













一篇帶你了解哈希與一致性哈希
0. 為什么寫本文
有個朋友是做分布式存儲的,有一次聊天他問我一些問題:什么是一致性哈希?一般如何實現(xiàn)?有什么優(yōu)點?
對于這個問題,我的腦海中只是閃現(xiàn)幾個詞匯:md5、hash函數(shù)、哈希環(huán)。
在我看來,哈希就是一種算法。一句話概括就是:把無限的數(shù)據(jù)映射到有限的集合中的一種算法。
朋友說:你這段話很官方,但是等于沒說。
哈哈,身為某廠高級開發(fā)工程師的我,此刻無地自容。慚愧、慚愧,請允許我做一個悲傷的表情。
1. 哈希
對于哈希,日常開發(fā)中在很多場景都會用到,比如:
- md5 之類的哈希函數(shù)
- 分庫、分表時,使用某個字段的 hash 值對固定數(shù)值取模,來確定對應(yīng)庫表
- 一個大量數(shù)據(jù)的集合,根據(jù)某個字段作為拆分鍵,對數(shù)據(jù)進(jìn)行打散處理
- PHP的 HashTable、Go的 map、Python 的 dict 等數(shù)據(jù)結(jié)構(gòu)實現(xiàn)
- Redis 分片時使用 crc16 對key進(jìn)行哈希,然后對 16384 取模來確定分片
- 等等 ......
除上面場景,還有很多地方會用到 hash,而他們都是哈希的一種實現(xiàn)方式。
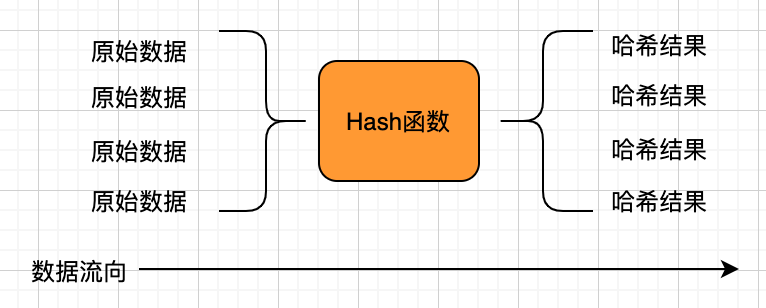
hash函數(shù)
1.1 哈希碰撞
無限個原始數(shù)據(jù)在經(jīng)過Hash函數(shù)運(yùn)算之后,得到的哈希結(jié)果會有一定的概率相同。那么,這些不同的原始數(shù)據(jù)得到相同哈希值的情況,就是哈希碰撞。
例如下圖所示:c、d在經(jīng)過某個哈希函數(shù)計算之后得到相同的哈希值10,那么c、d 就發(fā)生了哈希碰撞。
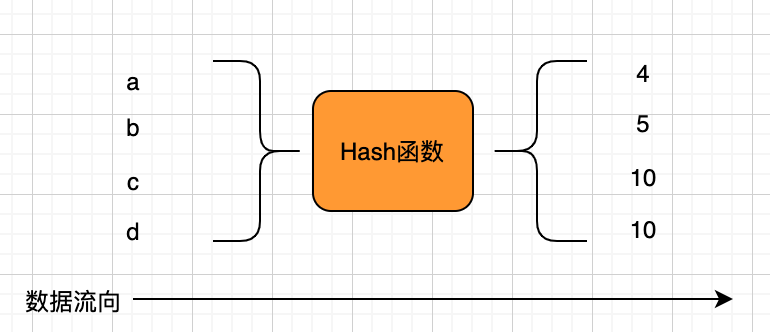
哈希碰撞
需要了解的:
哈希碰撞無法避免 (因為哈希結(jié)果值域是有限的,原始數(shù)據(jù)是無限的)
哈希值域越大,碰撞概率一般越低
好的哈希函數(shù)除了運(yùn)算速度外,還需要盡量小的哈希碰撞概率
1.2 針對哈希碰撞的兩種方案
在出現(xiàn)哈希碰撞情況下常用的方案有:
- 開放地址法
- 拉鏈法
