什么?NeRF還能提升BEV泛化性能!首個BEV跨域開源代碼并首次完成Sim2Real!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人總結
鳥瞰圖(Bird eye's view, BEV)檢測是一種通過融合多個環視攝像頭來進行檢測的方法。目前算法大部分算法都是在相同數據集訓練并且評測,這導致了這些算法過擬合于不變的相機內參(相機類型)和外參(相機擺放方式)。本文提出了一種基于隱式渲染的BEV檢測框架,能夠解決未知域的物體檢測問題。該框架通隱式渲染來建立物體3D位置和單個視圖的透視位置關系,這可以用來糾正透視偏差。此方法在領域泛化(DG)和無監督領域適應(UDA)方面取得了顯著的性能提升。該方法首次嘗試了只用虛擬數據集上進行訓練在真實場景下進行評測BEV檢測,可以打破虛實之間的壁壘完成閉環測試。
- 論文鏈接:https://arxiv.org/pdf/2310.11346.pdf
- 代碼鏈接:https://github.com/EnVision-Research/Generalizable-BEV

BEV檢測域泛化問題背景
多相機檢測是指利用多臺攝像機對三維空間中的物體進行檢測和定位的任務。通過結合來自不同視點的信息,多攝像頭3D目標檢測可以提供更準確和魯棒的目標檢測結果,特別是在某些視點的目標可能被遮擋或部分可見的情況下。近年來,鳥瞰圖檢測(Bird eye's view, BEV)方法在多相機檢測任務中得到了極大的關注。盡管這些方法在多相機信息融合方面具有優勢,但當測試環境與訓練環境存在顯著差異時,這些方法的性能可能會嚴重下降。
目前BEV檢測算法大部分算法都是在相同數據集訓練并且評測,這導致了這些算法過擬合于不變的相機內外參數和城市道路條件。然而在BEV檢測實際應用中,常常要求算法要適配不同新車型和新攝像頭,這導致了這些算法的失效。所以,研究BEV檢測的泛化性研究非常重要。此外,無人駕駛的閉環仿真也是非常重要的,但是閉環仿真目前只能在虛擬引擎(例如Carla)中進行評測。所以,打破虛擬引擎和真實場景中的域差異也非常必要。
域泛化(domain generalization, DG)和無監督域自適應(unsupervised domain adaptation, UDA)是緩解分布偏移的兩個有前途的方向。DG方法經常解耦和消除特定于領域的特征,從而提高不可見領域的泛化性能。對于UDA,最近的方法通過生成偽標簽或潛在特征分布對齊來緩解域偏移。然而,如果不使用來自不同視點、相機參數和環境的數據,純視覺感知學習與視角和環境無關的特征是非常具有挑戰性的。
觀察表明單視角(相機平面)的2D檢測往往比多視角的3D目標檢測具有更強的泛化能力,如圖所示。一些研究已經探索了將2D檢測整合到BEV檢測中,例如將2D信息融合到3D檢測器中或建立2D-3D一致性。二維信息融合是一種基于學習的方法,而不是一種機制建模方法,并且仍然受到域遷移的嚴重影響。現有的2D-3D一致性方法是將3D結果投影到二維平面上并建立一致性。這種約束可能損害目標域中的語義信息,而不是修改目標域的幾何信息。此外,這種2D-3D一致性方法使得所有檢測頭的統一方法具有挑戰性。

本論文的的貢獻總結
- 本論文提出了一種基于視角去偏的廣義BEV檢測框架,該框架不僅可以幫助模型學習源域中的視角和上下文不變特征,還可以利用二維檢測器進一步糾正目標域中的虛假幾何特征。
- 本文首次嘗試在BEV檢測上研究無監督域自適應,并建立了一個基準。在UDA和DG協議上都取得了最先進的結果。
- 本文首次探索了在沒有真實場景注釋的虛擬引擎上進行訓練,以實現真實世界的BEV檢測任務。
BEV檢測域泛化問題定義
問題定義
研究主要圍繞增強BEV檢測的泛化。為了實現這一目標,本文探索了兩個廣泛具有實際應用價值的協議,即域泛化(domain generalization, DG)和無監督域自適應(unsupervised domain adaptation, UDA):
BEV檢測的域泛化(DG):在已有的數據集(源域)訓練一個BEV檢測算法,提升在具有在未知數據集(目標域)的檢測性能。例如,在特定車輛或者場景下訓練一個BEV檢測模型,能夠直接泛化到各種不同的車輛和場景。
BEV檢測的無監督域自適應(UDA):在已有的數據集(源域)訓練一個BEV檢測算法,并且利用目標域的無標簽數據來提高檢測性能。例如,在一個新的車輛或者城市,只需要采集一些無監督數據就可以提高模型在新車和新環境的性能。值得一提的是DG和UDA的唯一區別是是否可以利用目標域的未標記數據。
視角偏差定義
為了檢測物體的未知L=[x,y,z],大部分BEV檢測會有關鍵的兩部(1)獲取不同視角的圖像特征;(2)融合這些圖像特征到BEV空間并且得到最后的預測結果:
上面公式描述,域偏差可能來源于特征提取階段或者BEV融合階段。然后本文進行了在附錄進行了推到,得到了最后3D預測結果投影到2D結果的視角偏差為:
其中k_u, b_u, k_v和b_v與BEV編碼器的域偏置有關,d(u,v)為模型的最終預測深度信息。c_u和c_v表示相機光學中心在uv圖像平面上的坐標。上面等式提供了幾個重要的推論:(1)最終位置偏移的存在會導致視角偏差,這表明優化視角偏差有助于緩解域偏移。(2)即使是相機光心射線上的點在單個視角成像平面上的位置也會發生移位。
直觀地說,域偏移改變了BEV特征的位置,這是由于訓練數據視點和相機參數有限而產生的過擬合。為了緩解這個問題,從BEV特征中重新渲染新的視圖圖像是至關重要的,從而使網絡能夠學習與視角和環境無關的特征。鑒于此,本文旨在解決不同渲染視點相關的視角偏差,以提高模型的泛化能力。
詳解PD-BEV算法
PD-BEV一共分為三個部分:語義渲染,源域去偏見和目標域去偏見如圖1所示。語義渲染是闡述如如何通過BEV特征建立2D和3D的透視關系。源域去偏見是描述在源域如何通過語義渲染來提高模型泛化能力。目標域去偏見是描述在目標域利用無標住的數據通過語義渲染來提高模型泛化能力。

