













單張4090,1秒100張二次元小姐姐!UC伯克利等新模型霸榜Github,吞吐量提升近60倍
10毫秒生成一張圖像,1分鐘6000張圖像,這是什么概念?
下圖中,就可以深刻感受到AI的超能力。
甚至,當你在二次元小姐姐圖片生成的提示中,不斷加入新的元素,各種風格的圖片更迭也是瞬間閃過。
如此驚人的圖片實時生成速度,便是來自UC伯克利、日本筑波大學等研究人員提出StreamDiffusion帶來的結果。
這個全新的解決方案是一種擴散模型流程,能夠以超過100fps的速度,實現實時交互式圖像生成。

論文地址:https://arxiv.org/abs/2312.12491
StreamDiffusion開源后直接霸榜GitHub,狂攬3.7k星。
StreamDiffusion創新性采用了批處理策略,而非序列去噪,比傳統方法快大約1.5倍。而且作者提出的新型剩余無分類器引導(RCFG)算法能夠比傳統無分類引導快2.05倍。
最值得一提的是,新方法在RTX 4090上,圖像到圖像的生成速度可達91.07fps。
未來,在元宇宙、視頻游戲圖形渲染、直播視頻流等不同場景中,StreamDiffusion快速生成能夠滿足這些應用的高吞吐量的需求。
尤其,實時的圖像生成,能夠為那些游戲開發、視頻渲染的打工人們,提供了強大的編輯和創作能力。
