如何提升小計(jì)算量的BEV模型性能?也許DistillBEV是個(gè)答案!
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
筆者的個(gè)人理解
BEV模型今年被越來越多自動(dòng)駕駛公司落地上車,雖然Nvidia的Orin平臺(tái)和地平線的J5系列算力都比較大,但由于功能模型較多,很多公司都在想辦法將模型做小,但小模型計(jì)算量的減少會(huì)導(dǎo)致性能下降,那么如何提升小模型性能呢?領(lǐng)域常見的方法主要是半監(jiān)督和蒸餾。今天的主角是知識(shí)蒸餾任務(wù),蒸餾又分為同構(gòu)蒸餾和異構(gòu)蒸餾,由于現(xiàn)在大多方案是純視覺,通過點(diǎn)云大模型蒸餾視覺小模型受到了許多團(tuán)隊(duì)的認(rèn)可,是一種無痛漲點(diǎn)的方法。
如何設(shè)計(jì)蒸餾模型呢
多目BEV 3D感知方案由于相機(jī)的較低成本使其在自動(dòng)駕駛領(lǐng)域大規(guī)模生產(chǎn)中成為主流,單/多目 BEV 和基于 LiDAR 的 3D 目標(biāo)檢測(cè)之間存在明顯的性能差距。一個(gè)關(guān)鍵原因是 LiDAR 可以捕獲準(zhǔn)確的深度和其他幾何測(cè)量結(jié)果,而僅從圖像輸入推斷此類 3D 信息是非常具有挑戰(zhàn)性的。DistillBEV提出通過訓(xùn)練基于多目 BEV 的學(xué)生檢測(cè)器模仿訓(xùn)練有素的基于 LiDAR 的教師檢測(cè)器的特征來增強(qiáng)其表示學(xué)習(xí)。并提出了有效的平衡策略,以強(qiáng)制學(xué)生專注于從老師那里學(xué)習(xí)關(guān)鍵特征,并將知識(shí)轉(zhuǎn)移到具有時(shí)間融合的多尺度層。DistillBEV提出了 BEV 中的跨模式蒸餾,它自然地適用于 LiDAR 和基于多目 BEV 的探測(cè)器之間的知識(shí)傳輸。除此之外,有效的平衡設(shè)計(jì),使學(xué)生能夠?qū)W⒂趯W(xué)習(xí)多尺度和時(shí)間融合的教師的關(guān)鍵特征。DistillBEV的方法比學(xué)生模型有了顯著改進(jìn),在 nuScenes 上實(shí)現(xiàn)了最先進(jìn)的性能。
知識(shí)蒸餾在檢測(cè)任務(wù)中為什么重要
基于相機(jī)
該領(lǐng)域的許多方法基于單目視覺范式,如FCOS3D和DD3D,類似于2D目標(biāo)檢測(cè)。最近,基于多目的BEV(鳥瞰圖)框架因其固有的優(yōu)點(diǎn)而成為趨勢(shì)。在這個(gè)框架中,視圖轉(zhuǎn)換模塊起著將多視圖圖像特征轉(zhuǎn)換為BEV的基礎(chǔ)性作用。一些方法采用逆透視映射或多層感知器來執(zhí)行從透視視圖到BEV的轉(zhuǎn)換。引入LSS來通過相應(yīng)的逐bin深度分布提升圖像特征的方法如BEVDet,BEVDet4D和BEVDepth。BEVFormer中提出,利用交叉注意力來查找和匯聚跨目的圖像特征。此外,BEV表示提供了在多個(gè)時(shí)間戳上改善目標(biāo)檢測(cè)和運(yùn)動(dòng)狀態(tài)估計(jì)的更理想的場(chǎng)景特征連接。BEVDet4D和BEVDepth通過空間對(duì)齊融合先前和當(dāng)前的特征,而BEVFormer通過軟注意力進(jìn)行時(shí)間上的融合。
