MLX vs MPS vs CUDA:蘋果新機器學習框架的基準測試
如果你是一個Mac用戶和一個深度學習愛好者,你可能希望在某些時候Mac可以處理一些重型模型。蘋果剛剛發布了MLX,一個在蘋果芯片上高效運行機器學習模型的框架。
最近在PyTorch 1.12中引入MPS后端已經是一個大膽的步驟,但隨著MLX的宣布,蘋果還想在開源深度學習方面有更大的發展。

在本文中,我們將對這些新方法進行測試,在三種不同的Apple Silicon芯片和兩個支持cuda的gpu上和傳統CPU后端進行基準測試。
這里把基準測試集中在圖卷積網絡(GCN)模型上。這個模型主要由線性層組成,所以對于其他的模型也應該得到類似的結果。
創造環境
要為MLX構建環境,我們必須指定是使用i386還是arm架構。使用conda,可以使用:
CONDA_SUBDIR=osx-arm64 conda create -n mlx pythnotallow=3.10 numpy pytorch scipy requests -c conda-forge
conda activate mlx如果檢查你的env是否實際使用了arm,下面命令的輸出應該是arm,而不是i386(因為我們用的Apple Silicon):
python -c "import platform; print(platform.processor())"然后就是使用pip安裝MLX:
pip install mlxGCN模型
GCN模型是圖神經網絡(GNN)的一種,它使用鄰接矩陣(表示圖結構)和節點特征。它通過收集鄰近節點的信息來計算節點嵌入。每個節點獲得其鄰居特征的平均值。這種平均是通過將節點特征與標準化鄰接矩陣相乘來完成的,并根據節點度進行調整。為了學習這個過程,特征首先通過線性層投射到嵌入空間中。
我們將使用MLX實現一個GCN層和一個GCN模型:
import mlx.nn as nn
class GCNLayer(nn.Module):
def __init__(self, in_features, out_features, bias=True):
super(GCNLayer, self).__init__()
self.linear = nn.Linear(in_features, out_features, bias)
def __call__(self, x, adj):
x = self.linear(x)
return adj @ x
class GCN(nn.Module):
def __init__(self, x_dim, h_dim, out_dim, nb_layers=2, dropout=0.5, bias=True):
super(GCN, self).__init__()
layer_sizes = [x_dim] + [h_dim] * nb_layers + [out_dim]
self.gcn_layers = [
GCNLayer(in_dim, out_dim, bias)
for in_dim, out_dim in zip(layer_sizes[:-1], layer_sizes[1:])
]
self.dropout = nn.Dropout(p=dropout)
def __call__(self, x, adj):
for layer in self.gcn_layers[:-1]:
x = nn.relu(layer(x, adj))
x = self.dropout(x)
x = self.gcn_layers[-1](x, adj)
return x可以看到,mlx的模型開發方式與tf2基本一樣,都是調用__call__進行前向傳播,其實torch也一樣,只不過它自定義了一個forward函數。
下面就是訓練:
gcn = GCN(
x_dim=x.shape[-1],
h_dim=args.hidden_dim,
out_dim=args.nb_classes,
nb_layers=args.nb_layers,
dropout=args.dropout,
bias=args.bias,
)
mx.eval(gcn.parameters())
optimizer = optim.Adam(learning_rate=args.lr)
loss_and_grad_fn = nn.value_and_grad(gcn, forward_fn)
# Training loop
for epoch in range(args.epochs):
# Loss
(loss, y_hat), grads = loss_and_grad_fn(
gcn, x, adj, y, train_mask, args.weight_decay
)
optimizer.update(gcn, grads)
mx.eval(gcn.parameters(), optimizer.state)
# Validation
val_loss = loss_fn(y_hat[val_mask], y[val_mask])
val_acc = eval_fn(y_hat[val_mask], y[val_mask])在MLX中,計算是惰性的,這意味著eval()通常用于在更新后實際計算新的模型參數。而另一個關鍵函數是nn.value_and_grad(),它生成一個計算參數損失的函數。第一個參數是保存當前參數的模型,第二個參數是用于前向傳遞和損失計算的可調用函數。它返回的函數接受與forward函數相同的參數(在本例中為forward_fn)。我們可以這樣定義這個函數:
def forward_fn(gcn, x, adj, y, train_mask, weight_decay):
y_hat = gcn(x, adj)
loss = loss_fn(y_hat[train_mask], y[train_mask], weight_decay, gcn.parameters())
return loss, y_hat它僅僅包括計算前向傳遞和計算損失。Loss_fn()和eval_fn()定義如下:
def loss_fn(y_hat, y, weight_decay=0.0, parameters=None):
l = mx.mean(nn.losses.cross_entropy(y_hat, y))
if weight_decay != 0.0:
assert parameters != None, "Model parameters missing for L2 reg."