專為實時圖像生成設計
當前,擴散模型在不同領域的應用,需要高吞吐量和低延遲的擴散管道,以確保高效的人機交互。
一個典型的例子是,用擴散模型創建虛擬角色VTuber——能夠對用戶的輸入做出流暢的反應。

為了提高高吞吐量和實時交互能力,目前研究的方向主要集中在,減少去噪迭代次數,比如從50次迭代減少到幾次,甚至一次。
常見的策略是將多步擴散模型提煉成幾個步驟,用神經常微分方程(ODE)重新構建擴散過程。為提高效率,也有人對擴散模型進行了量化。
最新論文中,研究人員從正交方向(orthogonal direction)開始,引入了StreamDiffusion——一種實時擴散管道,專為互動式圖像生成的高吞吐量而設計。
現有的模型設計工作仍然可以與StreamDiffusion集成。另外,它還可以在保持高吞吐量的同時,使用N步去噪擴散模型,并為用戶提供更靈活的選擇。

實時圖像生成|第一列和第二列:AI輔助實時繪圖的示例,第三列:從3D頭像實時渲染2D插圖。第四列和第五列:實時相機濾鏡
具體是如何實現的?
StreamDiffusion架構
StreamDiffusion是一種新的擴散管道,旨在提高吞吐量。
它由若干關鍵部分組成:
流批處理策略、剩余無分類器引導(RCFG)、輸入輸出隊列、隨機相似濾波(Stochastic Similarity Filter)、預計算程序、微型自動編碼器的模型加速工具。
