













2023年五個自動化EDA庫推薦
EDA或探索性數據分析是一項耗時的工作,但是由于EDA是不可避免的,所以Python出現了很多自動化庫來減少執行分析所需的時間。EDA的主要目標不是制作花哨的圖形或創建彩色的圖形,而是獲得對數據集的理解,并獲得對變量之間的分布和相關性的初步見解。我們在以前也介紹過EDA自動化的庫,但是現在已經過了1年的時間了,我們看看現在有什么新的變化。
為了測試這些庫的功能,本文使用了兩個不同的數據集,只是為了更好地理解這些庫如何處理不同類型的數據。
YData-Profiling
以前被稱為Pandas Profiling,在今年改了名字。如果你搜索任何與EDA自動化相關的內容時,它都會作為第一個結果出現,這也是有充分理由的。
這個庫最有用和最常用的是ProfileReport()命令。它生成整個數據集的詳細摘要,報告對于獲得數據的概覽非常有用,特別是如果你不知道從哪里或如何開始分析(通常是這種情況)。這對于那些想要節省時間的新手或有經驗的分析師來說非常有用。該報告提供單變量分布,突出數據質量問題,并創建相關性。讓我們看一下患者風險概況數據的報告:
patient_data = pd.read_csv('/kaggle/input/patient-risk-profiles/patient_risk_profiles.csv')
zomato_data=pd.read_csv('/kaggle/input/zomato-data-40k-restaurants-of-indias-100-cities/zomato_dataset.csv')
from ydata_profiling import ProfileReport
patient_report=ProfileReport(patient_data)
patient_report
zomato_report=ProfileReport(zomato_data)