開放地址法一般不常使用,讀者可以自行查閱相關(guān)資料。
拉鏈法則在很多場景、甚至開源系統(tǒng)都會用到。
例如:PHP的 HashTable(PHP5使用雙向鏈表、PHP7使用數(shù)組)、以及Go的map底層實現(xiàn)。
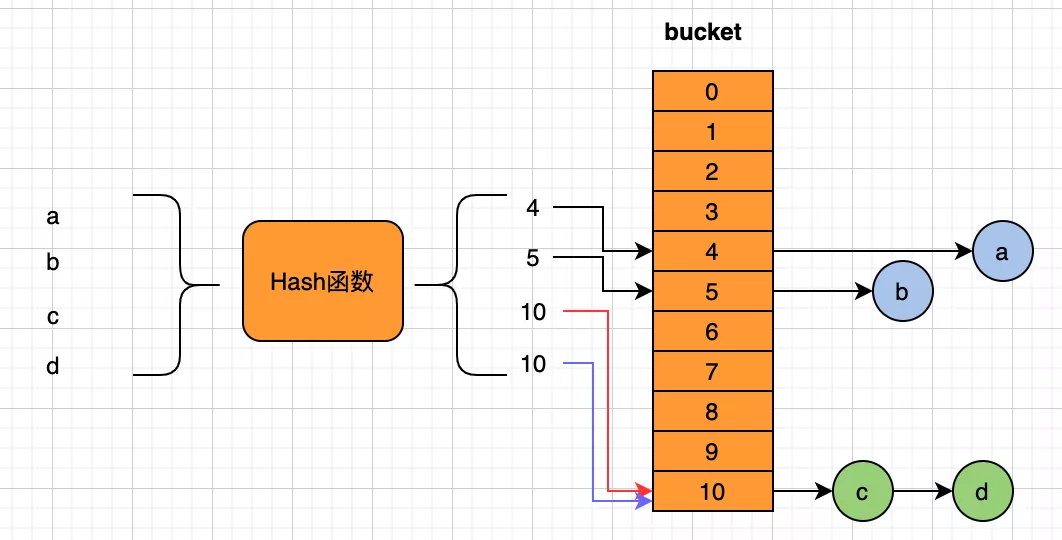
拉鏈法
如圖所示,c、d的哈希結(jié)果都為10,在存儲的時候使用鏈表來把他們串在一起(就像拉了一條鎖鏈一樣)。
其中,bucket 為在某一時刻大小固定的數(shù)組,下標(biāo)為哈希值對固定數(shù)值取模之后得到。bucket 的大小一般會在某種臨界狀態(tài)下進(jìn)行自動的擴(kuò)容、縮容。
查找的時候,根據(jù)計算的哈希值先定位到bucket對應(yīng)位置,然后再遍歷鏈表查找對應(yīng)數(shù)據(jù)。
注意:
原始數(shù)據(jù)經(jīng)過Hash計算一般會得到比較大的哈希值,此時需用哈希值對bucket大小取模來確定數(shù)據(jù)存儲位置
理想情況下,不會有哈希碰撞,數(shù)值落在bucket的不同位置,查找時間復(fù)雜度為 O(1)
糟糕情況下,數(shù)據(jù)全部哈希碰撞,數(shù)值都落在bucket同一個位置,查找時間復(fù)雜度為 O(n)
1.3 為什么用哈希
筆者以前接手過一個項目,每天數(shù)據(jù)量2億多條,這些數(shù)據(jù)需要落盤。建表的話,如果存在一張表里面,那將會是一個災(zāi)難。當(dāng)時筆者建了10張表,使用用戶uid對10取模來確定當(dāng)前數(shù)據(jù)落在哪一張表里面。
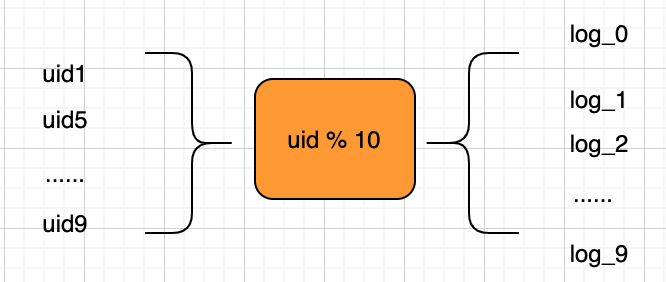
取模
其中,uid%10 相當(dāng)于hash算法,這樣的話就把2億多條的數(shù)量分拆在不同的表里面,減少了單表數(shù)據(jù)量,好處的話:可以提升查詢速度、數(shù)據(jù)在同步時效率提升等等。
在這種情況之下,使用哈希對大量數(shù)據(jù)進(jìn)行拆分再合適不過了。
1.4 普通哈希的缺點
優(yōu)點說了一堆,那么接下來說一下不好的地方。
假設(shè)有這樣一種場景:原來使用了10張表存儲數(shù)據(jù),完全沒有問題。突然有一天,業(yè)務(wù)要求現(xiàn)在使用20張表或者5張表存儲數(shù)據(jù),那該怎么辦?
