













一種新型的NeRF技術(shù)可以將視頻轉(zhuǎn)換成易于控制的3D模型
譯文譯者 | 布加迪
審校 | 重樓
由于人體運動的復(fù)雜性和外觀在不同環(huán)境下的細(xì)微差異,由視頻片段創(chuàng)建逼真的動畫3D模型一直是計算機(jī)圖形學(xué)領(lǐng)域面臨的長期挑戰(zhàn)。在過去,這個過程依賴成本高昂的勞動密集型技術(shù),比如多攝像頭裝置和詳細(xì)的手動建模,因而無法用于普通或低預(yù)算的應(yīng)用系統(tǒng)。
為了解決這個問題,來自弗勞恩霍夫海因里希赫茲研究所的團(tuán)隊采用了一種新技術(shù),通過使用神經(jīng)輻射場(NeRF)來制作3D人體模型的動畫。他們的方法可以直接由標(biāo)準(zhǔn)的RGB視頻片段重建這些模型,因而不需要昂貴設(shè)備和大量人力。
這項技術(shù)向簡化動畫3D模型的創(chuàng)建邁出了一步,可能使其更唾手可得、對資源的需求更低。我們接下來將深入研究這種方法的細(xì)節(jié),分析所生成動畫的效果,并討論這一進(jìn)步對從業(yè)者和愛好者來說可能意味著什么。
追求逼真的數(shù)字人
創(chuàng)造逼真的數(shù)字人對于電影、視頻游戲和虛擬會議非常有用。但是讓這些數(shù)字人看起來逼真很困難。它們必須從每個角度、每個光線、每個姿勢來看都沒異樣,否則看起來就會很假。
目前,制作這些數(shù)字替身需要大量的工作,需要用特殊的攝像頭和設(shè)備掃描真實的人,這對大多數(shù)人來說太貴了,不切實際。
還有另一種方法,就是使用普通視頻。然而視頻是扁平的,我們失去了使事物看起來三維所需的深度。我們需要智能工具,可以計算出視頻中的物體有多深或多遠(yuǎn),使平面圖像看起來就像真實的3D人。
最近我們在這方面做得更好了,新技術(shù)可以從單單一個攝像頭角度猜測人的形狀。但仍有很多地方有待改進(jìn)。這些數(shù)字人常常看起來不太對勁——它們可能有點扭曲,或者行動不自然。真正的目標(biāo)是讓它們不僅看起來逼真,還以原始視頻中沒有的新方式來移動。
面向新視圖合成的NeRF
神經(jīng)輻射場(NeRF)是一項最新的技術(shù),用于從不同的視角創(chuàng)建逼真的3D圖像。它們的工作原理是使用算法來預(yù)測光線與場景的相互作用,從而使新圖像看起來逼真,即使是從我們從未見過的角度。
NeRF已經(jīng)成功地使靜態(tài)圖像看起來像現(xiàn)實生活中的場景。然而,用它們來創(chuàng)建人們移動和改變姿勢的圖像是比較棘手的問題。這是由于人及其移動很復(fù)雜,NeRF需要了解這種復(fù)雜性,才能創(chuàng)建清晰的畫面。
針對移動對象訓(xùn)練NeRF的傳統(tǒng)方法可能導(dǎo)致圖像模糊。為了解決這個問題,研究人員提出了一種新方法。他們使用計算機(jī)生成的人體模型來幫助指導(dǎo)NeRF。這使得NeRF能夠通過理解人體運動時的形狀和形式來創(chuàng)建不同姿勢的人的清晰精確的圖像。這種方法是重要的一步,使NeRF能夠很好地處理動態(tài)的實際內(nèi)容(如人的運動)。
技術(shù)方法:表面對齊的NeRF
這項研究提出了一種名為表面對齊神經(jīng)輻射場(UVH-NeRF)的技術(shù),它概述了由視頻片段生成詳細(xì)的3D人體圖像的過程。下面詳細(xì)介紹了該方法:
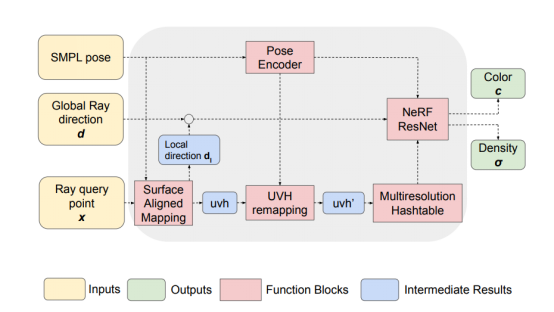 圖2. 網(wǎng)絡(luò)架構(gòu)圖
圖2. 網(wǎng)絡(luò)架構(gòu)圖
1. 針對視頻調(diào)整3D人體模型:第一步需要將3D人體模型與視頻中的主題對齊。這為后續(xù)步驟建立了一個基礎(chǔ),提供的3D結(jié)構(gòu)反映了整個視頻序列中人的形狀和運動。
2. 使NeRF適應(yīng)人體幾何圖形:該方法通過以下方式修改了傳統(tǒng)的NeRF空間:
- 將點投射到模型的表面上:它定位3D模型表面上與視頻中位置相對應(yīng)的點。這些點用于將2D圖像的紋理映射到模型上。
- 計算到模型表面的距離:對于空間中的每個點,該技術(shù)計算其到模型表面的距離,這有助于確定該點相對于模型的位置(在模型內(nèi)部、在模型表面上或在模型外部)。
- 結(jié)合關(guān)節(jié)運動:它使用骨骼關(guān)節(jié)數(shù)據(jù)來繪制模型動畫,這有助于渲染不同姿勢的人。
3. 用神經(jīng)網(wǎng)絡(luò)改進(jìn)空間理解:神經(jīng)網(wǎng)絡(luò)被教會了微調(diào)這種空間轉(zhuǎn)換,確保NeRF對空間的表示是準(zhǔn)確的,并與人類模型保持一致。
進(jìn)一步的詳情包括如下:
- 保持一致的結(jié)構(gòu):該技術(shù)使用SMPL模型保持統(tǒng)一的結(jié)構(gòu),以準(zhǔn)確地反映人在不同幀中的姿勢。
- 轉(zhuǎn)變NeRF的視角:這種方法改變了NeRF對空間的感知,以模仿人體的形式。不管人的動作如何,它都保持穩(wěn)定。
- 創(chuàng)建姿勢準(zhǔn)確的渲染圖:通過將骨骼數(shù)據(jù)集成到NeRF中,系統(tǒng)可以生成任何某個姿勢的解剖學(xué)正確的圖像。
- 糾正差異:神經(jīng)映射模塊針對模型或轉(zhuǎn)換中的任何微小錯誤進(jìn)行調(diào)整,確保對齊和一致性。
這些步驟最終允許NeRF以各種姿勢和視角學(xué)習(xí)人體模型和制作動畫,從而創(chuàng)建一個人的多功能動態(tài)的3D表示。這一進(jìn)步為數(shù)字媒體、虛擬現(xiàn)實和其他需要高保真人類化身的領(lǐng)域的應(yīng)用帶來了巨大的希望。
結(jié)果

