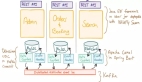
使用一致性哈希讓數據均勻分布
為了提升數據的讀寫速度,我們一般會引入緩存,如果數據量很大,一個節點的緩存容納不下,那么就會采用多節點,也就是分布式緩存。具體做法是在節點前面加一個 Proxy 層,由 Proxy 層統一接收來自客戶端的讀寫請求,然后將請求轉發給某個節點。

但這就產生了一個問題,既然有多個節點(比如上圖有 A、B、C 三個節點,每個節點存放不同的 KV 數據),那么寫數據的時候應該寫到哪一個節點呢?讀數據,又應該從哪一個節點去讀呢?
維度考量
對于任何一個分布式存儲系統,在存儲數據時,我們通常都會從數據均勻、數據穩定和節點異構性這三個維度來考量。
數據均勻
不同節點中存儲的數據要盡量均勻,不能因數據傾斜導致某些節點存儲壓力過大,而其它節點卻幾乎沒什么數據。比如有 4 個相同配置的節點要存儲 100G 的數據,那么理想狀態就是讓每個節點存儲 25G 的數據。
此外用戶訪問也要做到均勻,避免出現某些節點的訪問量很大,但其它節點卻無人問津的情況。比如要處理 1000 個請求,理想狀態就是讓每個節點處理 250 個請求。
當然這是非常理想的情況,實際情況下,只要每個節點之間相差不太大即可。
數據穩定
當存儲節點出現故障需要移除、或者需要新增節點時,數據按照分布規則得到的結果應該盡量保持穩定,不要出現大范圍的數據遷移。
比如 4 個節點存儲 100G 數據,但現在其中一個節點掛掉了,那么只需要將掛掉的節點存儲的數據遷移到其它正常節點即可,而不需要大范圍對所有數據進行遷移。當然新增節點也是同理,要在盡可能小的范圍內將數據遷移到擴展的節點上。
節點異構性
不同存儲節點的硬件配置可能差別很大,配置高的節點能存儲的數據量、單位時間處理的請求數,本身就高于配置低的節點。
如果這種硬件配置差別很大的節點,存儲的數據量、處理的請求數都差不多,那么反倒不均勻了。所以,一個好的數據分布算法應該考慮節點異構性。
當然,除了上面這 3 個維度外,我們一般還會考慮隔離故障域、性能穩定性等因素。
隔離故障域
用于保證數據的可用性和可靠性,比如我們通常通過備份來實現數據的可靠性。但如果每個數據及它的備份,被分布到了同一塊硬盤或節點上,就有點違背備份的初衷了。
所以一個好的數據分布算法,給每個數據映射的存儲節點應該盡量在不同的故障域,比如不同機房、不同機架等。
性能穩定性
數據存儲和查詢的效率要有保證,不能因為節點的添加或者移除,造成讀寫性能的嚴重下降。
了解完數據分布的設計原則后,再來看看主流的數據分布式方法,也就是哈希算法,以及基于哈希算法演進出的一些算法。
哈希
通過對 key 進行哈希,然后再用哈希值對節點個數取模,即可尋址到對應的服務器。
比如查詢名為 key-01 的 key,計算公式是 hash("key-01") % 3 ,經過計算尋址到了編號為 0 的服務器節點 A,如下圖所示。

不難發現,哈希算法非常簡單直觀,如果選擇一個好的哈希函數,是可以讓數據均勻分布的。但哈希算法有一個致命的缺點,就是它無法滿足節點動態變化。比如節點數量發生變化,基于新的節點數量來執行哈希算法的時候,就會出現路由尋址失敗的情況,Proxy 無法尋址到之前的服務器節點。
想象一下,假如 3 個節點不能滿足業務需要了,我們增加了一個節點,節點的數量從 3 變成 4。那么之前的 hash("key-01") % 3 = 0,就變成了 hash("key-01") % 4 = X。
因為取模運算發生了變化,所以這個 X 大概率不是 0(假設 X 為 1),這時再查詢,就會找不到數據了。因為 key-01 對應的數據,存儲在節點 A 上,而不是節點 B。