zomato_report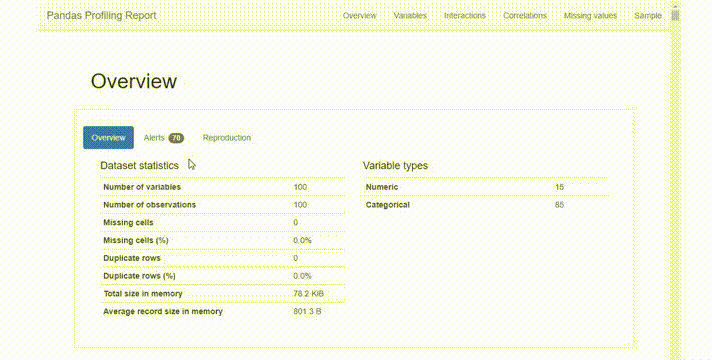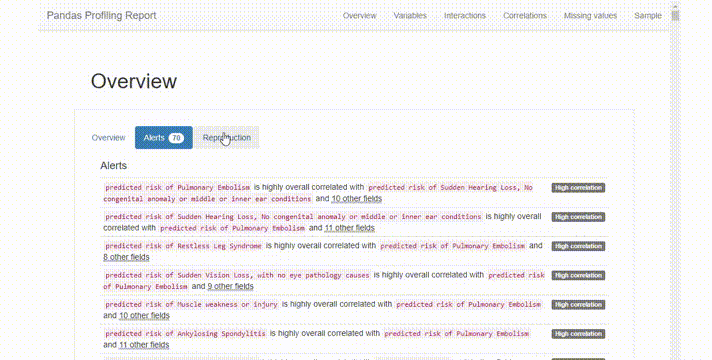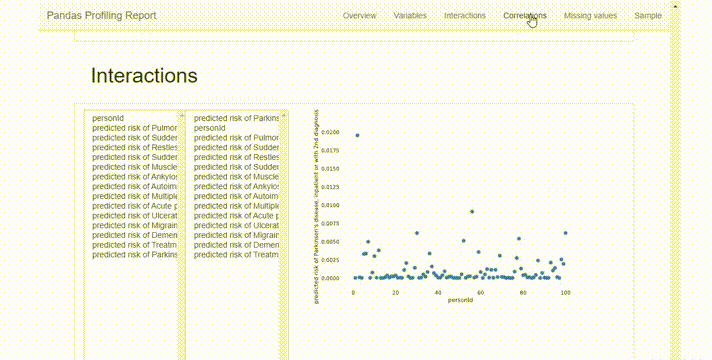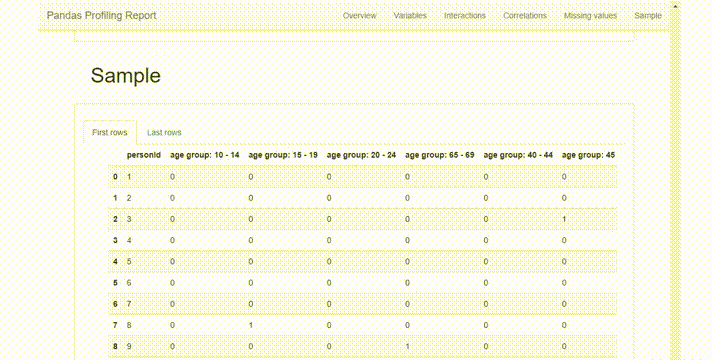
這份報告在很直觀,也非常全面,它提供了一個很好的概述:
變量統計的簡明概述,缺失值的百分比,重復值等。
在Alerts選項卡的簡單文本中高亮顯示數據質量問題,如高相關性,類不平衡等。
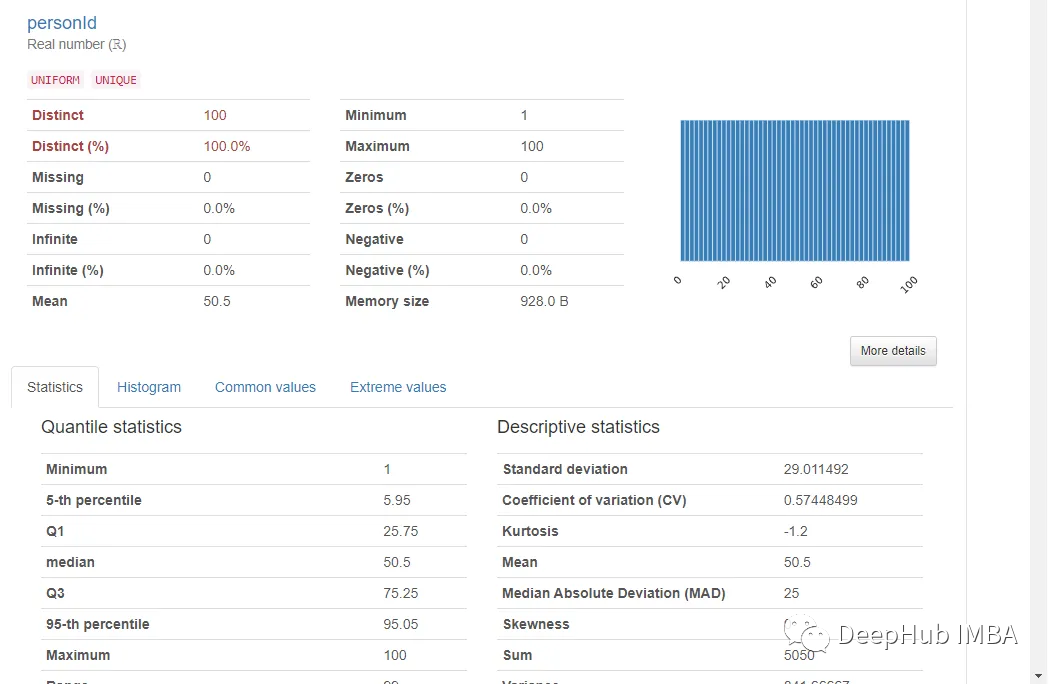
在variables 選項卡中給出了所有變量的單變量分析。有助于了解該變量的分布和統計特性。
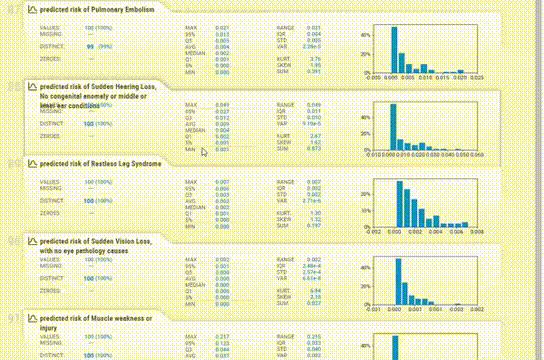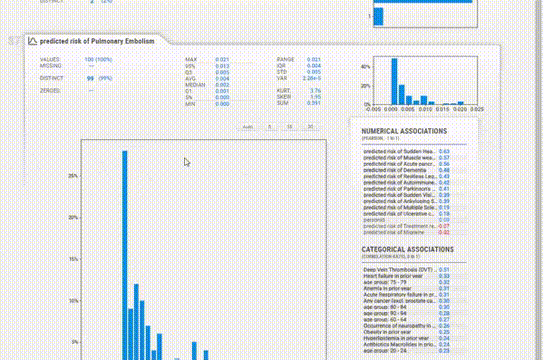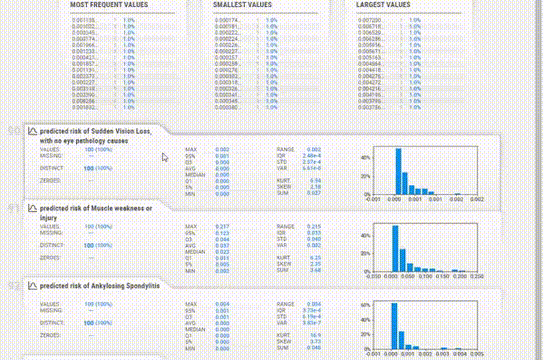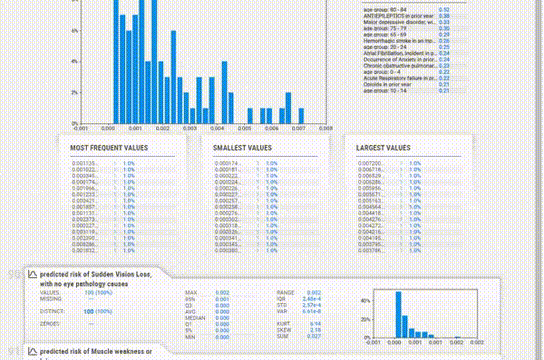
點擊變量下的“More Details”可以提供對各種其他統計數據,直方圖,常見值和極值的更深入分析。基本上包含了一般我們想要知道的所有信息。
對于文本變量,報告生成了一個類似于NLP的概述,如下所示:

Interactions選項卡可以進行雙變量分析,其中x軸變量在左列,y軸變量在右列。可以混搭來觀察變量之間的相關性。這里唯一的限制是可用的圖表類型只有散點圖,所以如果想使用不同類型的圖表,必須手動繪制。
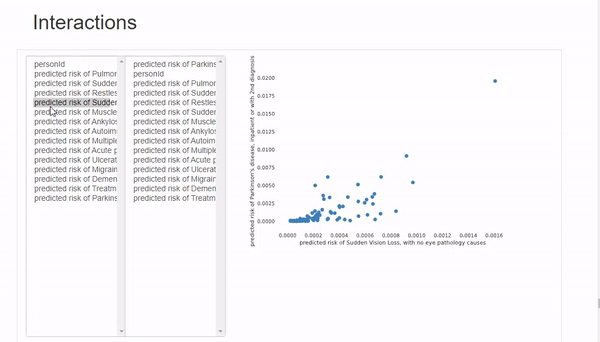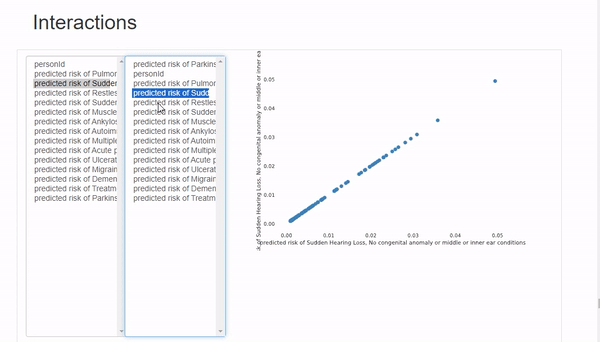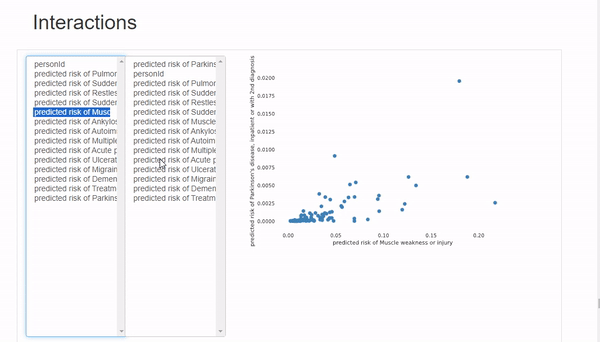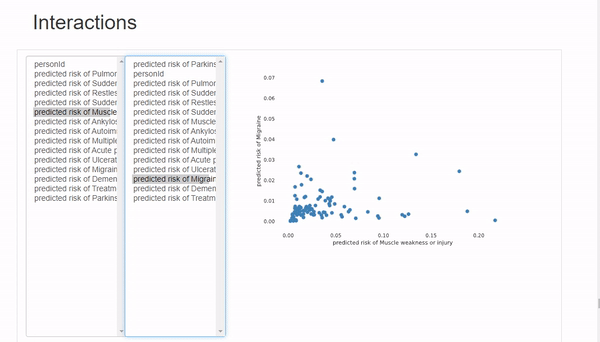
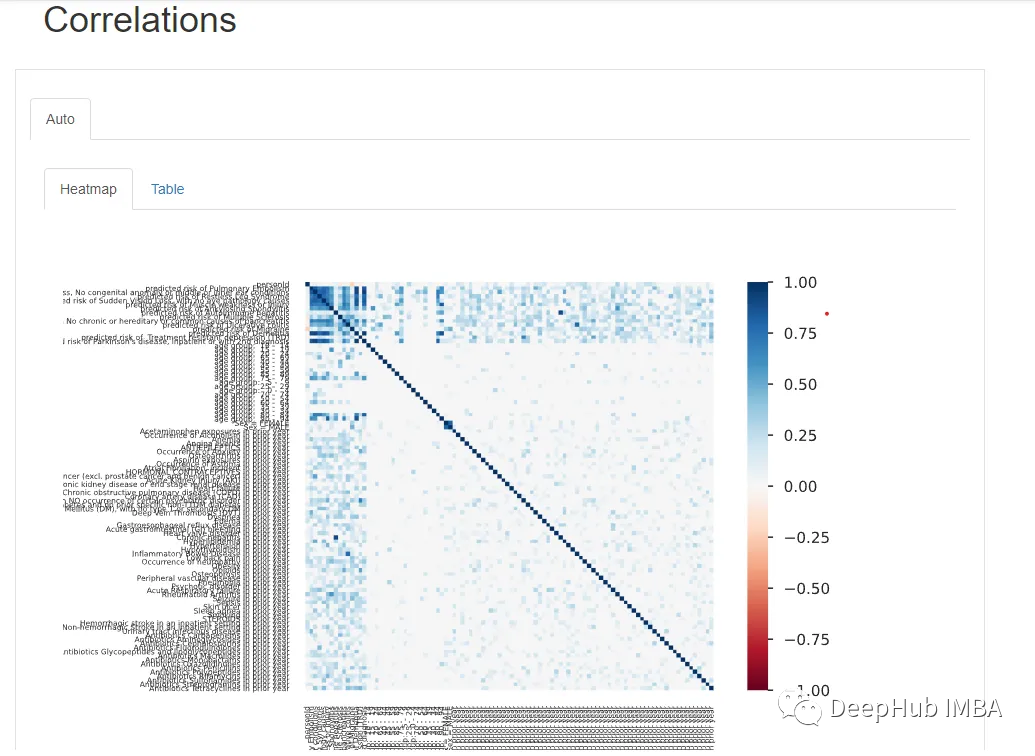
在Correlations 下,可以觀察到所有變量的熱圖。但是由于變量數量太多,熱圖幾乎難以辨認,所以最好是用自定義參數繪制手動熱圖。