批處理去噪
在擴散模型中,去噪步驟是按順序進行的,這就導致了U-Net的處理時間,與步驟數成比例增加。
然而,為了生成高保真的圖像,就不得不增加步數。
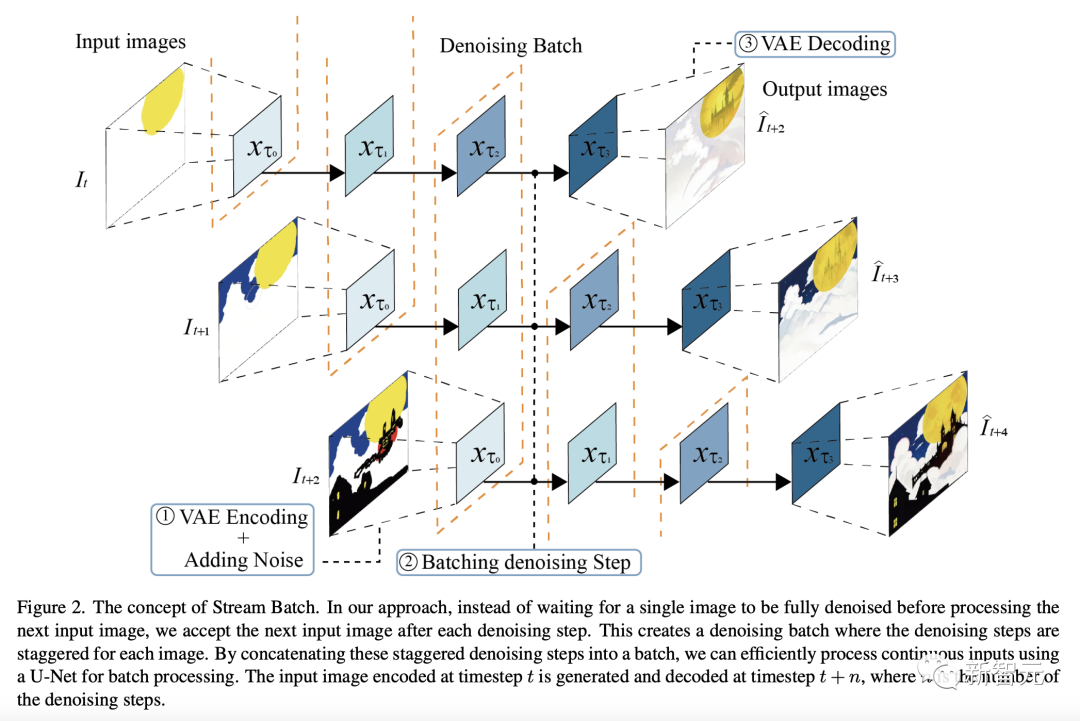
為了解決交互式擴散中的高延遲生成的問題,研究人員提出了一種叫做Stream Batch的方法。
如下圖所示,在最新的方法中,在處理下一個輸入圖像之前,不會等待單個圖像完全去噪,而是在每個去噪步驟后接受下一個輸入圖像。
這樣就形成了一個去噪批次,每個圖像的去噪步驟交錯進行。
通過將這些交錯的去噪步驟串聯成一個批次,研究人員就能使用U-Net高效地處理連續輸入的批次。
在時間步t處編碼的輸入圖像在時間步t+n處生成并解碼,其中n是去噪步驟的數目。
剩余無分類器引導(RCFG)
常見的無分類器指導(CFG)是一種,通過在無條件或否定條件項和原條件項之間執行向量計算。來增強原條件的效果的算法。
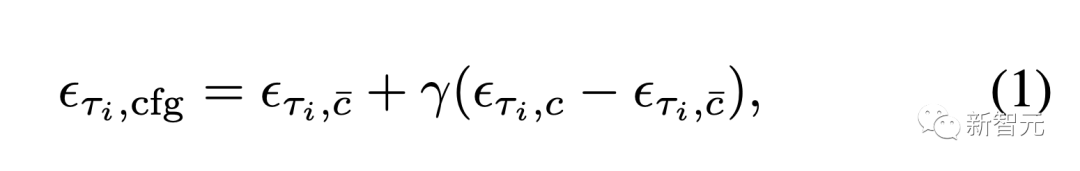
這可以帶來諸如加強提示的效果之類的好處。
然而,為了計算負條件剩余噪聲,需要將每個輸入潛變量與負條件嵌入配對,并在每個推理時間將其傳遞給U-Net。
為了解決這一問題,作者引入了創新的剩余無分類器引導(RCFG) 。