由于表的個數(shù)發(fā)生變化,此時的hash函數(shù) uid%10 就應(yīng)該變?yōu)?uid%20 或者 uid%5。
此時老的數(shù)據(jù)就需要進(jìn)行處理,怎么辦?rehash!
對全量數(shù)據(jù)進(jìn)行rehash,使用新的hash函數(shù)重新計算所有數(shù)據(jù),再把這些數(shù)據(jù)存儲在新的表中。
實際開發(fā)中出現(xiàn) rehash 的場景會非常多,所以就需要提前做一些預(yù)案。
如果數(shù)據(jù)量非常大的話,一般有兩種方案:
- 停服維護(hù),在維護(hù)期間進(jìn)行數(shù)據(jù) rehash 遷移
- 異步遷移,寫數(shù)據(jù)的時候,使用新的哈希函數(shù)確認(rèn)落在哪一張表里面。查詢的時候,如果發(fā)現(xiàn)數(shù)據(jù)沒有遷移完成,則需要同時使用多個hash函數(shù),從多張表中讀取數(shù)據(jù)(假設(shè)還牽扯分頁,則會更加麻煩)。在提供服務(wù)的同時,對老數(shù)據(jù)進(jìn)行rehash遷移。
方案1需要停服,這就要看產(chǎn)品、公司業(yè)務(wù)是否允許。允許的情況之下,是最優(yōu)方案。
方案2不停服進(jìn)行遷移,相當(dāng)于邊開飛機(jī)邊換輪胎。風(fēng)險高、邏輯處理復(fù)雜。
還有就是,對于數(shù)據(jù)量大的情況之下,rehash可能會是個漫長的過程
那么,有沒有其他好的解決辦法呢?
辦法是有,解決問題的角度從遷移全量數(shù)據(jù)變成了遷移部分?jǐn)?shù)據(jù)。它就是:一致性哈希。
2. 一致性哈希
維基百科告訴我們:
一致哈希 是一種特殊的哈希算法。在使用一致哈希算法后,哈希表槽位數(shù)(大小)的改變平均只需要對K/n 個關(guān)鍵字重新映射,其中 K是關(guān)鍵字的數(shù)量,n是槽位數(shù)量。然而在傳統(tǒng)的哈希表中,添加或刪除一個槽位的幾乎需要對所有關(guān)鍵字進(jìn)行重新映射。
一致哈希由MIT的Karger及其合作者提出,現(xiàn)在這一思想已經(jīng)擴(kuò)展到其它領(lǐng)域。在這篇1997年發(fā)表的學(xué)術(shù)論文中介紹了“一致哈希”如何應(yīng)用于用戶易變的分布式Web服務(wù)中。哈希表中的每一個代表分布式系統(tǒng)中一個節(jié)點,在系統(tǒng)添加或刪除節(jié)點只需要移動 K/n項。
一致哈希也可用于實現(xiàn)健壯緩存來減少大型Web應(yīng)用中系統(tǒng)部分失效帶來的負(fù)面影響。
一致哈希的概念還被應(yīng)用于分布式散列表(DHT)的設(shè)計。DHT使用一致哈希來劃分分布式系統(tǒng)的節(jié)點。所有關(guān)鍵字都可以通過一個連接所有節(jié)點的覆蓋網(wǎng)絡(luò)高效地定位到某個節(jié)點。
David Karger及其合作者列出了使得一致哈希在互聯(lián)網(wǎng)分布式緩存中非常有用的幾個特性:
- 冗余少
- 負(fù)載均衡
- 過渡平滑
- 存儲均衡
- 關(guān)鍵詞單調(diào)
2.1 實現(xiàn)方式 - 哈希環(huán)
一致哈希將每個對象映射到圓環(huán)邊上的一個點,系統(tǒng)再將可用的節(jié)點機(jī)器映射到圓環(huán)的不同位置。查找某個對象對應(yīng)的機(jī)器時,需要用一致哈希算法計算得到對象對應(yīng)圓環(huán)邊上位置,沿著圓環(huán)邊上查找直到遇到某個節(jié)點機(jī)器,這臺機(jī)器即為對象應(yīng)該保存的位置。
當(dāng)刪除一臺節(jié)點機(jī)器時,這臺機(jī)器上保存的所有對象都要移動到下一臺機(jī)器。