最后還顯示了缺失值和相應的列,以及重復的行(如果有的話)。
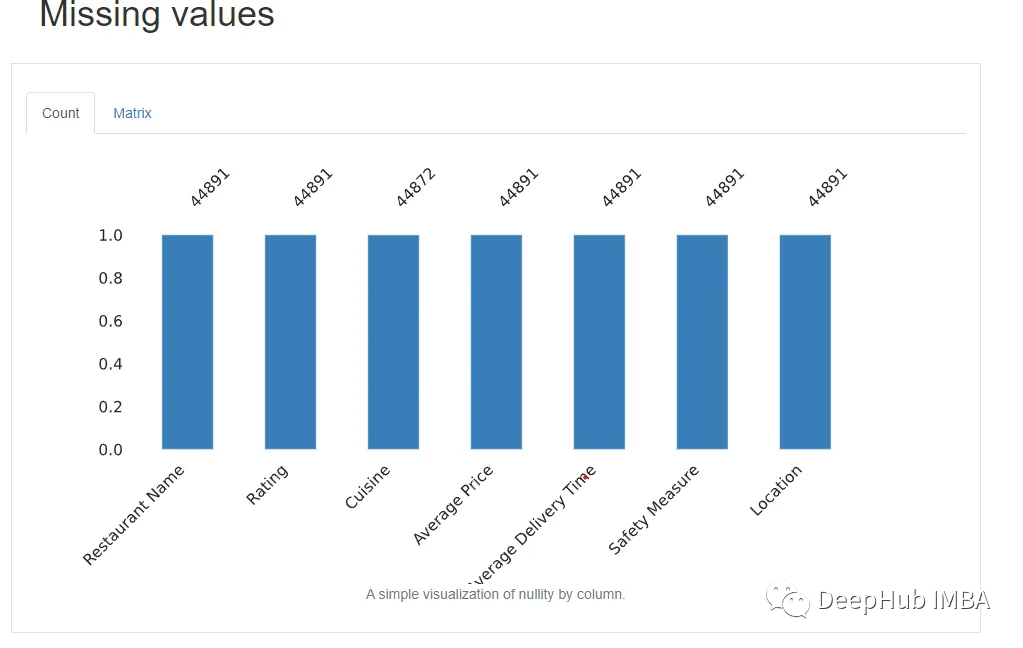
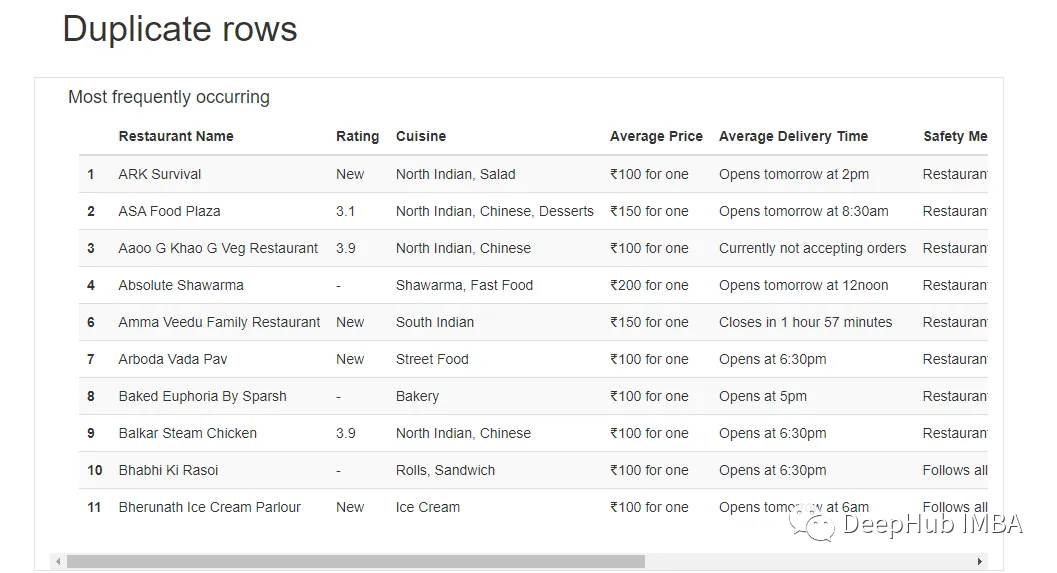
現YData報告對于在新數據集上獲得立足點并找到進一步調查的方向非常有用。因為Pandas Profiling算是最早 的一個自動化EDA庫了,并且YData對它做了非常大的更新。但是在較大數據集的情況下生成報告所需的時間很長,并且有時會崩潰。
SweetViz
這是我自己最喜歡用的自動化庫。它有三個主要函數可用于匯總數據集
analyze() -匯總單個數據集并生成報告。
compare() -比較兩個df,如' train '和' test '。它只會比較常見的功能。
compare_intra() -比較相同數據集的子集。例如,同一數據中的“男性”和“女性”統計數據。
如果在Jupyter或Kaggle中工作,可以使用show_notebook()來呈現報告,在本地可以使用show_html()在新的瀏覽器窗口中打開報告。
import sweetviz as sv
patient_report_2=sv.analyze(patient_data)
patient_report_2.show_notebook(w="100%", h="full")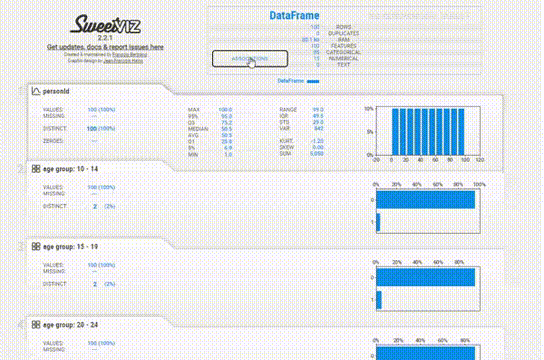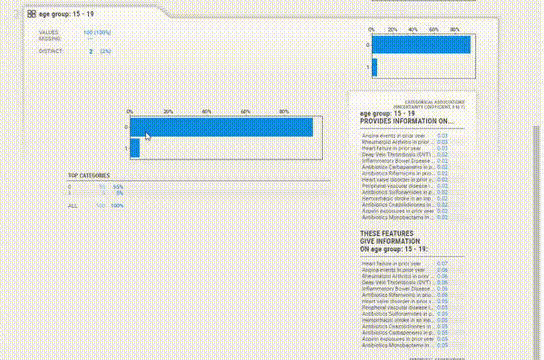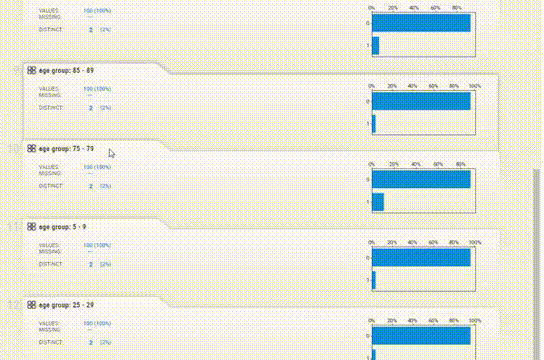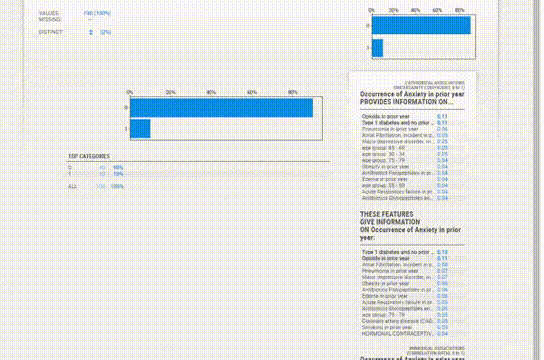
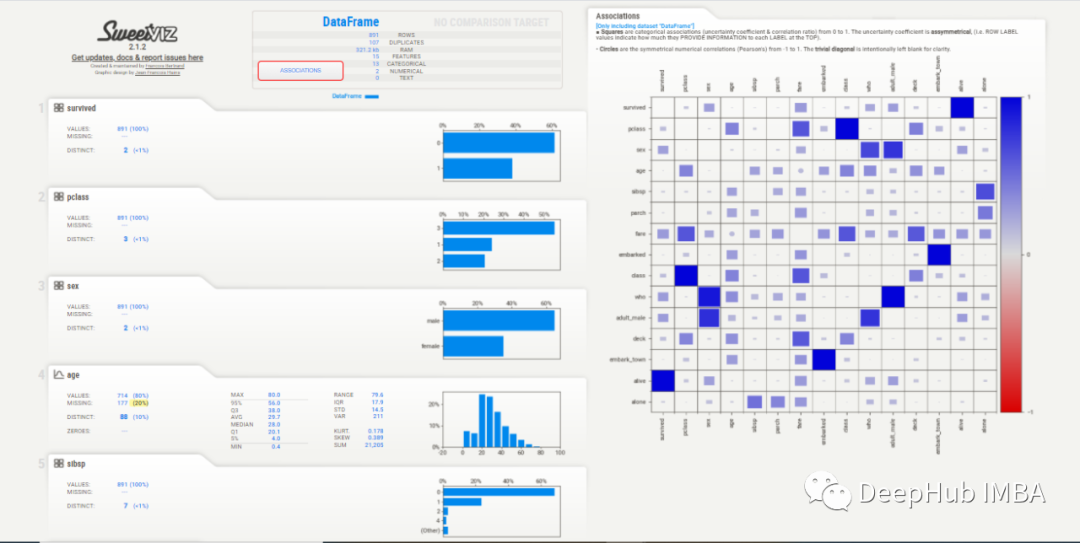
該報告與YData類似,提供了類似的信息,但UI感覺有點過時。