該方法利用虛擬剩余噪聲來逼近負條件,使得只需在過程的初始階段就可以計算負條件噪聲,大大降低了負條件嵌入時額外U-Net推理的計算成本。
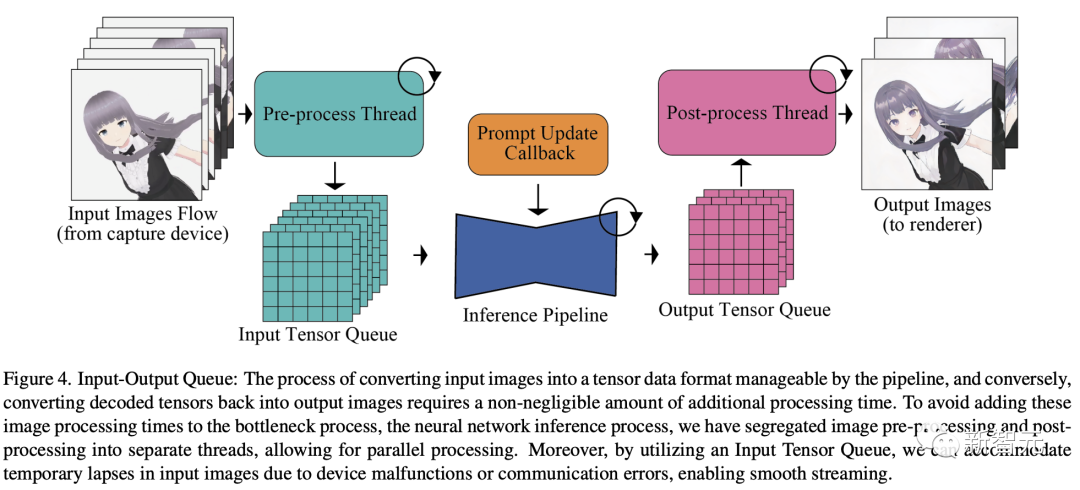
輸入輸出隊列
將輸入圖像轉換為管道可管理的張量數據格式,反過來,將解碼后的張量轉換回輸出圖像,都需要不可忽略的額外處理時間。
為了避免將這些圖像處理時間添加到神經網絡推理流程中,我們將圖像預處理和后處理分離到不同的線程中,從而實現并行處理。
此外,通過使用輸入張量隊列,還能應對因設備故障或通信錯誤造成的輸入圖像臨時中斷,從而實現流暢的流式傳輸。
隨機相似濾波(Stochastic Similarity Filter)
如下圖是,核心擴散推理管道,包含VAE和U-Net。
通過引入去噪批處理和預先計算的提示嵌入緩存、采樣噪聲緩存和調度器值緩存,提高了推理流水線的速度,實現了實時圖像生成。
隨機相似濾波(SSF)是為了節省GPU功耗而設計的,可以動態關閉擴散模型管道,進而實現了快速高效的實時推理。
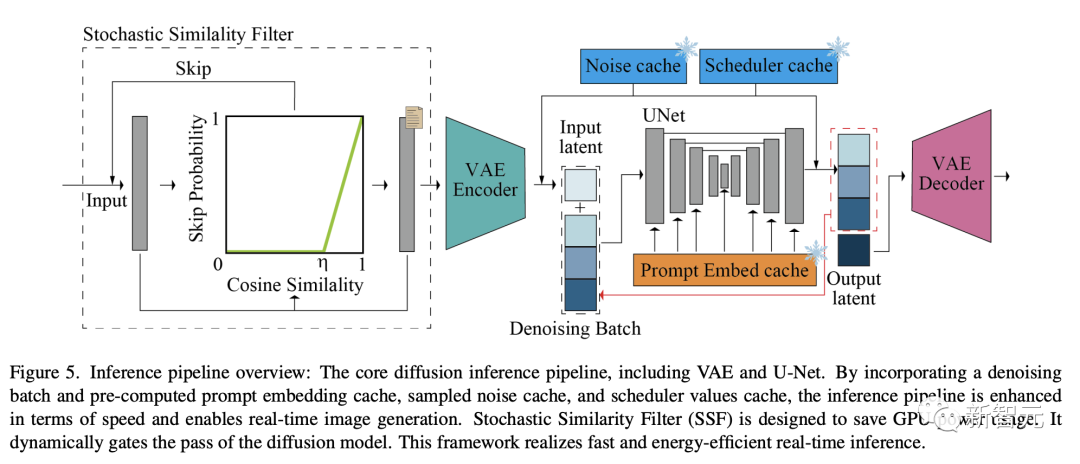
預計算
U-Net架構既需要輸入潛在變量,也需要條件嵌入。
通常情況下,條件嵌入來源于「提示嵌入」,在不同幀之間保持不變。
為了優化這一點,研究人員預先計算提示嵌入,并將其存儲在緩存中。在交互或流模式下,這個預先計算的提示嵌入緩存會被召回。