添加一臺機(jī)器到圓環(huán)邊上某個點時,這個點的下一臺機(jī)器需要將這個節(jié)點前對應(yīng)的對象移動到新機(jī)器上。
更改對象在節(jié)點機(jī)器上的分布可以通過調(diào)整節(jié)點機(jī)器的位置來實現(xiàn)。
假設(shè)有一個環(huán)形結(jié)構(gòu),上面有很多節(jié)點,一般為 2的32次方。
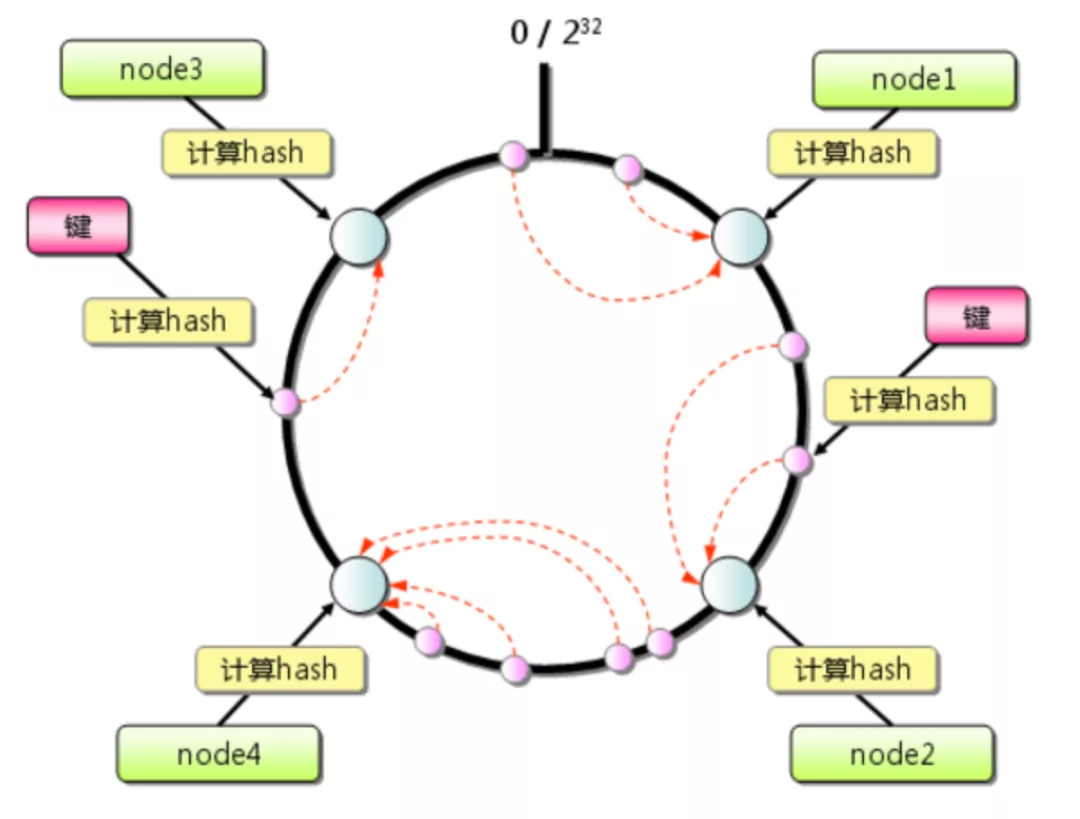
哈希環(huán)
我們需要做的事情大致如下:
對不同節(jié)點服務(wù)器的某些參數(shù)(mac地址、IP地址等)進(jìn)行hash計算,用hash值對2^32取模,確定當(dāng)前服務(wù)器落在環(huán)某一個節(jié)點上
數(shù)據(jù)存儲時,對指定的key進(jìn)行hash計算,然后用hash值對2^32取模,確定數(shù)據(jù)落在環(huán)的哪一個節(jié)點上,得到環(huán)的節(jié)點值之后,順時針方向找到遇到的第一臺服務(wù)器,這臺服務(wù)器就是存儲當(dāng)前數(shù)據(jù)的地方。
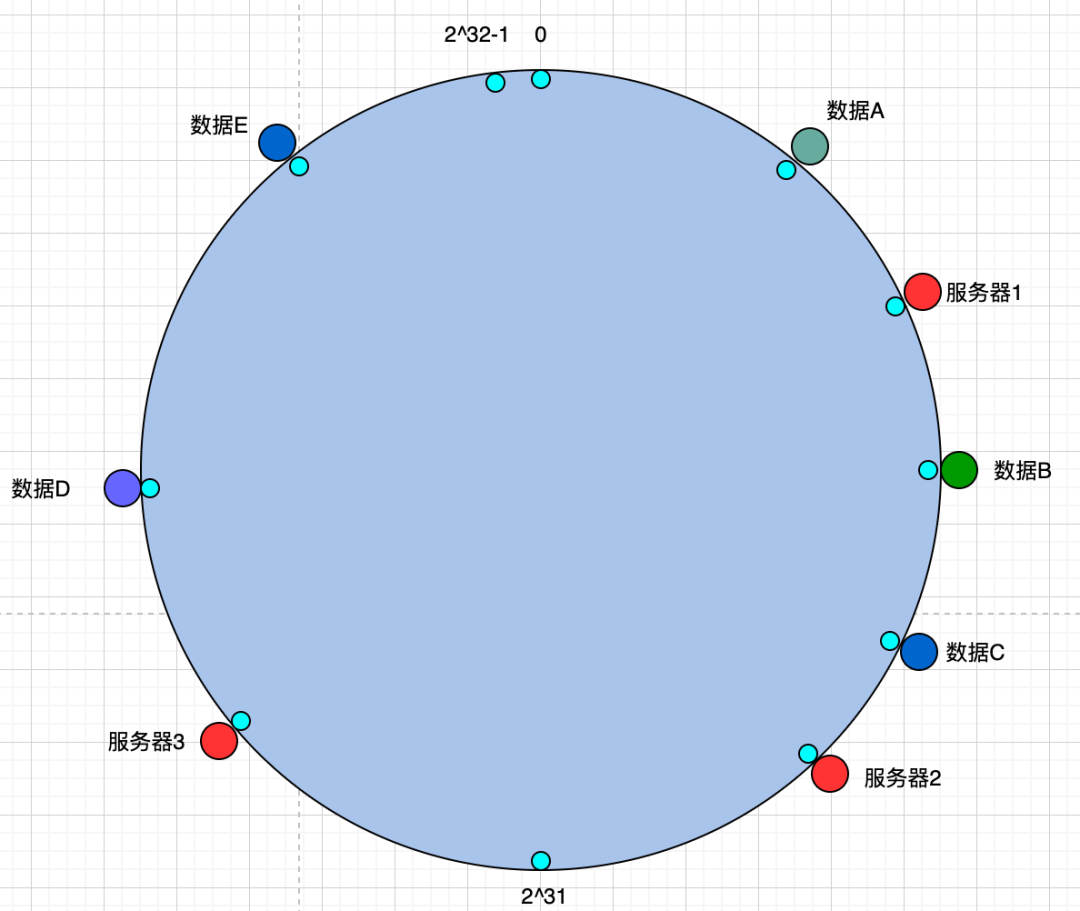
普通哈希環(huán)
從圖中可以看到,有三臺服務(wù)器分別落在哈希環(huán)的不同節(jié)點位置。數(shù)據(jù)A、B、C、D、E也落在環(huán)的不同位置。根據(jù)一致性哈希要求,數(shù)據(jù)在計算得到自己的環(huán)中節(jié)點之后,順時針找到第一個服務(wù)器節(jié)點,那臺服務(wù)器就是數(shù)據(jù)的存儲位置。
那樣的話,可知:
- 數(shù)據(jù)D、E、A存儲在服務(wù)器1
- 數(shù)據(jù)B、C存儲在服務(wù)器2