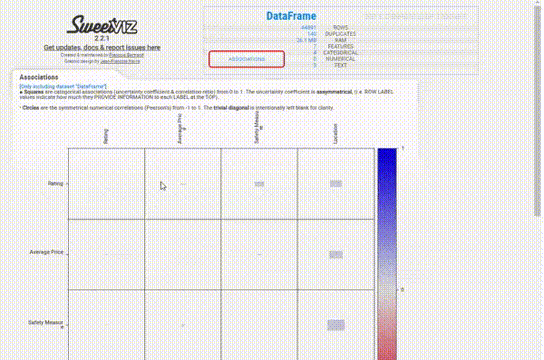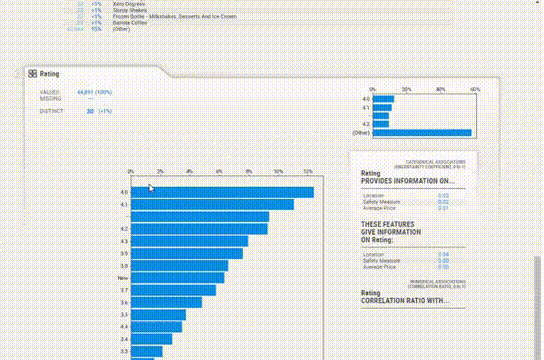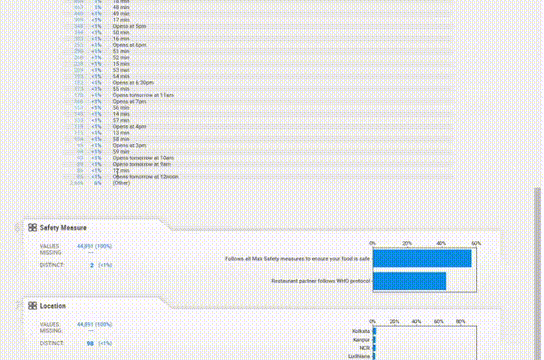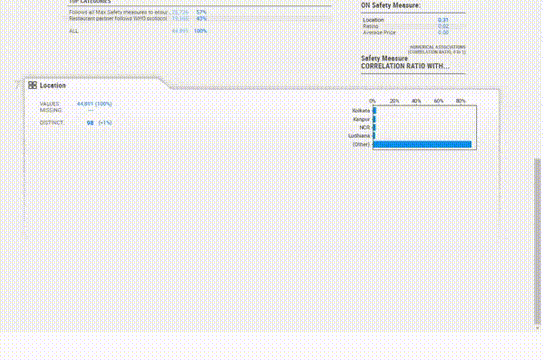
Association 選項卡創建了一個熱圖,提供了對變量相關性的洞察,由于變量的數量很大,熱圖是難以辨認的,對我們沒有用處。所以可以使用explore_correlations()函數導出相關矩陣,并使用這些數據繪制帶有自定義參數的熱圖。
為每個變量提供的信息更加簡潔。缺失值、惟一值、分布甚至相關性都在每個變量部分中一起給出,所以不必在各個模塊之間跳轉以查看信息。
對于直方圖,箱的數量也可以改變。統計信息可以在右上角查看,頻繁值和極值也可以在底部看到。
但是它除了熱圖之外沒有提供雙變量分析,因此無法看到兩個變量如何相互作用,這與YData不同。
在分析文本數據時,所提供的信息主要基于類和百分比分布,這比YData報告中少了很多
SweetViz給出了數據集的一個很好的概述,并且作為任何分析的起點都是很好的,關鍵是它運行的速度很快。
D-Tale
D-Tale只需一行代碼就可以創建一個完全交互的界面,其中有大量的選項可隨意使用。只需點擊一個按鈕就可以完成一些事情,不需要編寫許多行代碼。幾乎所有你想通過編碼做的事情都有一個UI功能,可以通過下拉菜單輕松獲得。
import dtale
patient_report=dtale.show(patient_data)
patient_report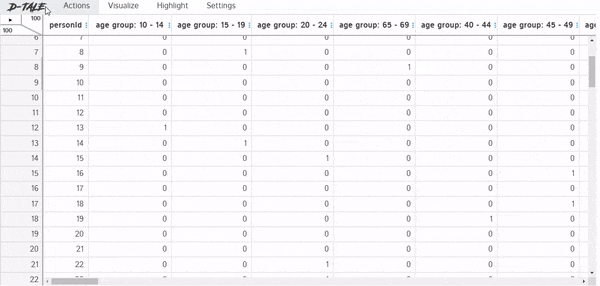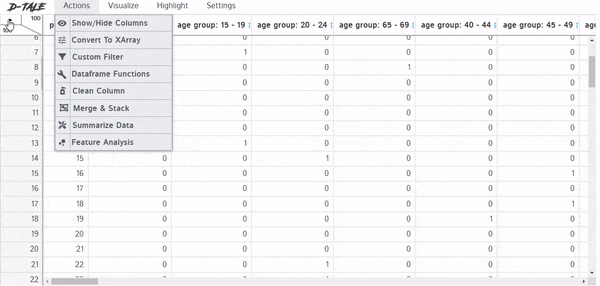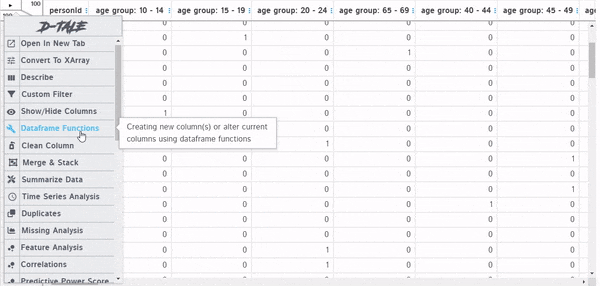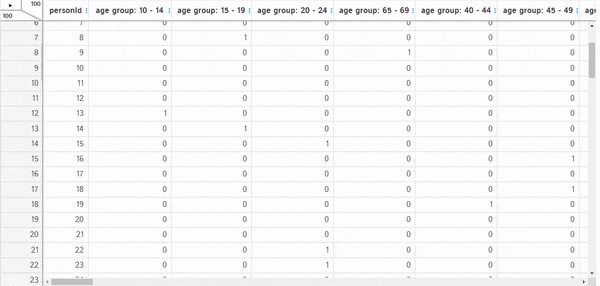
也可以在單獨的瀏覽器中打開報表,而不是在jupyter中工作。這可以提供更大的空間來探索數據及其特性。只需點擊左上角箭頭,選擇“Open in New Tab”。