在U-Net中,每一幀的鍵和值都是根據預先計算的提示嵌入計算的。
因此,研究人員對U-Net進行修改,以存儲這些鍵和值對,使其可以重復使用。每當輸入提示更新時,研究人員都會在U-Net內重新計算和更新這些鍵和值對。
模型加速和微型自動編碼器
為了優化速度,我們將系統配置為使用靜態批大小和固定輸入大小(高度和寬度)。
這種方法確保計算圖和內存分配針對特定的輸入大小進行優化,從而加快處理速度。
然而,這意味著如果需要處理不同形狀的圖像(即不同的高度和寬度),使用不同的批大小(包括去噪步驟的批次大小)。
實驗評估
去噪批的定量評估
圖8顯示了批去噪和原始順序U-Net循環的效率比較。
在實施批去噪策略時,研究人員發現處理時間有了顯著改善。與順序去噪步驟的傳統U-Net循環相比,減少了一半的時間。
即使應用了神經模塊加速工具TensorRT,研究人員提出的流批處理在不同的去噪步驟中仍能大幅提高原始順序擴散管道的效率。
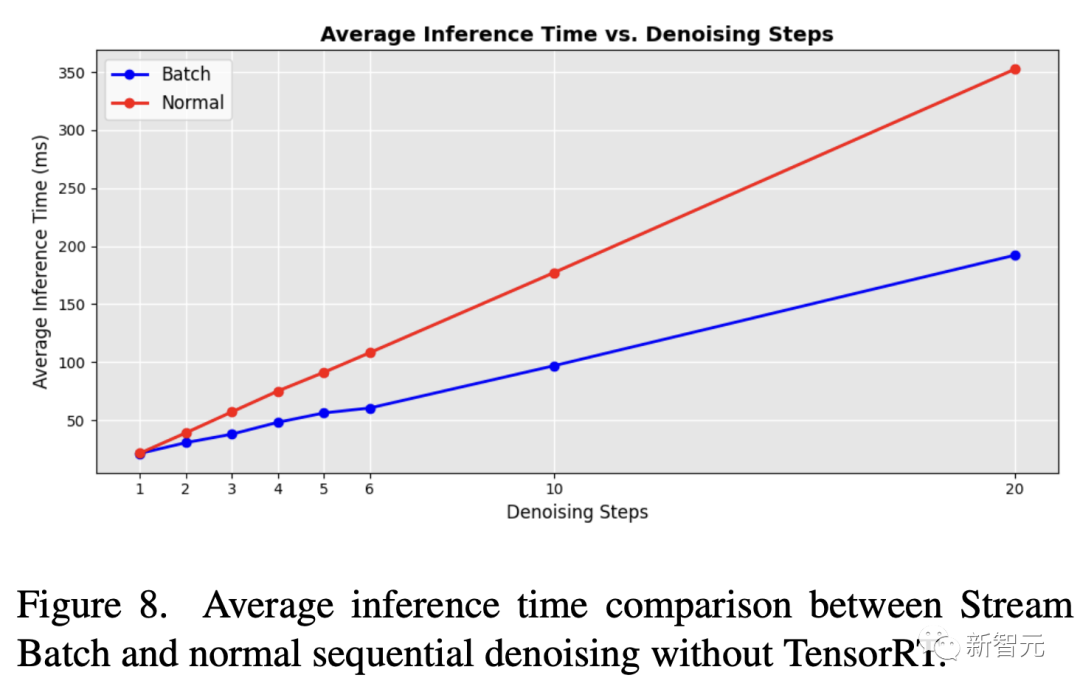
此外,研究人員還將最新方法與Huggingface Diffusers開發的AutoPipeline-ForImage2Image管道進行了比較。
平均推理時間比較見表1,最新管道顯示速度有了大幅提升。