同樣的道理,如果我們需要下線 1 個服務器節點,也會存在類似的可能查詢不到數據的問題。
而解決這個問題的辦法在于我們要遷移數據,基于新的計算公式 hash("key-01") % 4,來重新對數據和節點做映射。但需要注意的是,數據的遷移成本是非常高的,對于 3 節點 KV 存儲,如果我們增加 1 個節點,變為 4 節點集群,則需要遷移 75% 的數據。
所以哈希算法適用于節點配置相同,并且節點數量固定的場景。如果節點會動態變化,那么應該選擇一致性哈希算法。
 一致性哈希
一致性哈希
一致性哈希也是基于哈希實現的,哈希算法是對節點的數量進行取模運算,而一致性哈希算法是對 2^32 進行取模運算。想象一下,一致性哈希算法將整個哈希值空間組織成一個虛擬的圓環,也就是哈希環:

哈希環的空間按順時針方向組織,圓環的正上方的點代表 0,0 右側的第一個點代表 1,以此類推,2、3、4、5、6……直到 2^32-1。
在一致性哈希中,你可以通過執行哈希算法,將節點映射到哈希環上。比如選擇節點的主機名作為參數執行哈希再取模,那么就能確定每個節點在哈希環上的位置了。

當需要對指定 key 的值進行讀寫的時候,可以通過下面兩步進行尋址:
- 首先,對 key 進行哈希再取模,并確定此 key 在環上的位置。
- 然后,從該位置沿著哈希環順時針行走,遇到的第一個節點就是 key 對應的節點。
我們舉個例子,假設 key-01、key-02、key-03 三個 key,經過哈希取模后,在哈希環中的位置如下:

根據一致性哈希算法,key-01 尋址到節點 B,key-02 尋址到節點 A,key-03 尋址到節點 C。如果只考慮數據分布的話,那么一致性哈希算法和哈希算法差別不太大,但一致性哈希解決了節點變化帶來的數據遷移問題。
假設,現在有一個節點故障了(比如節點 C):

可以看到,key-01 和 key-02 不會受到影響,只有 key-03 的尋址被重定位到 A。一般來說,在一致性哈希算法中,如果某個節點宕機不可用了,那么受影響的數據僅僅是故障節點和前一節點之間的數據。
比如當節點 C 宕機了,受影響的數據是節點 B 和節點 C 之間的數據(例如 key-03),尋址到其它哈希環空間的數據(例如 key-01),不會受到影響。
如果此時集群不能滿足業務的需求,需要擴容一個節點 D 呢?