基于Lidar
由于該領(lǐng)域的大多數(shù)方法將不規(guī)則點(diǎn)云轉(zhuǎn)換為規(guī)則網(wǎng)格,如柱狀物或體素,因此自然而然地在BEV中提取特征。VoxelNet對(duì)每個(gè)體素內(nèi)聚合的點(diǎn)特征應(yīng)用3D卷積。SECOND利用稀疏的3D卷積提高計(jì)算效率。PointPillars提出將高度維度折疊并使用2D卷積以進(jìn)一步減少推理延遲。CenterPoint是一種流行的無錨點(diǎn)方法,將目標(biāo)表示為點(diǎn)。PillarNeXt表明,基于柱狀物的模型在架構(gòu)和訓(xùn)練方面的現(xiàn)代化設(shè)計(jì)在準(zhǔn)確性和延遲方面都優(yōu)于體素對(duì)應(yīng)物。廣泛使用融合多個(gè)傳感器來增強(qiáng)檢測(cè)性能。MVP是CenterPoint的傳感器融合版本,通過虛擬圖像點(diǎn)增強(qiáng)。
知識(shí)蒸餾
這項(xiàng)技術(shù)最初是為了通過將來自較大教師模型的信息傳遞給緊湊的學(xué)生模型來進(jìn)行網(wǎng)絡(luò)壓縮而提出的。該領(lǐng)域中的大多數(shù)方法最初是為圖像分類而設(shè)計(jì)的,但對(duì)于圖像目標(biāo)檢測(cè)的改進(jìn)卻很少。最近一些方法已成功地將知識(shí)蒸餾應(yīng)用于2D目標(biāo)檢測(cè)。然而,對(duì)于3D目標(biāo)檢測(cè)的蒸餾研究較少,特別是當(dāng)教師和學(xué)生模型來自不同模態(tài)時(shí)。與DistillBEV提出的方法最相關(guān)的工作是BEVDistill,該工作引入了一種密集的前景引導(dǎo)特征模仿和一種稀疏的實(shí)例級(jí)蒸餾,以從激光雷達(dá)傳遞空間知識(shí)到多目3D目標(biāo)檢測(cè)。與這種方法相比,DistillBEV的方法通過引入?yún)^(qū)域分解和自適應(yīng)縮放實(shí)現(xiàn)了更精細(xì)的蒸餾。此外,DistillBEV的設(shè)計(jì)適應(yīng)多尺度蒸餾,可以增強(qiáng)在不同特征抽象層面上的跨模態(tài)知識(shí)傳遞。
怎么設(shè)計(jì)一個(gè)BEV下的蒸餾網(wǎng)絡(luò)

區(qū)域分解
根據(jù)GT以及teacher與student之間的差異程度進(jìn)行區(qū)域劃分,著重學(xué)習(xí)有GT區(qū)域和diff區(qū)域
在 2D 目標(biāo)檢測(cè)中由于前景和背景區(qū)域之間的不平衡,簡(jiǎn)單地在教師和學(xué)生之間進(jìn)行特征對(duì)齊很難取得改進(jìn)。這種現(xiàn)象在 3D 目標(biāo)檢測(cè)中更為嚴(yán)重,因?yàn)榻^大多數(shù) 3D 空間沒有目標(biāo)。通過對(duì) BEV 特征圖的統(tǒng)計(jì)發(fā)現(xiàn),平均不到 30% 的像素是非空的,意味著其中只有一小部分包含感興趣的目標(biāo)。為了進(jìn)行有效的知識(shí)遷移,DistillBEV引入了區(qū)域分解來指導(dǎo)學(xué)生應(yīng)重點(diǎn)關(guān)注關(guān)鍵區(qū)域,而不是平等對(duì)待所有區(qū)域。具體來說,將特征圖分為四種類型:真陽(yáng)性(TP)、假陽(yáng)性(FP)、真陰性(TN)和假陰性(FN)。因此,定義區(qū)域分解掩模:
其中是特征圖上的坐標(biāo),用來控制 FP 區(qū)域中像素的相對(duì)重要性。
這種分解使DistillBEV的方法能夠靈活地為不同區(qū)域分配不同的重要性。考慮地面真值框覆蓋的區(qū)域(即 TP 和 FN 區(qū)域的并集)是很簡(jiǎn)單的,它們準(zhǔn)確地傳達(dá)了前景目標(biāo)的特征。然而,DistillBEV也以不同于 TN 區(qū)域的方式對(duì)待 FP 區(qū)域。當(dāng)教師模型在某些區(qū)域產(chǎn)生高激活時(shí),即使它們是 FP(例如,一根桿子被誤檢測(cè)為行人),鼓勵(lì)學(xué)生模型模仿此類特征響應(yīng)仍然有利于整體 3D 幾何學(xué)習(xí)。可以通過對(duì)教師檢測(cè)器和地面真實(shí)標(biāo)簽生成的置信度熱圖進(jìn)行閾值化來找到 FP 區(qū)域:
其中和分別對(duì)應(yīng)于從教師模型和地面實(shí)況獲得的熱圖,是熱圖閾值化的超參數(shù)。
尺度自適應(yīng)
目標(biāo)面積越大,越縮放(大的前景),F(xiàn)P,TN區(qū)域(背景)被縮放,生成weight map約束損失
在 BEV 中從教師向?qū)W生提取知識(shí)的另一個(gè)挑戰(zhàn)是各種目標(biāo)尺寸的巨大跨度。例如,從鳥瞰角度看,一輛公共汽車的體積是行人的幾十倍。此外,墻壁和植物等背景淹沒了非空白區(qū)域。因此,背景目標(biāo)和巨大的前景目標(biāo)將主導(dǎo)蒸餾損失,因?yàn)楦嗟奶卣鱽碜杂谒鼈儭OM从硨?duì)蒸餾損失具有相似貢獻(xiàn)的不同大小的目標(biāo)或類別。引入自適應(yīng)縮放因子來實(shí)現(xiàn)此目標(biāo):
其中 是 BEV 中邊界框長(zhǎng)度為 和寬度為 的第 k 個(gè)GT(TP 或 FN), 和 分別表示落入 FP 和 TN 區(qū)域的像素?cái)?shù)。
空間注意力
由teacher的空間注意力以及student的多尺度自適應(yīng)后(尺度對(duì)齊)的空間注意力構(gòu)成一張attention map用于后續(xù)約束損失
DistillBEV采用基于提取的教師和學(xué)生特征的空間注意力圖來進(jìn)一步選擇更多信息豐富的特征來關(guān)注。空間注意力圖的構(gòu)建方式如下:
是特征圖,是沿著channel維度的特征圖的平均池化結(jié)果,是 softmax 對(duì)所有空間位置的歸一化注意力,τ是調(diào)整分布熵的溫度。DistillBEV通過考慮教師 和學(xué)生 的特征圖來獲得最終的空間注意力圖:
其中,是teacher特征圖到student特征圖的自適應(yīng)模塊。
多尺度蒸餾
蒸餾(尺度對(duì)齊后的)多尺度,但是區(qū)域劃分基于有語(yǔ)義表達(dá)能力的head層