當使用TensorRT時,StreamDiffusion在運行10個去噪步驟時,實現了13倍的速度提升。而在涉及單個去噪步驟的情況下,速度提升可達59.6倍。
即使沒有TensorRT,StreamDiffusion在使用單步去噪時也比AutoPipeline提高了29.7倍,在使用10步去噪時提高了8.3倍。

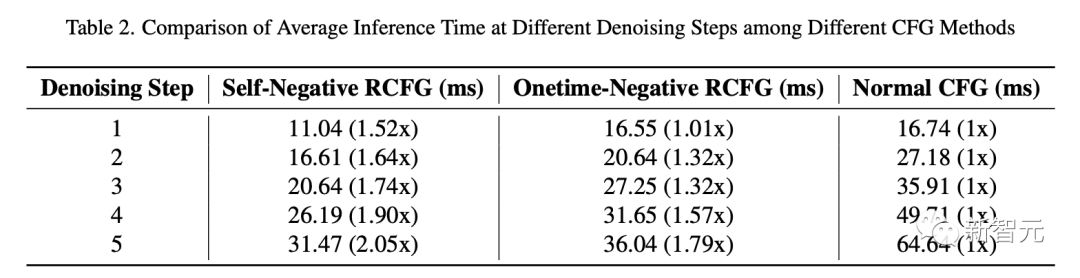
表2比較了使用RCFG和常規CFG的流擴散管道的推理時間。
在單步去噪的情況下,Onetime-Negative RCFG和傳統CFG的推理時間幾乎相同。
所以One-time RCFG和傳統CFG在單步去噪時推理時間差不多。但是隨著去噪步驟增加,從傳統CFG到RCFG的推理速度提升變得更明顯。
在第5步去噪時,Self-Negative RCFG比傳統CFG快2.05倍,Onetime-Negative RCFG比傳統CFG快1.79倍。
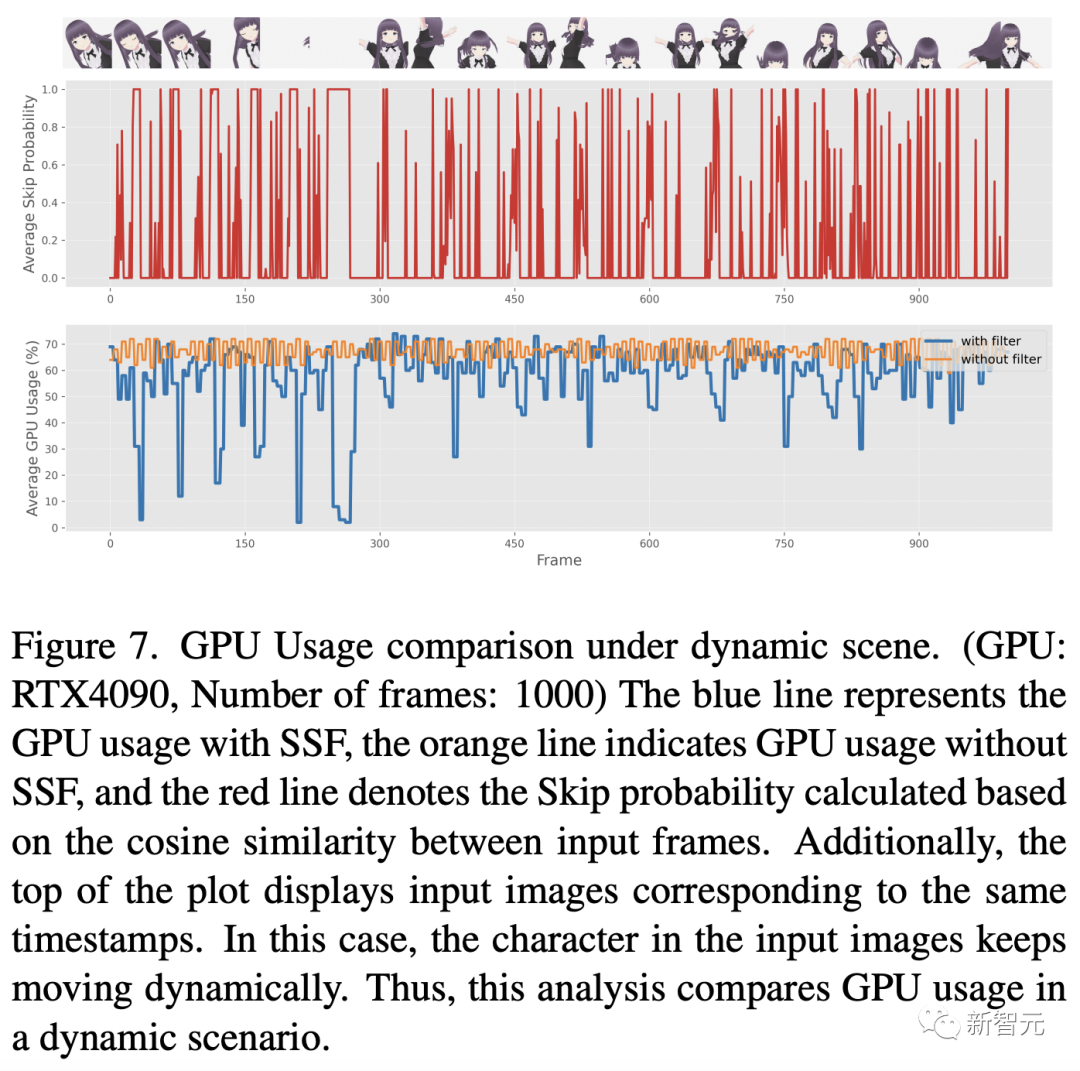
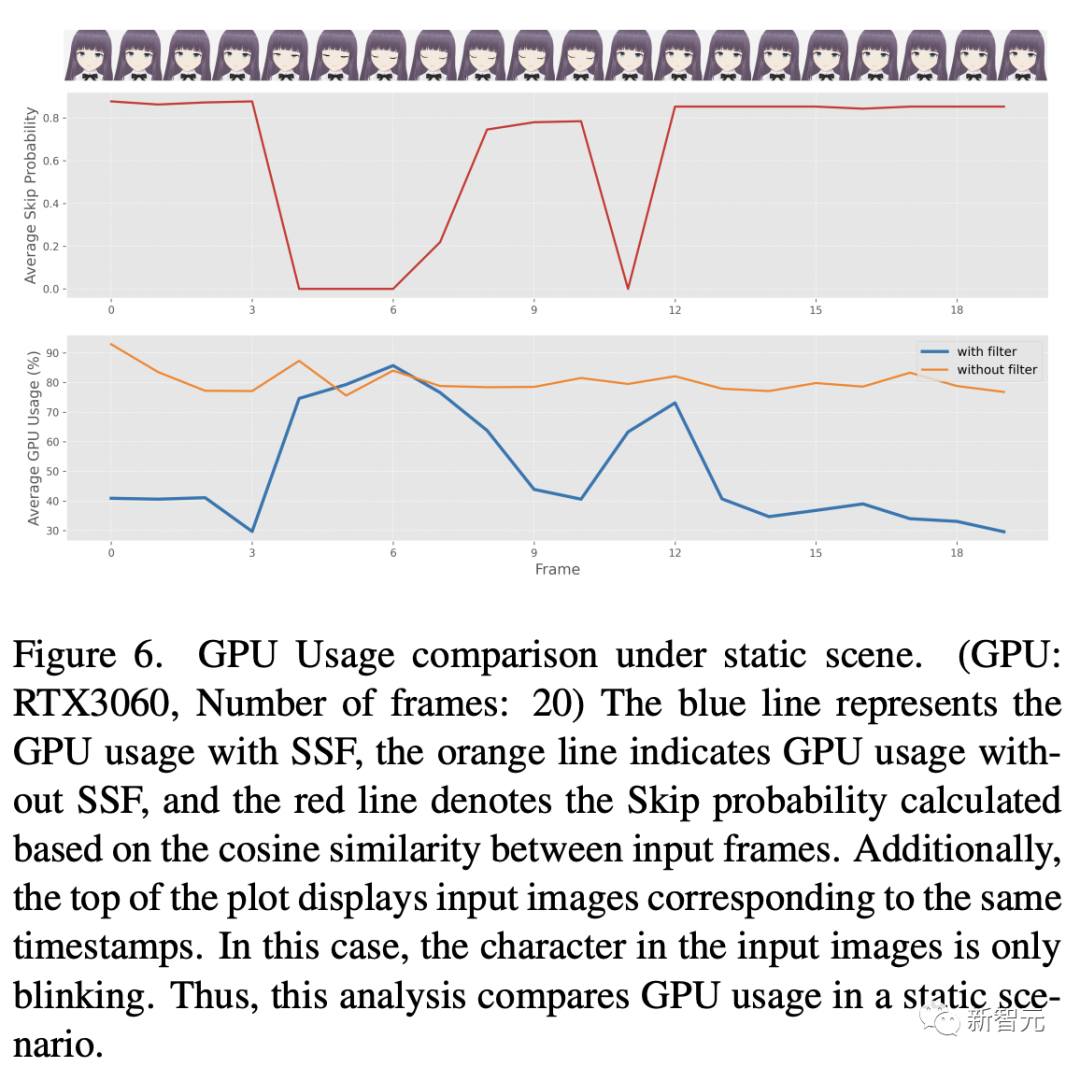
然后,研究人員對所提出的SSF的能耗進行了全面評估,如圖6和圖7所示。
這些圖提供了將 SSF(閾值η設為0.98)應用于包含周期性靜態特征場景的輸入視頻時GPU的使用模式。