可以看到 key-01、key-02 不受影響,只有 key-03 的尋址被重定位到新節點 D。一般而言,在一致性哈希算法中,如果增加一個節點,受影響的數據僅僅是新節點和前一節點之間的數據,其它數據也不會受到影響。
使用一致性哈希的話,對于 3 節點 KV 存儲,如果我們增加 1 個節點,變為 4 節點集群,則只需要遷移 24.3% 的數據。遷移的數據量僅為使用哈希算法時的三分之一,從而大大提升效率。
總的來說,使用了一致性哈希算法后,擴容或縮容的時候,都只需要重定位環空間中的一小部分數據。所以一致性哈希算法是對哈希算法的改進,在采用哈希方式確定數據存儲位置的基礎上,又增加了一層哈希,也就是在數據存儲前先對存儲節點進行哈希,具有較好的容錯性和可擴展性。
一致性哈希比較適合節點配置相同、但規模會發生變化的場景。
我們用 Python 簡單實現一下一致性哈希:
from typing import Union, List
import hashlib
import bisect
class ConsistentHash:
def __init__(self,
nodes: List[str] = None,
ring_max_len=2 ** 32):
# 哈希環的最大長度
self.ring_max_len = ring_max_len
# 節點在哈希環上的索引(有序)
self.node_indexes = []
# '節點在哈希環上的索引' 到 '節點' 的映射
self.nodes_mapping = {}
if nodes:
for node in nodes:
self.add_node(node)
def get_index(self, item: Union[str, bytes]):
"""
獲取節點或者 key 在哈希環上的索引
"""
if type(item) is str:
item = item.encode("utf-8")
md5 = hashlib.md5()
md5.update(item)
# md5.hexdigest() 會返回 16 進制字符串,將其轉成整數
# 然后是取模,如果 n 是 2 的冪次方,那么 m % n 等價于 m & (n - 1)
# 所以字典的容量一般都是 2 的冪次方,就是為了將取模優化成按位與
return int(md5.hexdigest(), 16) & (self.ring_max_len - 1)
def add_node(self, node):
"""
node 可以是節點的信息,比如一個字典
但這里為了方便,node 就表示節點名稱
"""
node_index = self.get_index(node)
# 節點索引是有序的,新增時使用 bisect 可將復雜度優化為 logN
bisect.insort(self.node_indexes, node_index)
self.nodes_mapping[node_index] = node
print(f"節點 {node} 被添加至哈希環, 索引為 {node_index}")
def remove_node(self, node):
# 移除節點
node_index = self.get_index(node)
self.node_indexes.remove(node_index)
self.nodes_mapping.pop(node_index)
print(f"節點 {node} 從哈希環中被移除")
def get_node(self, key):
"""
判斷 key 應該被存在哪一個 node 中
"""
key_index = self.get_index(key)
# node_indexes 里面存儲了所有節點在哈希環的索引
# 所以只需要遍歷即可
for node_index in self.node_indexes:
if node_index >= key_index:
break
else:
node_index = self.node_indexes[0]
# 如果節點索引大于等于 key 的索引,那么就找到了指定節點
# 如果遍歷結束還沒有找到,說明 key 的索引大于最后一個節點的索引
# 這樣的話,該 key 應該存在第一個節點
node = self.nodes_mapping[node_index]
# todo:連接指定節點,存儲 key 和 value
print(f"key `{key}` 存在了節點 `{node}` 上")
ch = ConsistentHash(nodes=["node1", "node2", "node3"])
"""
節點 node1 被添加至哈希環, 索引為 2595155078
節點 node2 被添加至哈希環, 索引為 3803043663
節點 node3 被添加至哈希環, 索引為 385180855
"""
ch.get_node("S 老師四點下班")
ch.get_node("高老師總能分享出好東西")
ch.get_node("電烤??架")
"""
key `S 老師四點下班` 存在了節點 `node3` 上
key `高老師總能分享出好東西` 存在了節點 `node1` 上
key `電烤??架` 存在了節點 `node1` 上
"""
# 刪除節點
ch.remove_node("node3")
"""
節點 node3 從哈希環中被移除
"""
# 當節點被刪除后,存儲位置發生變化
ch.get_node("S 老師四點下班")
"""
key `S 老師四點下班` 存在了節點 `node1` 上
"""當然啦,在節點被移除時,應該自動進行數據遷移。這里就不實現了,有興趣的話可以嘗試一下。
然后一致性哈希也有它的一些問題,比如讀寫可能集中在少數的節點上,導致有些節點高負載,有些節點低負載的情況。

