













給Transformer降降秩,移除特定層90%以上組件,LLM性能不減
在大模型時代,Transformer 憑一己之力撐起了整個科研領域。自發布以來,基于 Transformer 的 LLM 在各種任務上表現出卓越的性能,其底層的 Transformer 架構已成為自然語言建模和推理的最先進技術,并在計算機視覺和強化學習等領域顯示出強有力的前景。
然而,當前 Transformer 架構非常龐大,通常需要大量計算資源來進行訓練和推理。
這是有意為之的,因為經過更多參數或數據訓練的 Transformer 顯然比其他模型更有能力。盡管如此,越來越多的工作表明,基于 Transformer 的模型以及神經網絡不需要所有擬合參數來保留其學到的假設。
一般來講,在訓練模型時大規模過度參數化似乎很有幫助,但這些模型可以在推理之前進行大幅剪枝;有研究表明神經網絡通常可以去除 90% 以上的權重,而性能不會出現任何顯著下降。這種現象促使研究者開始轉向有助于模型推理的剪枝策略研究。
來自 MIT、微軟的研究者在論文《 The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction 》中提出了一個令人驚訝的發現,即在 Transformer 模型的特定層上進行仔細的剪枝可以顯著提高模型在某些任務的性能。

- 論文地址:https://arxiv.org/pdf/2312.13558.pdf
- 論文主頁:https://pratyushasharma.github.io/laser/
該研究將這種簡單的干預措施稱之為 LASER( LAyer SElective Rank reduction ,層選擇性降秩),通過奇異值分解來選擇性地減少 Transformer 模型中特定層的學習權重矩陣的高階分量,從而顯著提高 LLM 的性能,這種操作可以在模型訓練完成后進行,并且不需要額外的參數或數據。
操作過程中,權重的減少是在模型特定權重矩陣和層中執行的,該研究還發現許多類似矩陣都可以顯著減少權重,并且在完全刪除 90% 以上的組件之前通常不會觀察到性能下降。
該研究還發現這些減少可以顯著提高準確率,這一發現似乎不僅限于自然語言,在強化學習中也發現了性能提升。
此外,該研究嘗試推斷出高階組件中存儲的內容是什么,以便進行刪除從而提高性能。該研究發現經過 LASER 回答正確的問題,但在干預之前,原始模型主要用高頻詞 (如 “the”、“of” 等) 來回應,這些詞甚至與正確答案的語義類型都不相同,也就是說這些成分在未經干預的情況下會導致模型生成一些不相干的高頻詞匯。
然而,通過進行一定程度的降秩后,模型的回答可以轉變為正確的。
為了理解這一點,該研究還探索了其余組件各自編碼的內容,他們僅使用其高階奇異向量來近似權重矩陣。結果發現這些組件描述了與正確答案相同語義類別的不同響應或通用高頻詞。
這些結果表明,當嘈雜的高階分量與低階分量組合時,它們相互沖突的響應會產生一種平均答案,這可能是不正確的。圖 1 直觀地展示了 Transformer 架構和 LASER 遵循的程序。在這里,特定層的多層感知器(MLP)的權重矩陣被替換為其低秩近似。
LASER 概覽
研究者詳細介紹了 LASER 干預。單步 LASER 干預由包含參數 τ、層數?和降秩 ρ 的三元組 (τ, ?, ρ) 定義。這些值共同描述了哪個矩陣會被它們的低秩近似所替代以及近似的嚴格程度。研究者依賴參數類型對他們將要干預的矩陣類型進行分類。
研究者重點關注 W = {W_q, W_k, W_v, W_o, U_in, U_out} 中的矩陣,它由 MLP 和注意力層中的矩陣組成。層數表示了研究者干預的層(第一層從 0 開始索引)。例如 Llama-2 有 32 層,因此 ? ∈ {0, 1, 2,???31}。
最終,ρ ∈ [0, 1) 描述了在做低秩近似時應該保留最大秩的哪一部分。例如設 ,則該矩陣的最大秩為 d。研究者將它替換為?ρ?d?- 近似。
,則該矩陣的最大秩為 d。研究者將它替換為?ρ?d?- 近似。
下圖 1 為 LASER 示例,該圖中,τ = U_in 和? = L 表示在 L^th 層的 Transformer 塊中來更新 MLP 第一層的權重矩陣。另一個參數控制 rank-k 近似中的 k。

