













豆包大模型團隊開源RLHF框架,訓練吞吐量最高提升20倍
強化學習(RL)對大模型復雜推理能力提升有關鍵作用,但其復雜的計算流程對訓練和部署也帶來了巨大挑戰。近日,字節跳動豆包大模型團隊與香港大學聯合提出 HybridFlow。這是一個靈活高效的 RL/RLHF 框架,可顯著提升訓練吞吐量,降低開發和維護復雜度。實驗結果表明,HybridFlow 在各種模型規模和 RL 算法下,訓練吞吐量相比其他框架提升了 1.5 倍至 20 倍。
在大模型后訓練(Post-Training)階段引入 RL 方法,已成為提升模型質量和對齊人類偏好的重要手段。然而,隨著模型規模的不斷擴大,RL 算法在大模型訓練中面臨著靈活性和性能的雙重挑戰。傳統的 RL/RLHF 系統在靈活性和效率方面存在不足,難以適應不斷涌現的新算法需求,無法充分發揮大模型潛力。
據豆包大模型團隊介紹,HybridFlow 采用混合編程模型,將單控制器的靈活性與多控制器的高效性相結合,解耦了控制流和計算流。基于 Ray 的分布式編程、動態計算圖、異構調度能力,通過封裝單模型的分布式計算、統一模型間的數據切分,以及支持異步 RL 控制流,HybridFlow 能夠高效地實現和執行各種 RL 算法,復用計算模塊和支持不同的模型部署方式,大大提升了系統的靈活性和開發效率。
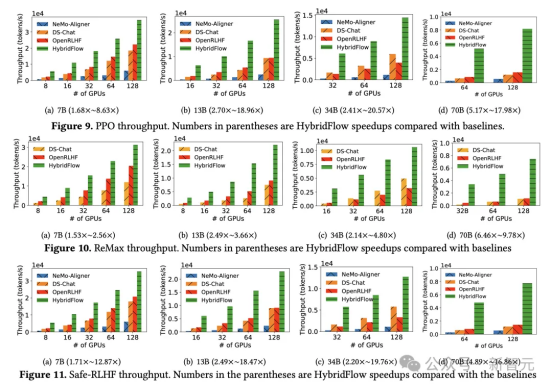
實驗結果顯示,無論 PPO 、ReMax 還是 Safe-RLHF 算法,HybridFlow 在所有模型規模下平均訓練吞吐量均大幅領先于其他框架,提升幅度在 1.5 倍至 20 倍之間。隨著 GPU 集群規模擴大,HybridFlow 吞吐量也獲得良好擴展。這得益于其靈活的模型部署,充分利用硬件資源,實現高效并行計算。同時,HybridFlow 能夠支持多種分布式并行框架(Megatron-LM 、FSDP 、vLLM ),滿足不同模型規模的計算需求。
隨著 o1 模型誕生,大模型 Reasoning 能力和 RL 愈發受到業界關注。豆包大模型團隊表示,將繼續圍繞相關場景進行探索和實驗。目前,HybridFlow 研究論文已入選學術頂會 EuroSys 2025,代碼也已對外開源。
HybridFlow開源鏈接:https://github.com/volcengine/veRL





