從圖中可以看到,雖然有 3 個節點,但訪問請求主要集中在節點 A 上。當然這個問題其實不大,我們可以設計一個好的哈希函數,讓節點均勻分布。
但一致性哈希還存在擊垮后繼節點的風險,如果某個節點退出,那么該節點的后繼節點需要承擔該節點的所有負載。如果后繼節點承受不住,那么也可能出現故障,從而導致后繼節點的后繼節點也面臨同樣的問題,引發惡性循環。
那么如何解決后繼節點可能被壓垮的問題呢?針對這個問題,Google 提出了帶有限負載的一致性哈希算法。
帶有限負載的一致性哈希
帶有限負載的一致性哈希的核心原理是,給每個存儲節點設置一個存儲上限值,來控制存儲節點添加或移除造成的數據不均勻。
當數據按照一致性哈希算法找到相應的節點時,要先判斷該節點是否達到了存儲上限。如果已經達到了上限,則需要繼續尋找該節點順時針方向之后的節點進行存儲。
所以該算法相當于在一致性哈希的基礎上,給節點增加了一些存儲上限,它的適用場景和一致性哈希是一樣的。目前在 Google、Vimeo 等公司的負載均衡項目中得到應用。
當然啦,無論是哈希、一致性哈希,還是帶有限負載的一致性哈希,它們的適用場景都要求節點的配置相同,換句話說就是沒有考慮節點異構性的問題。如果存儲節點的硬件配置不同,那么采用上面算法實現的數據均勻分布,反倒變得不均勻了。
所以便引入了虛擬節點。
帶虛擬節點的一致性哈希
帶虛擬節點的一致性哈希,核心思想是根據每個節點的性能,為每個節點劃分不同數量的虛擬節點,并將這些虛擬節點映射到哈希環中,然后再按照一致性哈希算法進行數據映射和存儲。
比如三個節點 A、B、C,以節點 C 為基準,節點 B 的性能是它的 2 倍,節點 A 是它的 3 倍。因此要給節點 C 添加 1 個虛擬節點,給節點 B 添加 2 個虛擬節點,給節點 A 添加 3 個虛擬節點。

節點 A 的虛擬節點是 A1、A2、A3,節點 B 的虛擬機節點是 B1、B2,節點 C 的虛擬節點是 C1。當然虛擬節點的數量不一定是 1、2、3,也可以按照比例進行增加。
總之通過增加虛擬節點,可以考慮到節點異構性,讓性能高的節點多分配一些請求。
如果節點配置一樣,也可以使用該算法,只不過此時每個節點對應的虛擬節點是一樣的。并且采用這種方式,可以有效避免節點傾斜的問題,不會出現大部分請求都打在同一節點的情況。
可以看出,帶虛擬節點的一致性哈希比較適合異構節點、節點規模會發生變化的場景。
這種方法不僅解決了節點異構性問題,還提高了系統的穩定性。當節點變化時,會有多個節點共同分擔系統的變化,因此穩定性更高。
比如當某個節點被移除時,對應該節點的多個虛擬節點均會被移除。而這些虛擬節點按順時針方向的下一個虛擬節點,可能會對應不同的物理節點,即這些不同的物理節點共同分擔了節點變化導致的壓力。
Memcached 便實現了該方法。
當然,由于引入了虛擬節點,增加了節點規模,從而增加了節點的維護和管理的復雜度。比如新增一個節點或一個節點故障時,對應到哈希環上則需要新增和刪除多個節點,數據的遷移等操作也會相應的變復雜。
 小結
小結
一致性哈希是一種特殊的哈希算法,在使用一致性哈希算法后,節點增減變化時只影響到部分數據的路由尋址,也就是說我們只要遷移部分數據,就能實現集群的穩定了。
當某個節點退出時,會有壓垮后繼節點的風險,因此可以給每個節點設置一個上限。如果所有節點都達到了上限怎么辦?說明你需要調整上限或增加節點了。
當節點數較少時,可能會出現節點在哈希環上分布不均勻的情況,這樣每個節點實際占據環上的區間大小不一,最終導致業務對節點的訪問冷熱不均。此時我們可以通過引入更多的虛擬節點來解決這個問題,當然通過虛擬節點也可以解決節點異構性的問題。
總之節點數越多,使用哈希算法時,需要遷移的數據就越多;使用一致性哈希時,需要遷移的數據就越少。經過測試,當我們向 10 個節點組成的集群中增加節點時,如果使用了哈希算法,需要遷移高達 90.91% 的數據,使用一致性哈希的話,則只需要遷移 6.48% 的數據。