- 沒有數(shù)據(jù)存儲在服務(wù)器3
2.2 場景復(fù)現(xiàn)
場景1(縮容)
假設(shè),服務(wù)器2發(fā)生故障,存在上面的數(shù)據(jù)都需要遷移
那么,此時只需要遷移服務(wù)器1與服務(wù)器2之間的數(shù)據(jù)B、C到服務(wù)器3即可。
場景2(擴(kuò)容)
假設(shè),在數(shù)據(jù)B、C之間添加服務(wù)器4,那么只需要遷移存儲在服務(wù)器2上的數(shù)據(jù)B到服務(wù)器4即可。
通過上面兩個場景可以看出,無論是擴(kuò)容還是縮容,相對于傳統(tǒng)的hash方式,在發(fā)生擴(kuò)、縮容時,只需要遷移一部分?jǐn)?shù)據(jù)。大大簡化了數(shù)據(jù)的遷移量,也會大大降低發(fā)生問題的概率。
2.3 優(yōu)化版本的哈希環(huán)
通過上面例子可以看出:
數(shù)據(jù)D、E、A存儲在服務(wù)器1
數(shù)據(jù)B、C存儲在服務(wù)器2
沒有數(shù)據(jù)存儲在服務(wù)器3
不知道你發(fā)現(xiàn)沒有:服務(wù)器3沒有存儲數(shù)據(jù),服務(wù)器1卻存儲最多的數(shù)據(jù),此時就發(fā)生了數(shù)據(jù)傾斜。
那么,有什么辦法來解決數(shù)據(jù)傾斜嗎?
辦法就是需要對負(fù)載策略進(jìn)行優(yōu)化,引入虛擬服務(wù)器節(jié)點。
原來的一臺服務(wù)器,在哈希環(huán)上只能擁有一個節(jié)點。那么,此時我們對每一臺服務(wù)器進(jìn)行虛擬。例如:原來的服務(wù)器1,現(xiàn)在虛擬為2臺,服務(wù)器1-A、服務(wù)器1-B,此時這2臺虛擬服務(wù)器會在哈希環(huán)上擁有不同的2個節(jié)點(但是它們實際映射到同一臺真實的服務(wù)器上)。此時,哈希環(huán)就發(fā)生了變化。