對比分析表明,在輸入圖像主要是靜態圖像且具有高度相似性的情況下,采用SSF可以顯著降低GPU的使用率。
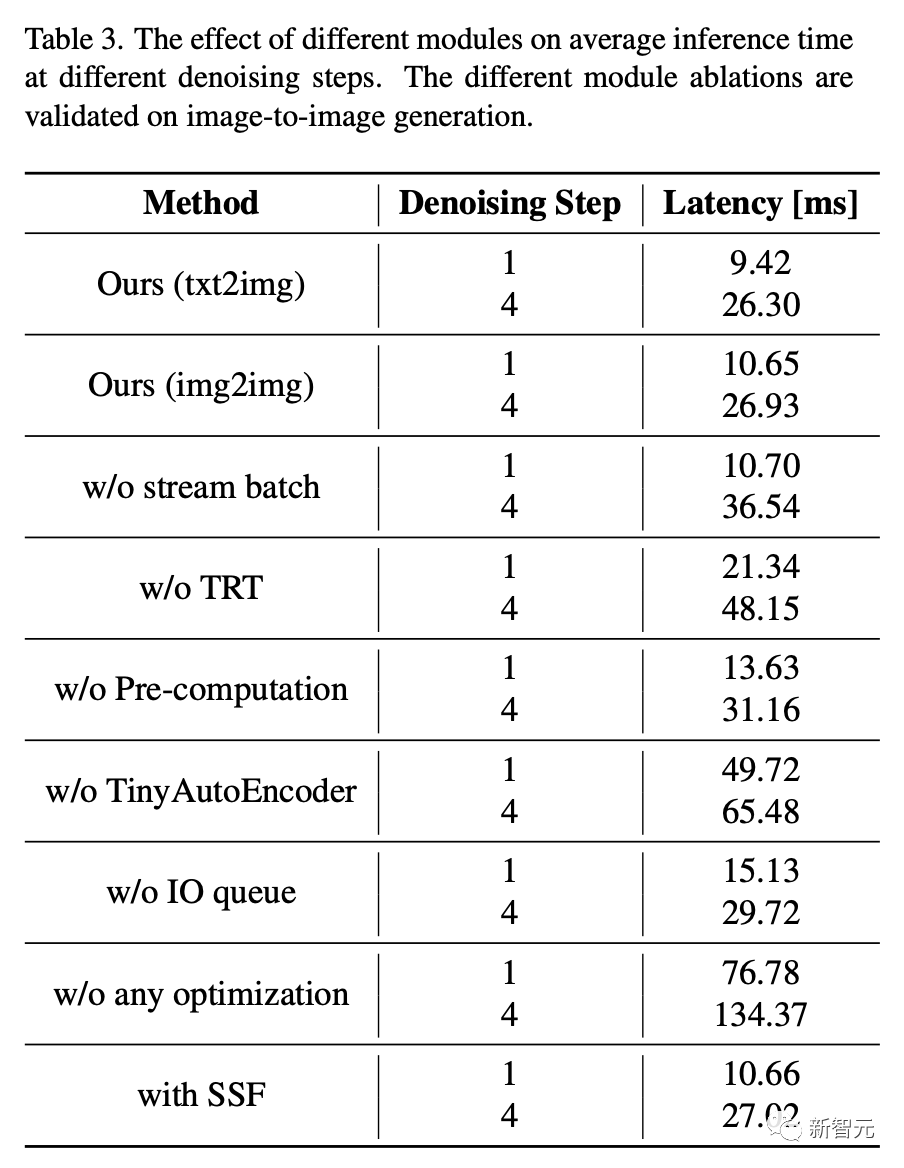
消融研究
不同模塊對不同去噪步驟下平均推理時間的影響如表3。可以看得見,不同模塊的消減在圖像到圖像的生成過程中得到了驗證。
定性結果
圖10展示了使用剩余無分類器導引(RCFG)對生成的圖像進行快速條件調整的對齊過程。
生成的圖像,沒有使用任何形式的CFG,顯示弱對齊提示,特別是在方面,如顏色變化或添加不存在的元素,這是沒有得到有效實現。
相比之下,CFG或RCFG的使用增強了修改原始圖像的能力,例如改變頭發顏色,添加身體模式,甚至包含像眼鏡這樣的物體。值得注意的是,與標準CFG相比,RCFG的使用可以加強提示的影響。

最后,標準文本到圖像生成結果的質量如圖11所示。
使用sd-turbo模型,只需一步就可以生成像圖11所示的那樣的高質量圖像。
當在 GPU: RTX 4090,CPU: Core i9-13900K,OS: Ubuntu 22.04.3 LTS的環境中,使用研究人員提出的流擴散管道和sd-turbo模型生成圖像時,以超100fps的速率生成這種高質量的圖像是可行的。

