AI變鑒片大師,星際穿越都能看懂!賈佳亞團隊新作,多模態大模型挑戰超長3小時視頻
啥?AI都能自己看電影大片了?
賈佳亞團隊最新研究成果,讓大模型直接學會了處理超長視頻。
丟給它一部科幻大片《星際穿越》(片長2小時49分鐘):

它“看”完之后,不僅能結合電影情節和人物輕松對電影進行點評:

還能很精準地回答出劇中所涉的細節:
例如:蟲洞的作用和創造者是誰?

答:未來的智慧生物放置在土星附近,用于幫助人類進行遠距離星際穿越。
男主庫珀是如何將黑洞中的信息傳遞給女兒墨菲?

答:通過手表以摩斯號碼的方式傳遞數據。
啊這,感覺電影博主的飯碗也要被AI搶走了。
這就是最新多模態大模型LLaMA-VID,它支持單圖、短視頻和長視頻三種輸入。
對比來看,包括GPT-4V等在內的同類模型基本只能處理圖像。
而背后原理更有看頭。
據介紹,LLaMA-VID只通過一個非常簡單的辦法就達成了如上能力,那就是:
把表示每一幀圖像的token數量,壓縮到僅有2個。
具體效果如何以及如何實現?一起來看。
人物理解分析、電影細節都OK
對于電影來說,除了精準回答所涉細節,LLaMA-VID也能對角色進行十分準確的理解和分析。
還是《星際穿越》,我們讓它看完后分析米勒星球上相對地球時間的快慢及原因。
結果完全正確:
LLaMA-VID表示是因為米勒星球在黑洞附近,導致1小時相當于地球7年。

再丟給它時長近倆小時的《阿甘正傳》。

對于“珍妮對于阿甘有何意義?”這一問題,LLaMA-VID的回答是:
孩童時期的朋友,后來成為阿甘的妻子,是阿甘生活和心靈的慰藉。

對于阿甘在戰爭及退伍后的事件也能進行分析,且回答也很到位:
丹中尉責怪阿甘救了自己,因為這讓他無法戰死沙場。

除了看電影,成為一個無所不知的的“電影搭子”,它也能很好地理解宣傳片的意圖,回答一些開放問題。
比如給它一段最近很火的GTA6預告片。

問它“這個游戲哪里最吸引你?”,它“看”完后給出的想法是:
一是游戲場景和設置非常多(從賽車、特技駕駛到射擊等),二是視覺效果比較驚艷。

哦對了,LLaMA-VID還能根據游戲中的場景和特征,推測出預告片是Rockstar游戲公司的推廣:

以及認出游戲的背景城市為邁阿密(根據夜生活、海灘等信息,以及在作者提示游戲設置在佛羅里達之后)。

最后,在宣傳片、時長高達2-3小時的電影這些視頻材料之外,我們也來看看LLaMA-VID對最基礎的圖片信息的理解能力。
吶,準確識別出這是一塊布料,上面有個洞:

讓它扮演“福爾摩斯”也不在話下。面對這樣一張房間內景照片:

它可以從門上掛了很多外套分析出房間主人可能生活繁忙/經常外出。

看得出來,LLaMA-VID對視頻的準確解讀正是建立在這樣的圖片水準之上的,但最關鍵的點還是它如何完成如此長時間的視頻處理。
幾行代碼實現單幀2 token表示
LLaMA-VID的關鍵創新是將每幀畫面的token數量壓縮到很低,從而實現可處理超長視頻。
很多傳統多模態大模型對于單張圖片編碼的token數量過多,導致了視頻時間加長后,所需token數量暴增,模型難以承受。
為此研究團隊重新設計了圖像的編碼方式,采用上下文編碼(Context Token)和圖像內容編碼(Content Token)來對視頻中的單幀進行編碼。
從而實現了將每一幀用2個token表示。
具體來看LLaMA-VID的框架。
只包含3個部分:
- 采用編解碼器產生視覺嵌入和文本引導特征。
- 根據特定token生成策略轉換上下文token和圖像內容token。
- 指令調優進一步優化。

根據指令,LLaMA-VID選取單個圖像或視頻幀作為輸入,然后從大語言模型上生成回答。
這個過程從一個可視編碼器開始,該編碼器將輸入幀轉換為可視幀嵌入。
然后文本解碼器根據用戶輸入和圖像編碼器提取的特征,來生成與輸入指令相關的跨模態索引(Text Query)。
然后利用注意力機制(Context Attention),將視覺嵌入中和文本相關的視覺線索聚合起來,也就是特征采樣和組合,從而生成高質量的指令相關特征。
為了提高效率,模型將可視化嵌入樣本壓縮到不同token大小,甚至是一個token。
其中,上下文token根據用戶輸入的問題生成,盡可能保留和用戶問題相關的視覺特征。
圖像內容token則直接根據用戶指令對圖像特征進行池化采樣,更關注圖像本身的內容信息,對上下文token未關注到的部分進行補充。
文本引導上下文token和圖像token來一起表示每一幀。
最后,大語言模型將用戶指令和所有視覺token作為輸入,生成回答。
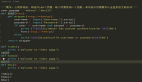
而且這種token的生成方法很簡單,僅需幾行代碼。

實驗結果方面,LLaMA-VID在多個視頻問答和推理榜單上實現SOTA。


僅需加入1個上下文token拓展,LLaMA-VID在多個圖片問答指標上也能獲得顯著提升。

在16個視頻、圖片理解及推理數據集上,LLaMA-VID實現了很好效果。

在GitHub上,團隊提供了不同階段的所有微調模型,以及第一階段的預訓練權重。


具體訓練包括3個過程:特征對齊、指令微調、長視頻微調(相應步驟可參考GitHub)。
此外,LLaMA-VID還收集了400部電影并生成9K條長視頻問答語料,包含電影影評、人物成長及情節推理等。
結合之前賈佳亞團隊所發布的長文本數據集LongAlpaca-12k(9k條長文本問答語料對、3k短文本問答語料對), 可輕松將現有多模態模型拓展來支持長視頻輸入。
值得一提的是,今年8月開始賈佳亞團隊就發布了主攻推理分割的LISA多模態大模型。
10月還發布了長文本開源大語言模型LongAlpaca(70億參數)和超長文本擴展方法LongLoRA。
LongLoRA只需兩行代碼便可將7B模型的文本長度拓展到100k tokens,70B模型的文本長度拓展到32k tokens。
最后,團隊也提供了demo地址,可自己上傳視頻和LLaMA-VID對話(部署在單塊3090,需要的小伙伴可以參考code用更大的顯存部署,直接和整個電影對話)。

看來,以后看不懂諾蘭電影,可以請教AI試
論文地址:https://arxiv.org/abs/2311.17043
GitHub地址:https://github.com/dvlab-research/LLaMA-VID
demo地址:http://103.170.5.190:7864/