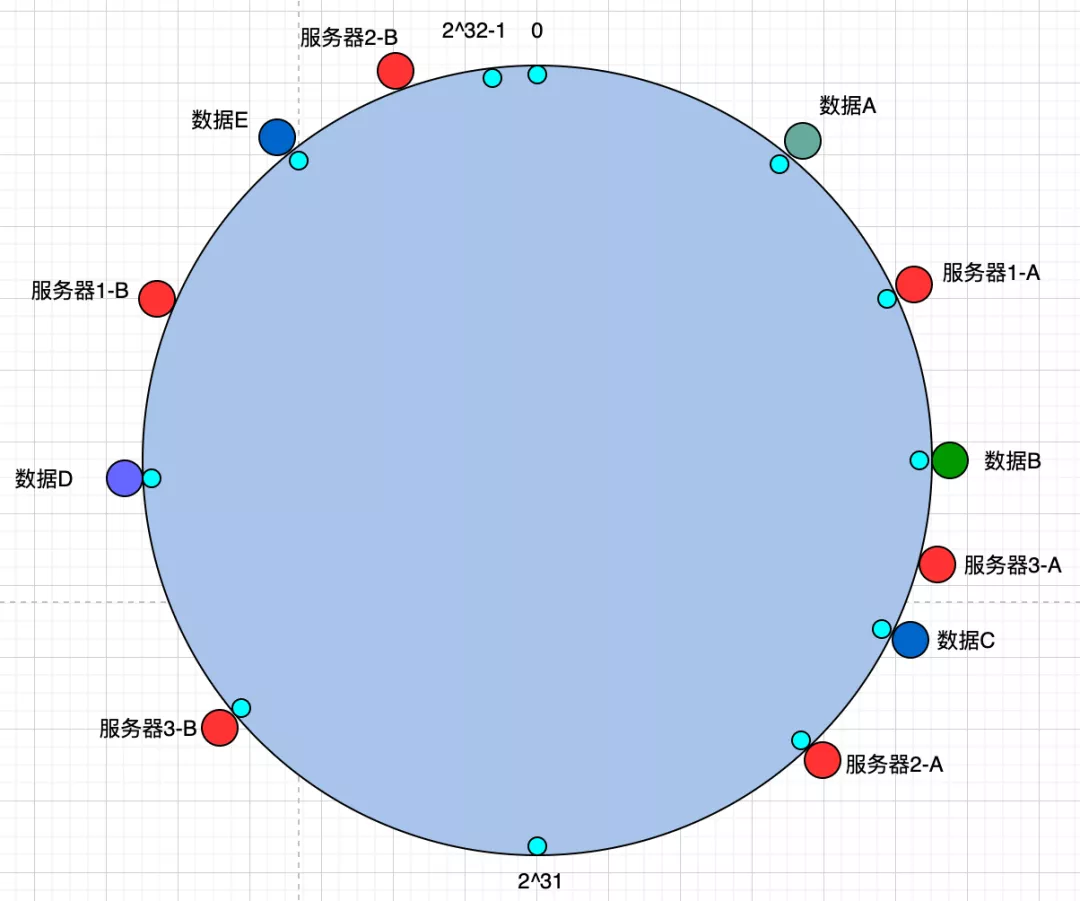
具有虛擬節(jié)點的哈希環(huán)
此時,服務(wù)器節(jié)點由原來的3個節(jié)點變?yōu)榱?個節(jié)點。
根據(jù)一致性哈希要求,數(shù)據(jù)存儲的位置變?yōu)椋?/p>
- 數(shù)據(jù)A存儲在服務(wù)器1-A
- 數(shù)據(jù)B存儲在服務(wù)器3-A
- 數(shù)據(jù)C存儲在服務(wù)器2-A
- 數(shù)據(jù)D存儲在服務(wù)器1-B
- 數(shù)據(jù)E存儲在服務(wù)器2-B
由于,上面的服務(wù)器節(jié)點為虛擬服務(wù)器節(jié)點,最終數(shù)據(jù)存儲在的真實位置:
- 數(shù)據(jù)A、D存儲在服務(wù)器1
- 數(shù)據(jù)C、E存儲在服務(wù)器2
- 數(shù)據(jù) B 存儲在服務(wù)器3
由此可見,通過引入服務(wù)器虛擬節(jié)點,數(shù)據(jù)的存儲變得比較均衡。
3. 總結(jié)
通過一系列的場景分析,我們認(rèn)識了哈希、哈希碰撞、哈希碰撞的解決辦法,并拋出了普通哈希存在的數(shù)據(jù)全量遷移問題。
同時,也找到了解決全量數(shù)據(jù)遷移的辦法——一致性哈希,通過對一致性哈希的認(rèn)識,了解到它所擁有的巨大潛力。但是,面對大數(shù)據(jù)量存儲的場景,可能會出現(xiàn)數(shù)據(jù)傾斜,造成某些服務(wù)器的高負(fù)載。在引入了服務(wù)器虛擬節(jié)點之后,對一致性哈希的負(fù)載進(jìn)行了優(yōu)化,從而達(dá)到了一種各個服務(wù)器均衡的狀態(tài)。
實際場景中,面對不同的業(yè)務(wù)或許會有些許差異。但是,大致邏輯類似。





