網(wǎng)絡(luò)中不同深度的層編碼不同的抽象特征,結(jié)合了不同級(jí)別的特征,可以更好地檢測(cè)各種大小的對(duì)象。為了實(shí)現(xiàn)教師和學(xué)生之間的全面對(duì)齊,DistillBEV采用這種思想對(duì)基于CNN的模型進(jìn)行多尺度的特征蒸餾。但教師和學(xué)生網(wǎng)絡(luò)是分別設(shè)計(jì)的不同的架構(gòu),使得找到中間特征對(duì)應(yīng)關(guān)系變得非常重要。例如,教師中的 BEV 特征圖通常是學(xué)生中 BEV 特征圖大小的 2 倍或 4 倍。簡(jiǎn)單地對(duì)齊相同分辨率的特征會(huì)導(dǎo)致特征抽象級(jí)別的不兼容。因此,DistillBEV引入了一個(gè)由上采樣和投影層組成的輕量級(jí)適應(yīng)模塊,以在與類似級(jí)別的教師特征對(duì)齊之前映射學(xué)生特征。還發(fā)現(xiàn),早期層的特征模仿不利于蒸餾,這是因?yàn)辄c(diǎn)云和圖像之間的模態(tài)差距引起的表示差異在早期階段仍然很大。因此,DistillBEV僅在 BEV 的最后一個(gè)編碼層(即 pre-head 特征)識(shí)別和利用 FP 區(qū)域。這種設(shè)置效果最好,推測(cè)是因?yàn)樽詈笠粚映霈F(xiàn)的高級(jí)語(yǔ)義特征可以更好地表達(dá) FP 區(qū)域。
蒸餾損失
上述設(shè)計(jì)均被用于雷達(dá)teacher對(duì)相機(jī)student的損失部分
DistillBEV用包括分類和回歸的原始損失以及整體蒸餾損失來訓(xùn)練學(xué)生網(wǎng)絡(luò),首先定義教師 和學(xué)生 之間第 個(gè)蒸餾層的特征模仿?lián)p失
其中,,是區(qū)域分解掩模的邏輯補(bǔ),表示自適應(yīng)縮放因子,是空間注意力圖,α和β是對(duì)這兩項(xiàng)進(jìn)行加權(quán)的超參數(shù)。
DistillBEV利用注意力模仿?lián)p失來強(qiáng)制學(xué)生學(xué)習(xí)生成注意力模式,與教師相似,因此關(guān)注教師網(wǎng)絡(luò)認(rèn)為更重要的空間位置:
總損失:
其中 是選擇執(zhí)行蒸餾的層數(shù),λ控制兩個(gè)損失函數(shù)之間的相對(duì)重要性。
時(shí)間融合的蒸餾
多相機(jī) BEV 中表示的一項(xiàng)理想特性是促進(jìn)多個(gè)時(shí)間戳特征的融合。利用時(shí)間融合開發(fā)的方法通過利用重要的動(dòng)態(tài)線索極大地改進(jìn)了 3D 對(duì)象檢測(cè)和運(yùn)動(dòng)估計(jì)。至于基于激光雷達(dá)的模型,通常的做法是通過自運(yùn)動(dòng)補(bǔ)償直接將過去的掃描轉(zhuǎn)換到當(dāng)前坐標(biāo)系來融合多個(gè)點(diǎn)云,并將相對(duì)時(shí)間戳添加到每個(gè)點(diǎn)的測(cè)量中。因此,在DistillBEV的方法中進(jìn)行時(shí)態(tài)知識(shí)遷移是很自然的,因?yàn)榻處熆梢院苋菀椎嘏c使用時(shí)態(tài)信息的學(xué)生兼容。在實(shí)踐中,對(duì)基于單幀和多幀的學(xué)生模型采用統(tǒng)一的教師模型,以通過時(shí)間融合進(jìn)行蒸餾。
DistillBEV優(yōu)勢(shì)在哪里?