l2_reg = sum(mx.sum(p[1] ** 2) for p in tree_flatten(parameters)).sqrt()
return l + weight_decay * l2_reg
return l
def eval_fn(x, y):
return mx.mean(mx.argmax(x, axis=1) == y)損失函數是計算預測和標簽之間的交叉熵,并包括L2正則化。由于L2正則化還不是內置特性,需要手動實現。
本文的完整代碼:https://github.com/TristanBilot/mlx-GCN
可以看到除了一些細節函數調用的差別,基本的訓練流程與pytorch和tf都很類似,但是這里的一個很好的事情是消除了顯式地將對象分配給特定設備的需要,就像我們在PyTorch中經常使用.cuda()和.to(device)那樣。這是因為蘋果硅芯片的統一內存架構,所有變量共存于同一空間,也就是說消除了CPU和GPU之間緩慢的數據傳輸,這樣也可以保證不會再出現與設備不匹配相關的煩人的運行時錯誤。
基準測試
我們將使用MLX與MPS, CPU和GPU設備進行比較。我們的測試平臺是一個2層GCN模型,應用于Cora數據集,其中包括2708個節點和5429條邊。
對于MLX, MPS和CPU測試,我們對M1 Pro, M2 Ultra和M3 Max進行基準測試。在兩款NVIDIA V100 PCIe和V100 NVLINK上進行測試。
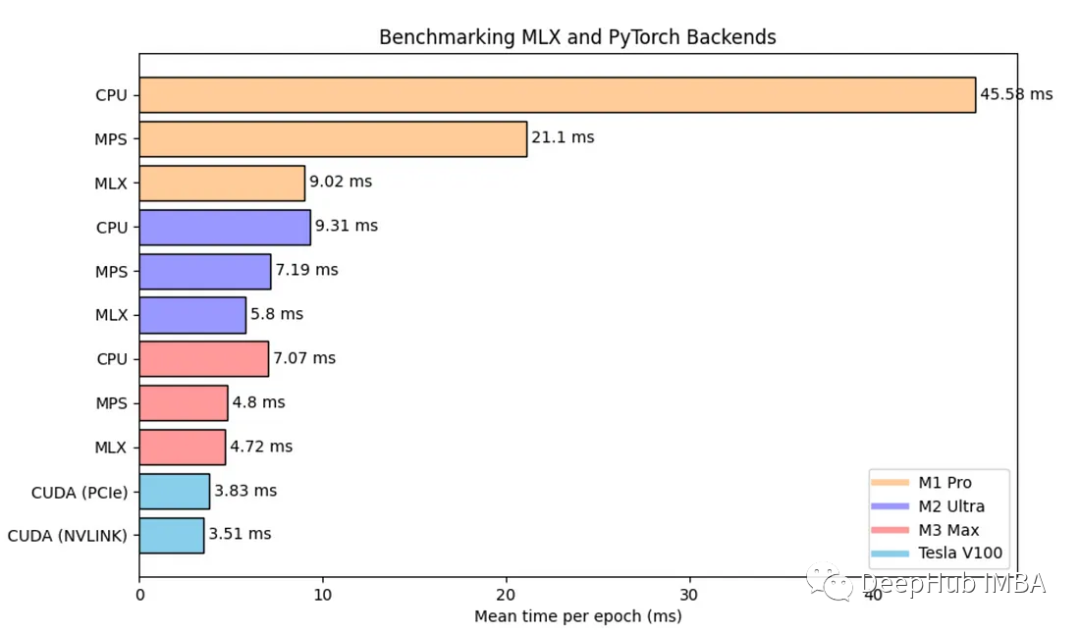
MPS:比M1 Pro的CPU快2倍以上,在其他兩個芯片上,與CPU相比有30-50%的改進。
MLX:比M1 Pro上的MPS快2.34倍。與MPS相比,M2 Ultra的性能提高了24%。在M3 Pro上MPS和MLX之間沒有真正的改進。
CUDA V100 PCIe & NVLINK:只有23%和34%的速度比M3 Max與MLX,這里的原因可能是因為我們的模型比較小,所以發揮不出V100和NVLINK的優勢(NVLINK主要GPU之間的數據傳輸大的情況下會有提高)。這也說明了蘋果的統一內存架構的確可以消除CPU和GPU之間緩慢的數據傳輸。
總結
與CPU和MPS相比,MLX可以說是非常大的金幣,在小數據量的情況下它甚至接近特斯拉V100的性能。也就是說我們可以使用MLX跑一些不是那么大的模型,比如一些表格數據。
從上面的基準測試也可以看到,現在可以利用蘋果芯片的全部力量在本地運行深度學習模型(我一直認為MPS還沒發揮蘋果的優勢,這回MPS已經證明了這一點)。
MLX剛剛發布就已經取得了驚人的影響力,并展示了巨大的潛力。相信未來幾年開源社區的進一步增強,可以期待在不久的將來更強大的蘋果芯片,將MLX的性能提升到一個全新的水平。
另外也說明了MPS(雖然也發布不久)還是有巨大的發展空間的,畢竟切換框架是一件很麻煩的事情,如果MPS能達到MLX 80%或者90%的速度,我想不會有人去換框架的。
最后說到框架,現在已經有了Pytorch,TF,JAX,現在又多了一個MLX。各種設備、各種后端包括:TPU(pytorch使用的XLA),CUDA,ROCM,現在又多了一個MPS。