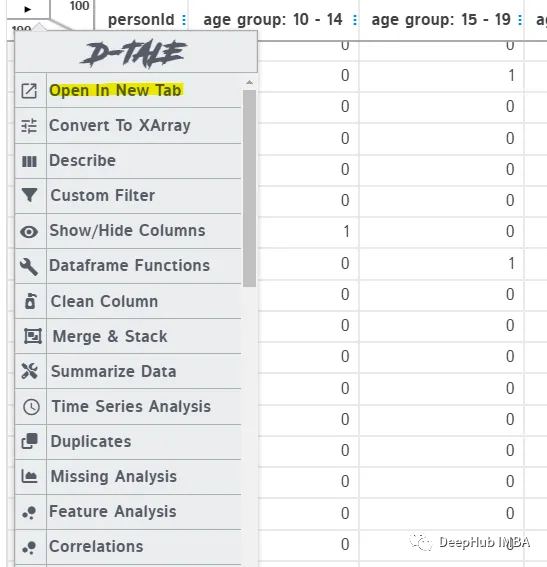
這個菜單包含了一個列表中所有可用的功能,這些功能也在頂部的行中被劃分為自動隱藏,所以需要保將光標懸停在列上方以查看工具欄,這是一個對于新手不好的地方。
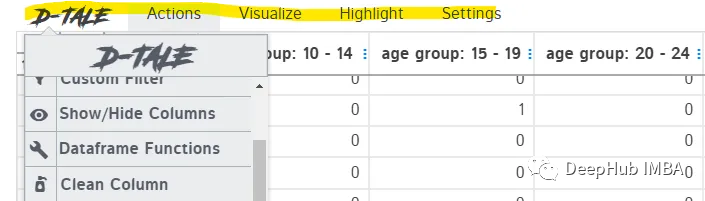
Actions:在這個類別下,你可以使用pandas函數來實現聚合、數據清理、數據轉換等功能。所有這些都是交互式的,只需點擊鼠標即可。最棒的是,當你將鼠標懸停在每個功能上時,每個功能的解釋都會彈出。可以使用Clean column從文本數據中刪除標點符號,并且只需單擊幾下即可標準化文本數據。這是一個非常方便的特性,特別是對于新手來說。
Visualize:這是最有用的分類,給出了整個數據集的漂亮摘要。類似于pandas的describe()方法。
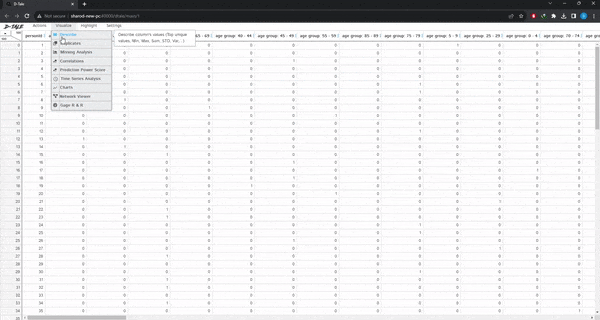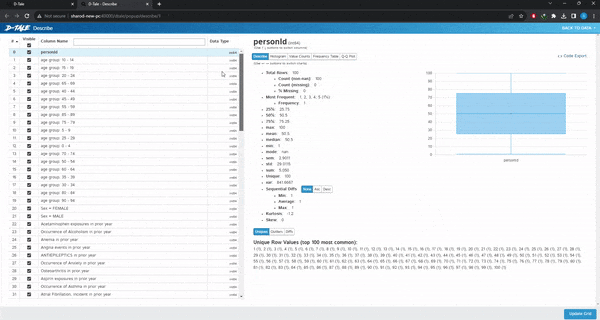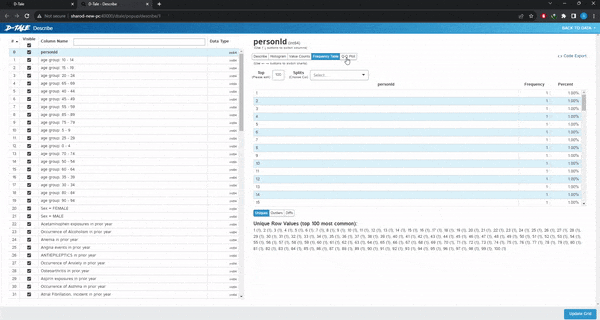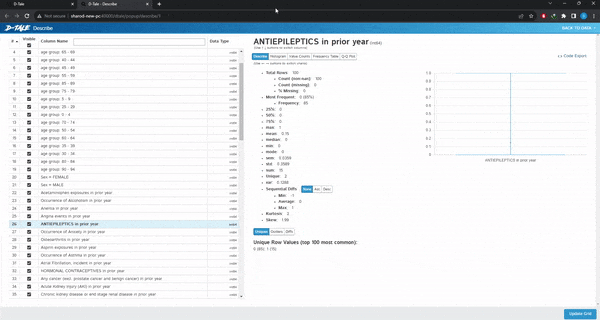
可以做缺失值分析、時間序列分析、查找相關性或創建圖表。選擇想要的圖表類型,選擇x和y變量,如果需要,選擇組,圖形將自動加載。也可以選擇多個變量或組。不需要代碼,只需點擊幾下就可以繪制完整的圖表。
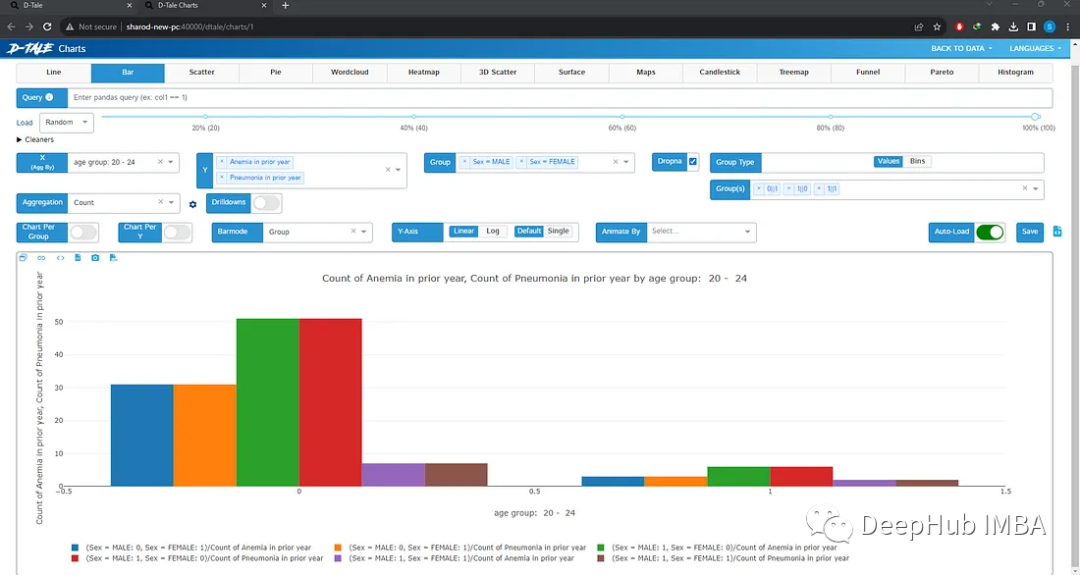
還可以單擊列標題以顯示更多選項,包括列分析,更改數據類型,查找重復項,重命名列,刪除或更改位置等。這些任務可以通過編寫基本代碼輕松完成,但是使用這個工具可以節省很多時間。你也可以編輯任何單元格的值,只需點擊它,就像在excel中一樣。
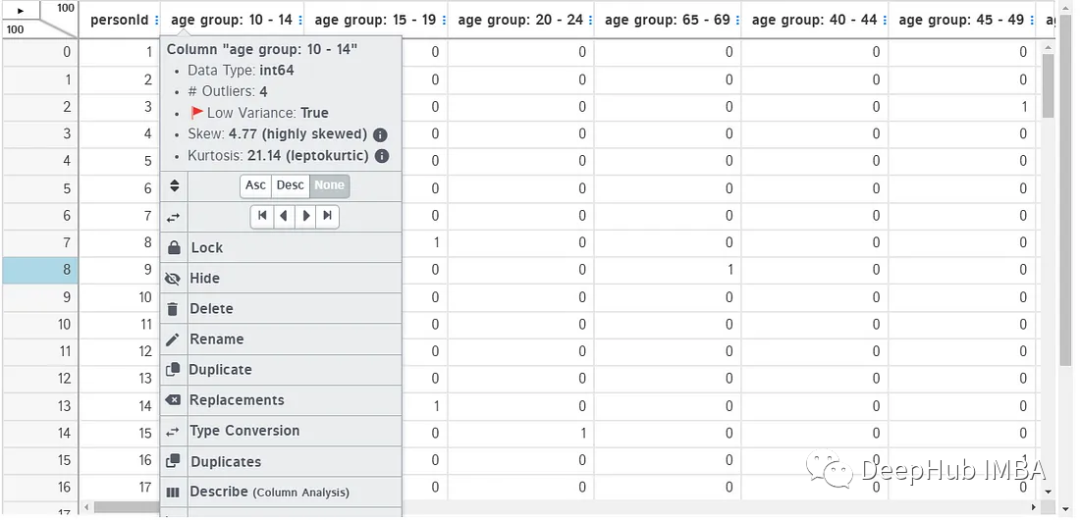
這個庫可以說是EDA的第二步,通過自動化EDA我們對數據有了一定了解后使用這個庫,可以在數據清理、預處理和可視化方面節省很多時間。
Klib
Klib是一個有趣的小庫,非常容易使并且創建了非常有用的視覺效果。它還包含清理和預處理數據的功能。它還將一些非常常見的預處理步驟(這些步驟可能很繁瑣)合并為單個命令,這些命令可以運行以獲得相同的結果。這個庫是由著名的數據科學教育家Krish Naik推薦的,所以值得一試。
df = pd.DataFrame(data)
# klib.describe - functions for visualizing datasets
- klib.cat_plot(df) # returns a visualization of the number and frequency of categorical features
- klib.corr_mat(df) # returns a color-encoded correlation matrix
- klib.corr_plot(df) # returns a color-encoded heatmap, ideal for correlations
- klib.corr_interactive_plot(df, split="neg").show() # returns an interactive correlation plot using plotly
- klib.dist_plot(df) # returns a distribution plot for every numeric feature
- klib.missingval_plot(df) # returns a figure containing information about missing values
# klib.clean - functions for cleaning datasets
- klib.data_cleaning(df) # performs datacleaning (drop duplicates & empty rows/cols, adjust dtypes,...)