語義渲染
因為很多算法都會講BEV volume的高度拍扁成為二維的特征,這部分講先利用一個BEV Decoder將BEV特征提升成一個Volume:
上面的公式其實就是對BEV平面進行了提升,增加了一個高度維度。然后通過相機的內外參數就可以在這個Volume采樣成為一個2D的特征圖,然后這個2D特征圖和相機內外參數送到一個RenderNet里面來預測對應視角的heatmap和物體的屬性。通過這樣的類似于Nerf的操作就可以建立起2D和3D的橋梁。
源域去偏見
這個部分在源域如何提高模型泛化性能的。為了減少視角偏差,源域的3D框可以用來監控新渲染視圖的熱圖和屬性。此外,還利用歸一化深度信息來幫助圖像編碼器更好地學習幾何信息。
視角語義監督:基于語義渲染,熱圖和屬性從不同的角度渲染(RenderNet的輸出)。同時,隨機采樣一個相機內外參數,將物體的方框從3D坐標利用這些內外參數投射到二維相機平面內。然后對投影后的2Dbox與渲染的結果使用Focal loss和L1 loss進行約束:
通過這個操作可以降低對相機內外參數的過擬合以及對新視角的魯棒性。值得一提的是,這個論文將監督從RGB圖像換成了物體中心的heatmaps,可以避免Nerf在無人駕駛領域缺少新視角RGB監督的缺點。
幾何監督:提供明確的深度信息可以有效地提高多相機3D目標檢測的性能。然而,網絡預測的深度傾向于過擬合內在參數。因此,這個論文借鑒了一種虛擬深度的方式:
其中BCE()表示二進制交叉熵損失,D_{pre}表示DepthNet的預測深度。f_u和f_v分別為像平面的u和v焦距,U為常數。值得注意的是,這里的深度是使用3D框而不是點云提供的前景深度信息。通過這樣做,DepthNet更有可能專注于前景物體的深度。最后,當使用實際深度信息將語義特征提升到BEV平面時,將虛擬深度轉換回實際深度。
目標域去偏見
在目標域就沒有標注了,所以就不能用3D box監督來提高模型的泛化能力了。所以這個論文闡述說,2D檢測的結果比起3D結果更加魯棒。所以這個論文利用在源域中的2D預訓練的檢測器作為渲染后的視角的的監督,并且還利用了偽標簽的機制:
這個操作可以有效地利用精確的二維檢測來校正BEV空間中的前景目標位置,這是一種目標域的無監督正則化。為了進一步增強二維預測的校正能力,采用偽方法增強預測熱圖的置信度。這個論文在3.2和補充材料里給出了數學證明說明了3D結果在2D投影誤差的原因。以及闡述了為什么通過這種方式可以去偏見,詳細的可以參考原論文。
總體的監督
雖然本文已經添加了一些網絡來幫助訓練,但這些網絡在推理中是不需要的。換句話說,本文的方法適用于大多數BEV檢測方法學習透視不變特征。為了測試我們框架的有效性,BEVDepth被實例化為測評對象。在源域上使用BEVDepth的原始損失作為主要的三維檢測監督。總之,算法的最終損失是:
跨域實驗結果
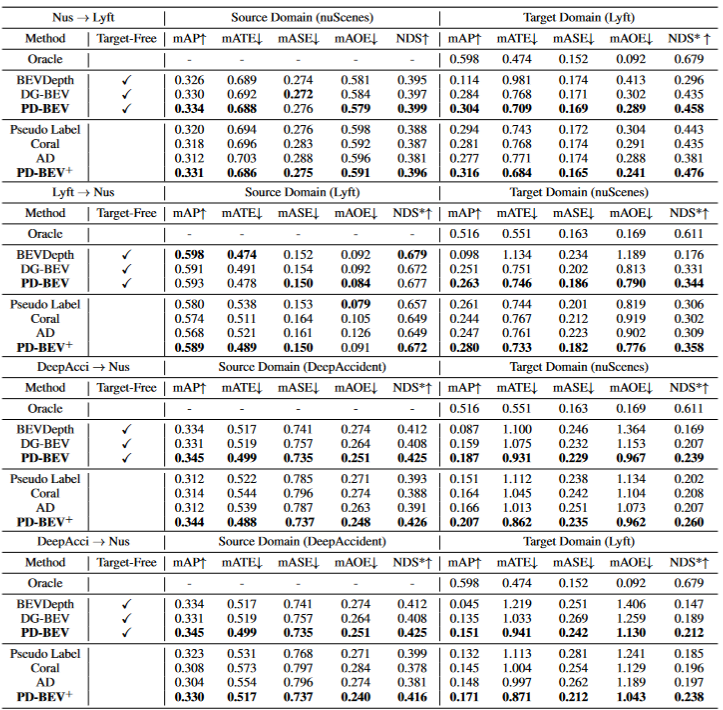