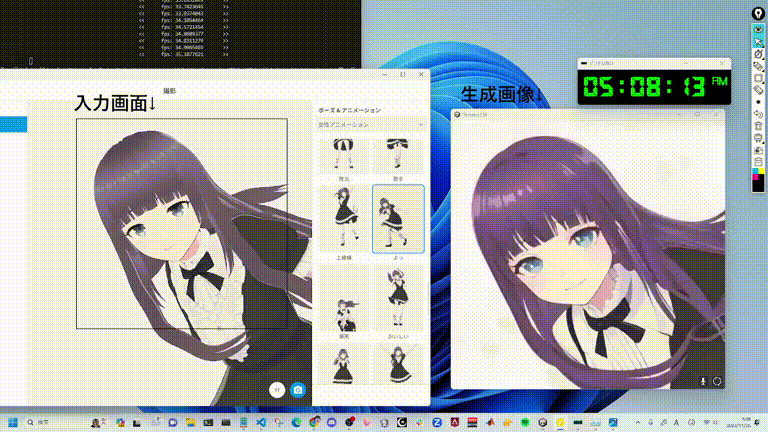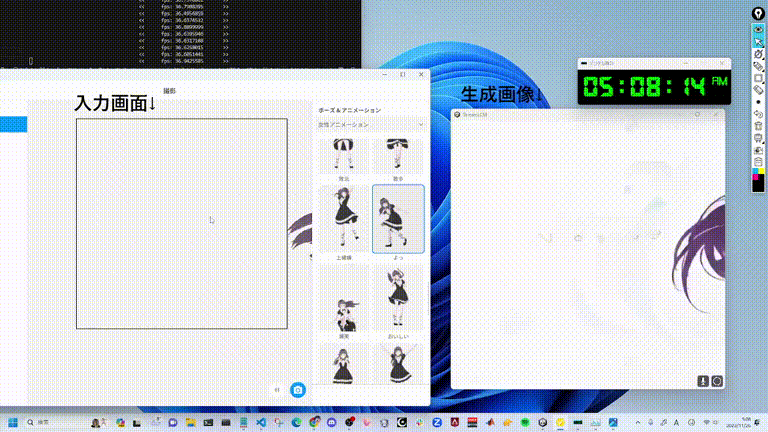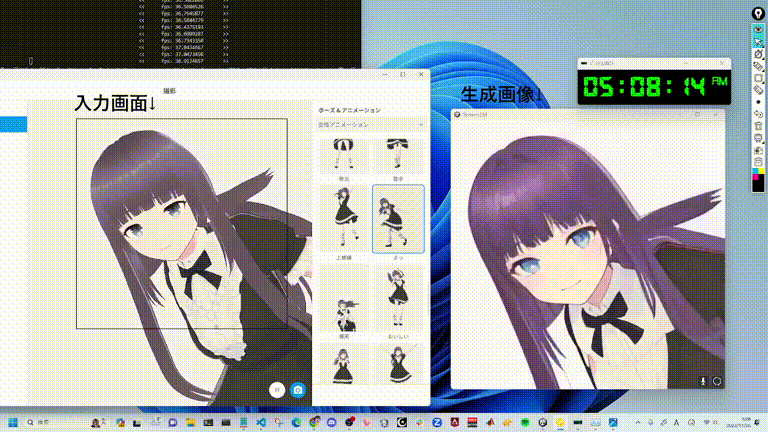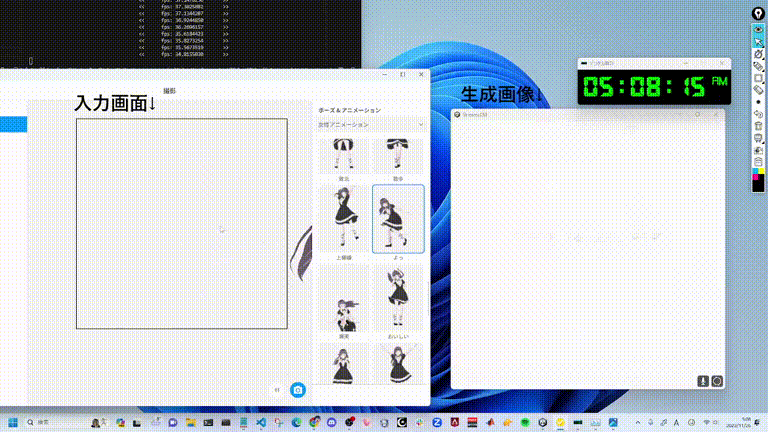
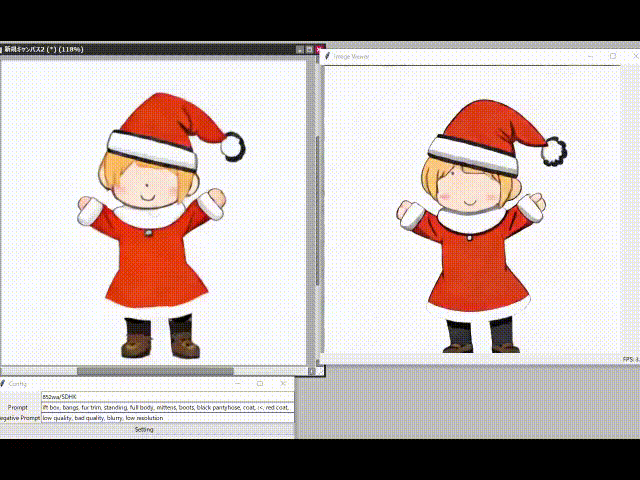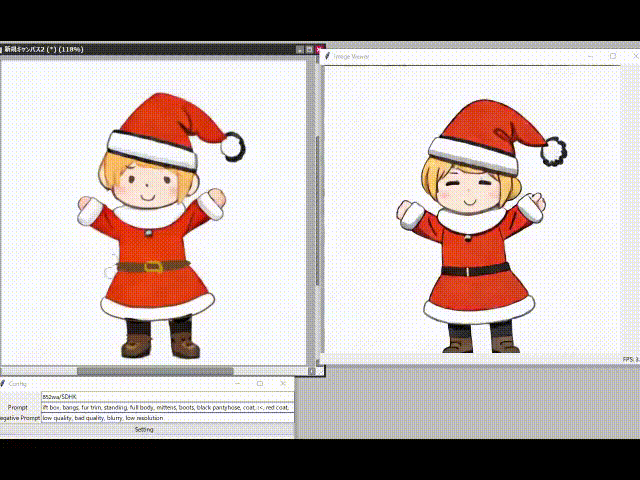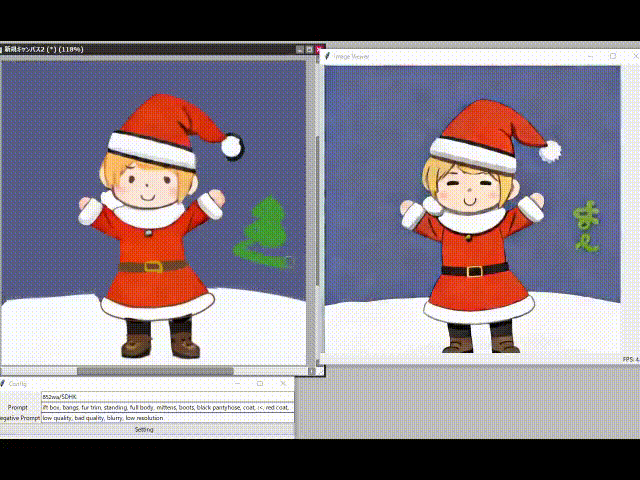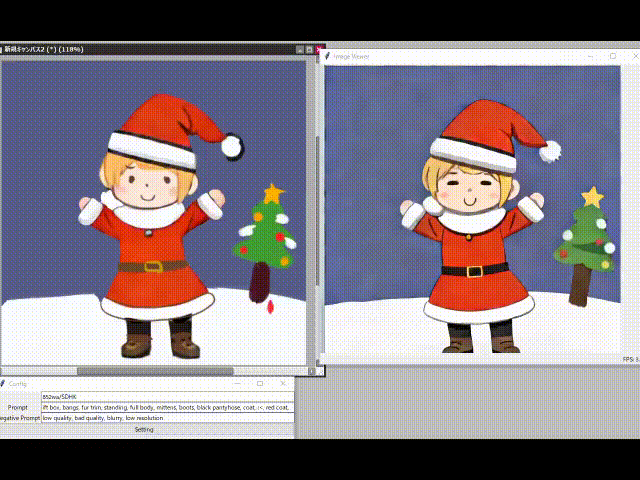
網友上手,一大波二次元小姐姐來了
最新項目的代碼已經開源,在Github已經收攬3.7k星。
項目地址:https://github.com/cumulo-autumn/StreamDiffusion
許多網友已經開始生成自己的二次元老婆了。

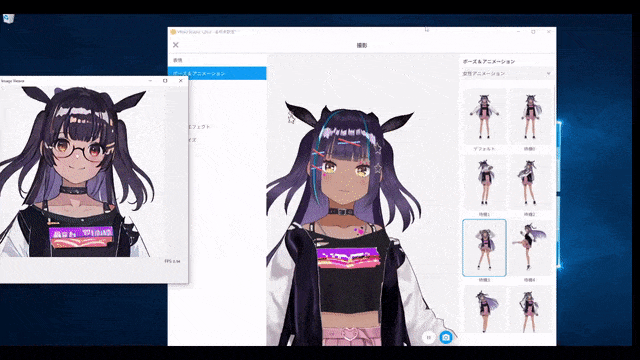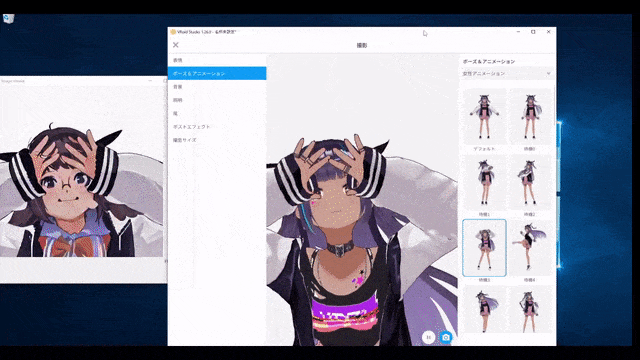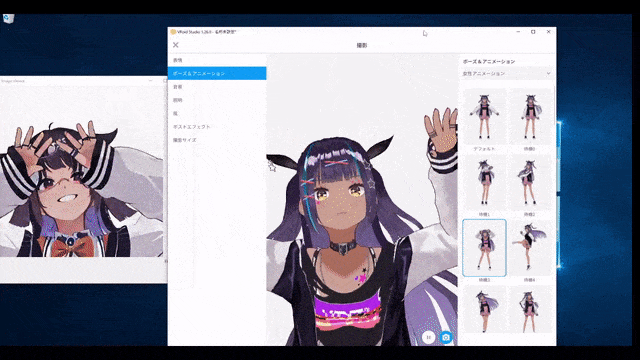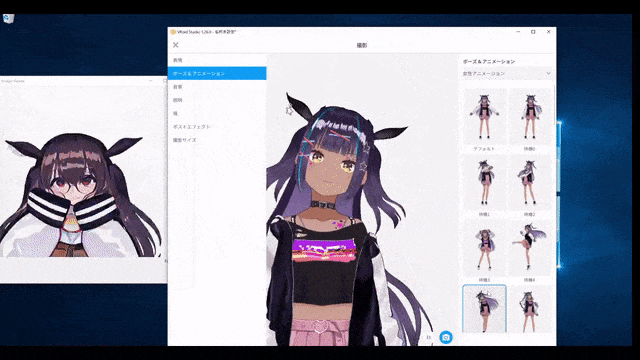
還有真人變實時動畫。
感興趣的童鞋們,不如自己動手吧。






