- klib.clean_column_names(df) # cleans and standardizes column names, also called inside data_cleaning()
- klib.convert_datatypes(df) # converts existing to more efficient dtypes, also called inside data_cleaning()
- klib.drop_missing(df) # drops missing values, also called in data_cleaning()
- klib.mv_col_handling(df) # drops features with high ratio of missing vals based on informational content
- klib.pool_duplicate_subsets(df) # pools subset of cols based on duplicates with min. loss of information我嘗試了一些可視化功能,下圖顯示了所有變量的熱圖,上面的三角形被消去了(這是默認的),這是一個很好的特性。它使圖表更具可讀性。由于變量的數量非常多,因此很難看到相關性,但默認的配色方案可以讓我們看到相關性較高的地方聚集在一起,用深藍色標記。
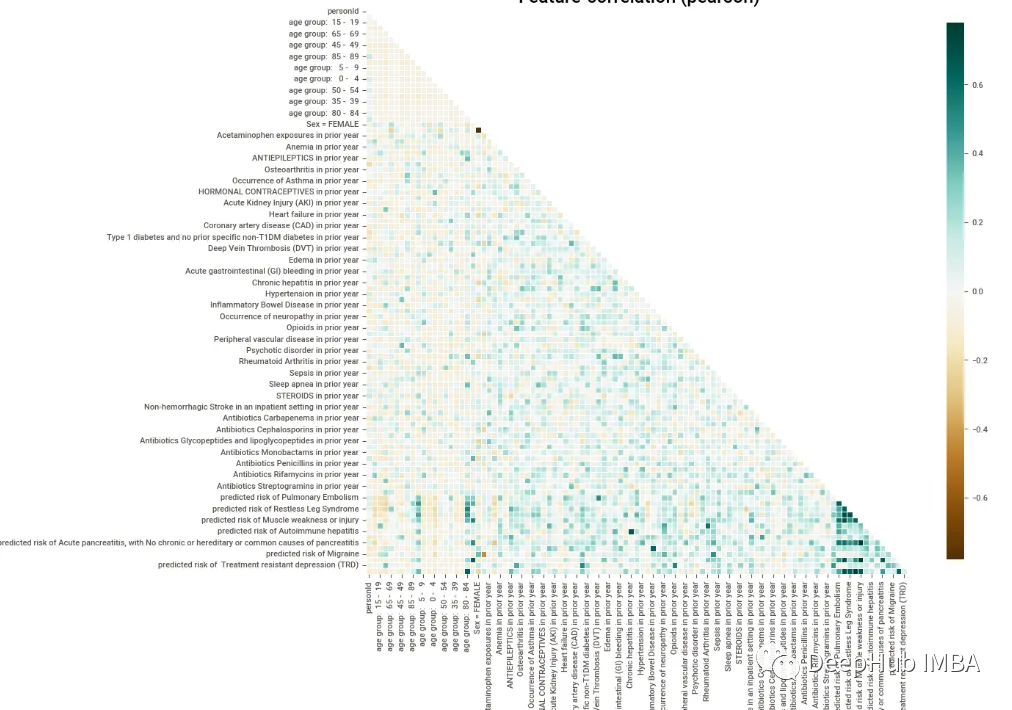
圖表的配色方案很好,信息也很清晰。但是信息水平不像前幾個庫那樣密集,這對于那些只希望看到某些特定數據而不希望被信息淹沒的人來說是件好事。但是為了獲得數據的概覽,必須編寫更多行代碼來獲得想要的內容。
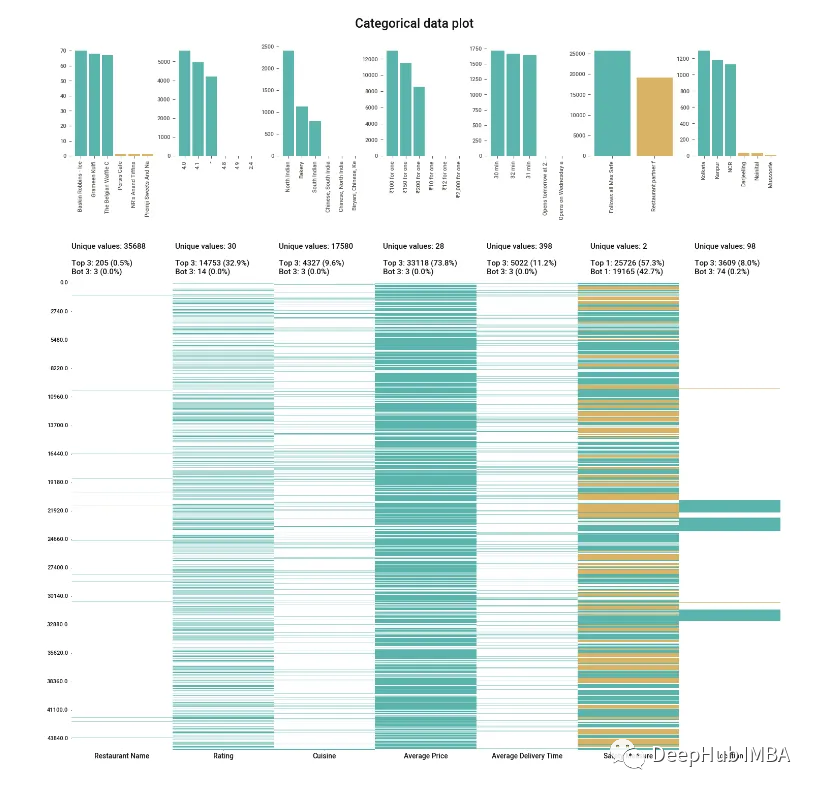
這個庫很有趣,它肯定是工具箱中一個有用的工具,但我發現它在預處理的時候會更有用,因為許多常用的預處理技術已經被壓縮成單行命令,可以直接執行節省編碼時間。
Dabl
數據分析基線庫- Dabl。這個庫在執行時需要確定一個目標變量,將目標列作為y軸進行繪圖。雖然這個庫仍在開發中,但是它可以直接幫你進行雙變量分析,這通常是我們真正想看到的。每個變量相對于目標變量的表現。
import dabl
import matplotlib.pyplot as plt
dabl.plot(patient_data, target_col='predicted risk of Pulmonary Embolism')
plt.show()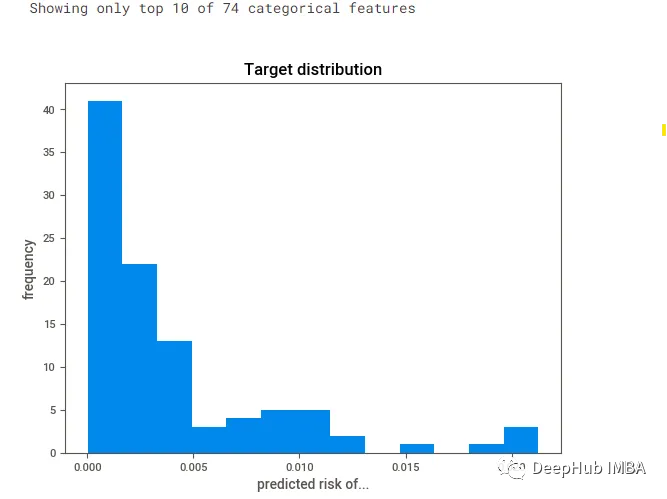