我們?cè)诖笠?guī)模自動(dòng)駕駛基準(zhǔn)測(cè)試nuScenes上進(jìn)行了評(píng)估。該數(shù)據(jù)集包括大約20秒的1,000個(gè)場(chǎng)景,由32束激光雷達(dá)和20Hz和10Hz頻率下的6個(gè)目捕獲。對(duì)于3D目標(biāo)檢測(cè),總共有10個(gè)類別,標(biāo)注以2Hz的頻率提供。按照標(biāo)準(zhǔn)評(píng)估劃分,分別使用700、150和150個(gè)場(chǎng)景進(jìn)行訓(xùn)練、驗(yàn)證和測(cè)試。遵循官方評(píng)估指標(biāo),包括平均精度(mAP)和nuScenes檢測(cè)分?jǐn)?shù)(NDS)作為主要指標(biāo)。還使用mATE、mASE、mAOE、mAVE和mAAE來測(cè)量平移、尺度、方向、速度和屬性相關(guān)的錯(cuò)誤。
教師和學(xué)生模型 為了驗(yàn)證DistillBEV方法的普適性,考慮了各種教師和學(xué)生模型。采用流行的CenterPoint或其傳感器融合版本MVP作為教師模型。至于學(xué)生模型,選擇BEVDet、BEVDet4D、BEVDepth和BEVFormer作為代表性的學(xué)生模型,它們代表了從CNN到Transformer、從base版本到時(shí)間("4D" 以融合時(shí)間)和空間("Depth" 以增強(qiáng)可信賴深度估計(jì))擴(kuò)展的廣泛范圍的學(xué)生模型。這些模型共同形成8種不同的教師-學(xué)生組合。
在PyTorch中實(shí)現(xiàn),并使用8個(gè)NVIDIA Tesla V100 GPU進(jìn)行網(wǎng)絡(luò)訓(xùn)練,批量大小為64。采用AdamW作為優(yōu)化器,學(xué)習(xí)率采用2e-4的余弦調(diào)度。所有模型均經(jīng)過24個(gè)時(shí)期的訓(xùn)練,采用CBGS策略。遵循BEVDet和BEVDepth,在圖像和BEV空間中都應(yīng)用了數(shù)據(jù)增強(qiáng)。按照標(biāo)準(zhǔn)評(píng)估協(xié)議設(shè)置檢測(cè)范圍為[-51.2m, 51.2m]×[-51.2m, 51.2m]。ResNet-50在ImageNet-1K上預(yù)先訓(xùn)練,用作圖像的骨干網(wǎng)絡(luò),圖像大小處理為256×704,除非另有說明。采用通過教師的參數(shù)初始化學(xué)生的檢測(cè)頭,以實(shí)現(xiàn)更快的收斂。
Main Results
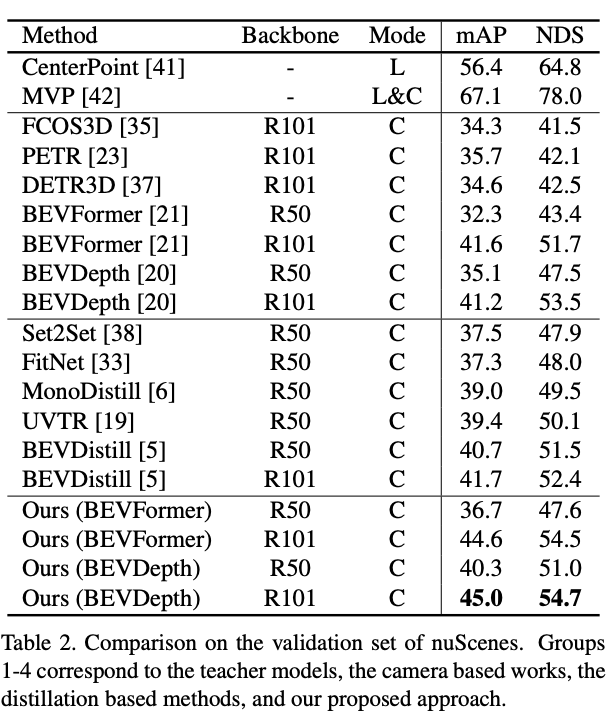
nuScenes驗(yàn)證集上基于多個(gè)base采用DistillBEV結(jié)果:

nuScenes驗(yàn)證集:
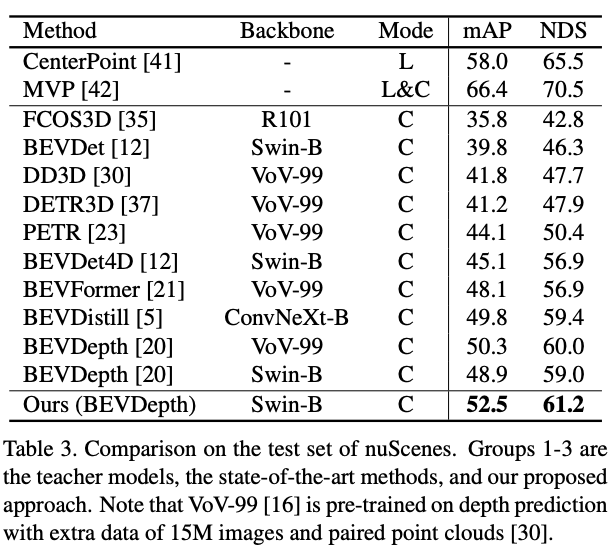
nuScenes測(cè)試集:
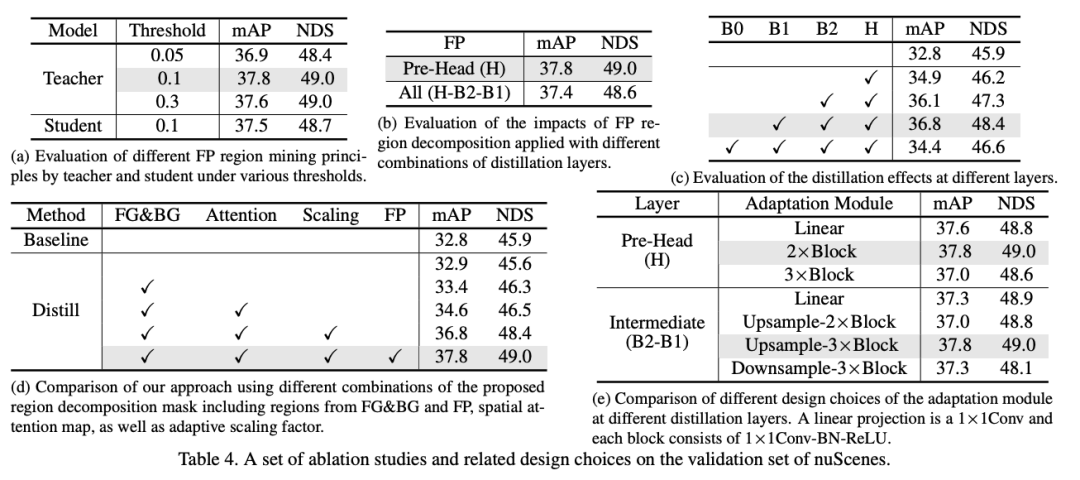
Ablation Studies
Visualization

參考:DistillBEV: Boosting Multi-Camera 3D Object Detection with Cross-Modal Knowledge Distillation

原文鏈接:https://mp.weixin.qq.com/s/qlHnKpCDrbP4WQs9GCxXLA