來較為流行的高效 LLMs 框架,并列舉了它們所能優(yōu)化的高效任務,包括預訓練、微調(diào)和推理(如下圖所示)。
總結
在這份調(diào)查中,研究者為大家提供了一份關于高效 LLMs 的系統(tǒng)性回顧,這是一個致力于使 LLMs 更加民主化的重要研究領域。他們一開始就解釋了為什么需要高效 LLMs。在一個有序的框架下,本文分別從以模型的中心、以數(shù)據(jù)的中心和以框架為中心的角度分別調(diào)查了 LLMs 的算法層面和系統(tǒng)層面的高效技術。
研究者相信,在 LLMs 和以 LLMs 為導向的系統(tǒng)中,效率將發(fā)揮越來越重要的作用。他們希望這份調(diào)查能夠幫助研究人員和實踐者迅速進入這一領域,并成為激發(fā)新的高效 LLMs 研究的催化劑。
