表格1展示了在領域泛化(DG)和無監督領域適應(UDA)協議下不同方法的效果比較。其中,Target-Free表示DG協議,Pseudo Label、Coral和AD是在UDA協議上的一些常見方法。圖表中,方法在目標域取得了顯著的改進。它表明語義渲染作為一個橋梁可以幫助學習針對域移位的透視不變特征。此外,方法不會犧牲源域的性能,甚至在大多數情況下有一些改進。值得一提的是,DeepAccident來源于一個Carla虛擬引擎,算法也通過在DeepAccident上的訓練獲得了令人滿意的泛化能力。此外,測試了其他BEV檢測方法,在沒有特殊設計的情況下,它們的泛化性能非常差。為了進一步驗證利用目標域無監督數據集的能力,還建立了一個UDA基準,并在DG-BEV上應用了UDA方法(包括Pseudo Label、Coral 和AD。算法實現了顯著的性能提升。隱式渲染充分利用具有更好泛化性能的二維探測器來校正三維探測器的虛假幾何信息。此外,發現大多數算法傾向于降低源域的性能,本文方法相對溫和。值得一提的是,發現AD和Coral在從虛擬數據集轉移到真實數據集時表現出顯著的改進,但在真實測試中測試時表現出性能下降。這是因為這兩種算法是為解決風格變化而設計的,但在樣式變化很小的場景中,它們可能會破壞語義信息。對于Pseudo Label算法,它可以通過在一些相對較好的目標域中增加置信度來提高模型的泛化性能,但盲目地增加目標域中的置信度實際上會使模型變得更差。實驗結果證明了算法在DG和UDA方面取得了顯著的性能提升。
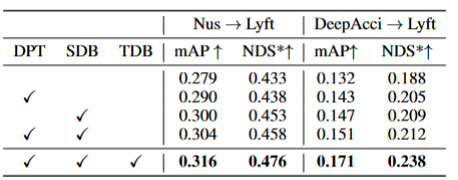
表格2展示了算法在三個關鍵組件上的消融實驗結果:2D檢測器預訓練(DPT)、源域去偏(SDB)和目標域去偏(TDB)。實驗結果表明,每個組件都取得了改進,其中SDB和TDB表現出相對顯著的效果。
表格3展示了算法算法可以遷移到BEVFormer和FB-OCC算法上。因為這個算法是只需要對圖像特征和BEV特征加上額外的操作,所以可以對有BEV特征的算法都有提升作用。
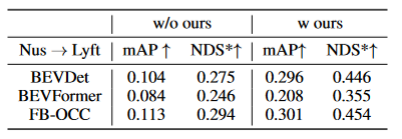
圖5展示了檢測到的未標記物體。第一行是標簽的3D框,第二行是算法的檢測結果。藍色框表示算法可以檢測到一些未標記的框。這表明方法在目標域甚至可以檢測到沒有標記的樣本,例如過遠或者街道兩側建筑內的車輛。

總結
本文提出了一種基于透視去偏的通用多攝像頭3D物體檢測框架,能夠解決未知領域的物體檢測問題。該框架通過將3D檢測結果投影到2D相機平面,并糾正透視偏差,實現一致和準確的檢測。此外,該框架還引入了透視去偏策略,通過渲染不同視角的圖像來增強模型的魯棒性。實驗結果表明,該方法在領域泛化和無監督領域適應方面取得了顯著的性能提升。此外,該方法還可以在虛擬數據集上進行訓練,無需真實場景標注,為實時應用和大規模部署提供了便利。這些亮點展示了該方法在解決多攝像頭3D物體檢測中的挑戰和潛力。這篇論文嘗試利用Nerf的思路來提高BEV的泛化能力,同時可以利用有標簽的源域數據和無標簽的目標域數據。此外,嘗試了Sim2Real的實驗范式,這對于無人駕駛閉環具有潛在價值。從定性和定量結果都有很好的結果,并且開源了代碼值得看一看。

原文鏈接:https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2g