LASER 可以限制網絡中某些信息的流動,并出乎意料地產生顯著的性能優勢。這些干預也可以很容易組合起來,比如以任何順序來應用一組干預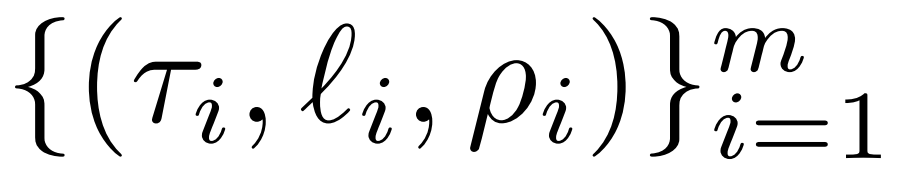 。
。
LASER 方法只是對這類干預進行簡單的搜索,并修改以帶來最大收益。不過,還有很多其他方法可以將這些干預組合起來,這是研究者未來工作的方向。
實驗結果
在實驗部分,研究者使用了在 PILE 數據集上預訓練的 GPT-J 模型,該模型的層數為 27,參數為 60 億。然后在 CounterFact 數據集上評估模型的行為,該數據集包含(主題、關系和答案)三元組的樣本,每個問題提供了三個釋義 prompt。
首先是 CounterFact 數據集上對 GPT-J 模型的分析。下圖 2 展示了在 Transformer 架構中為每個矩陣應用不同數量降秩的結果對數據集分類損失的影響。其中每個 Transformer 層都由一個兩層的小型 MLP 組成,輸入和輸出矩陣分別顯示。不同的顏色表示移除組件的不同百分比。
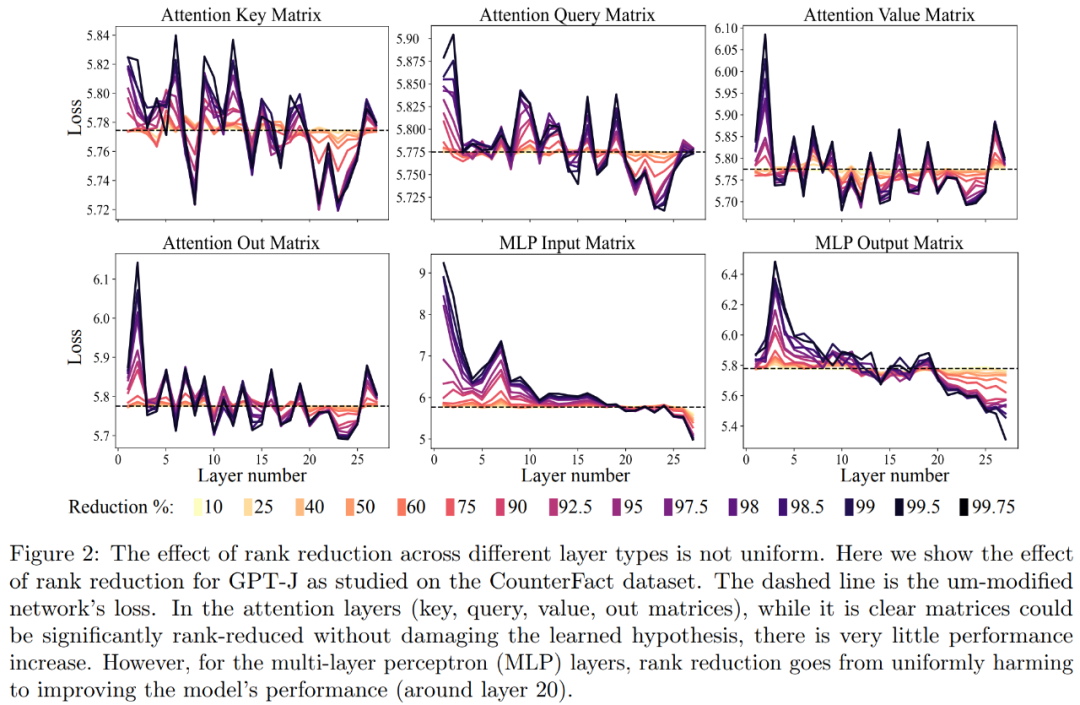
關于提升釋義的準確度和穩健性,如上圖 2 和下表 1 所示,研究者發現,當在單層上進行降秩時,GPT-J 模型在 CounterFact 數據集上的事實準確度從 13.1% 增加到了 24.0%。需要注意一點,這些改進只是降秩的結果,并不涉及對模型的任何進一步訓練或微調。

數據集中的哪些事實會通過降秩恢復呢?研究者發現,通過降秩恢復的事實極大可能很少出現在數據中,如下圖 3 所示。

高階組件存儲什么呢?研究者使用高階組件近似最終的權重矩陣(而不像 LASER 那樣使用低階組件來近似),如下圖 5 (a) 所示。當使用不同數量的高階組件來近似矩陣時,他們測量了真實答案相對于預測答案的平均余弦相似度,如下圖 5 (b) 所示。

最后,研究者評估了自身發現對 3 種不同的 LLM 在多項語言理解任務上的普遍性。對于每項任務,他們通過生成準確度、分類準確度和損失三種指標來評估模型的性能。如上表 1 所示,即使降秩很大也不會導致模型準確度下降,卻可以提升模型性能。




