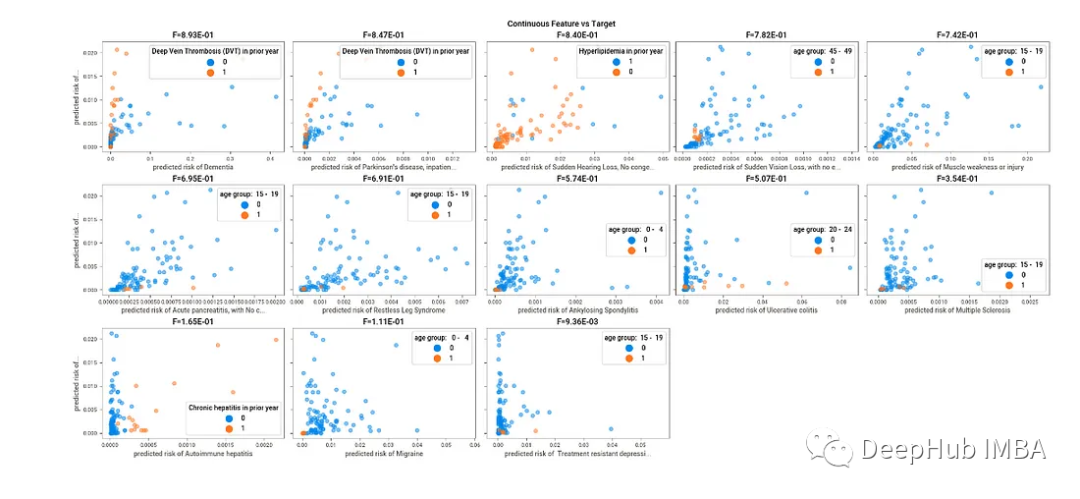
這與seaborn中的pairplot()命令非常相似。
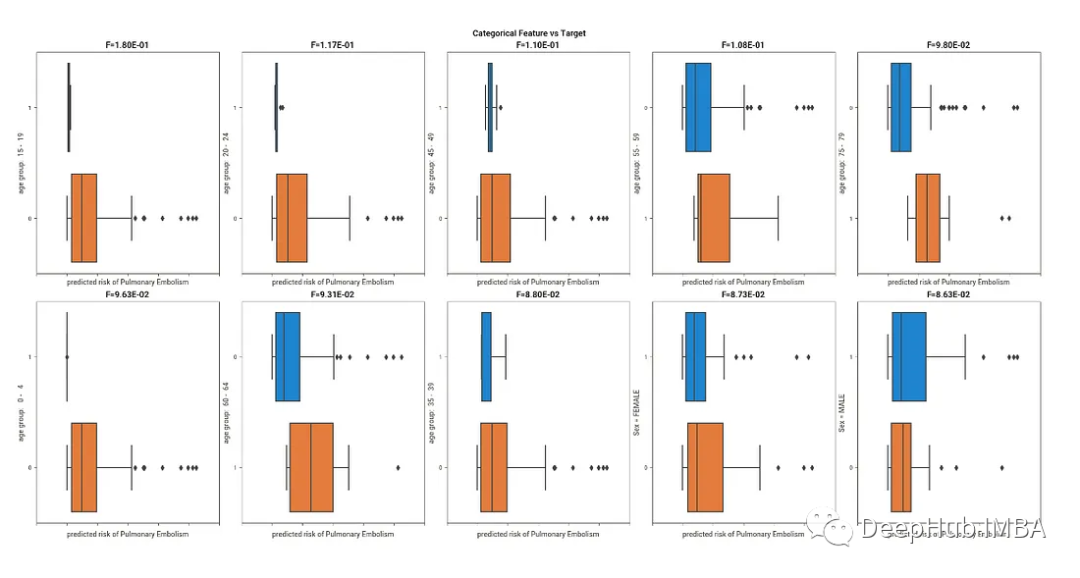
Dabl也有一些數據清理功能,并開始引入一些基本的機器學習模型,但是我覺得這些功能都太多了,沒有必要。
這是一個不錯的庫,具有良好的雙變量分析和一些額外的數據清理功能。如果已經確定了目標變量,并且只是希望觀察它與其他特征的行為,那么它可能非常有用。
Sketch
它是一個基于LLM(大型語言模型)的庫,只有三個命令,其中一個使用OpenAI API。這導致它有大小限制,所以我們必須取數據的一個子集。
就像其他LLM(ChatGPT)一樣,Sketch使用自然語言來處理查詢并產生類似人類的輸出。它利用人工智能將數據分析過程轉化為對話。
這三個命令是ask()、howto()和apply()。最后一個使用OpenAI的API,對數據生成很有用。第一個函數ask()將導致會話輸出,而howto()將導致給出如何實現目標的代碼。兩者如下所示:
query="How do I plot a chart of all missing values ?"
query2="I want an overview of this dataset"
patient_data_subset=patient_data.iloc[:, :19]
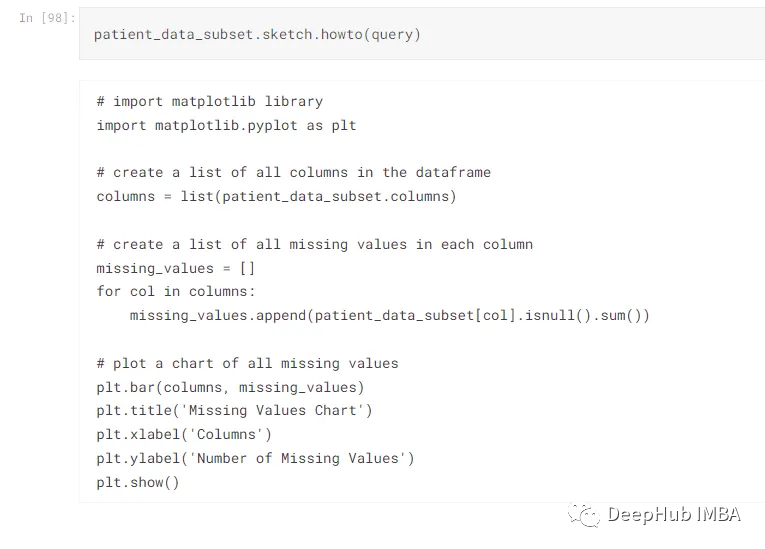
以對話的形式探索數據集是非常有趣的,從一個查詢到下一個查詢,直到獲得所需的信息。新手和老手都可以使用howto()函數來快速生成代碼塊,不必從頭編寫整個代碼,節省了時間。
Sketch允許在Jupyter中使用類似GPT的功能。但是ChatGPT也直接支持了Jupyter,可以集成到開發環境中,這使得這個庫變得多余,但是如果你希望通過使用OpenAIs API密鑰來避免復雜性,簡單地使用Sketch作為python包是最簡單的方法。
這個庫可以很有趣,但是也只是有趣,并不能作為自動EDA來推薦,我提到他只是因為他包含了LLM的功能,不建議在線上使用。
總結
YData Profiling執行起來很簡單,UI很直觀,給了我所有的信息,這是開始EDA過程的一個很好的切入點。
D-Tale不僅是EDA過程的一個很好的起點,而且可以用來輕松地預處理數據,最主要是不需要編寫任何代碼,這使得它非常節省時間,并且任何人都可以輕松訪問。
SweetViz的UI有點過時,但它提供了相當數量的信息,最主要的時他可以比較兩個數據集。



