當(dāng)你看圖像時,左邊是AI的猜測,右邊是真實情況,你會發(fā)現(xiàn)它們非常接近。AI生成的人物擺出了正確的姿勢,甚至衣服似乎也如同該有的那樣折疊和起皺。好像AI有一雙慧眼,能看到人們做事時衣服的運動方式。
但說實話,這并不完美。如果你瞇眼睛,會看到那些失真的細(xì)節(jié)。AI在精細(xì)操作方面有些棘手——手指可能變得模糊,面部特征可能不準(zhǔn)確。這與蠟像看起來怪怪的同一個道理,但對于一臺僅用幾幀就能生成這些圖像的電腦來說,這仍然相當(dāng)出彩。
這項技術(shù)大有前途。想想虛擬現(xiàn)實和增強(qiáng)現(xiàn)實,你想讓人們看起來盡可能真實,而不必穿那些帶著乒乓球的滑稽服裝。

當(dāng)然,在達(dá)到一流水平之前,它還有更多的工作要做,但即使這樣,它也朝著讓數(shù)字人暢游各種虛擬空間邁出了堅實的一步。
結(jié)論
本文研究的關(guān)鍵創(chuàng)新是成功地將神經(jīng)輻射場應(yīng)用于僅使用標(biāo)準(zhǔn)RGB視頻片段的3D人體模型動畫。這種方法大大簡化了創(chuàng)造數(shù)字人這個傳統(tǒng)的資源密集型過程——這通常需要復(fù)雜的攝像頭裝置和人力。通過證明NeRF可以針對動態(tài)內(nèi)容(比如來自比較易于獲取的視頻的人體運動)加以調(diào)整,本文介紹了一種實用的方法,可以更廣泛地應(yīng)用于各個領(lǐng)域。
這一進(jìn)步表明,該領(lǐng)域的未來發(fā)展可能便于更經(jīng)濟(jì)、更高效地生成數(shù)字人體模型,這可能會造福游戲、虛擬現(xiàn)實和電影等行業(yè)。雖然目前的方法有其局限性,特別是對于復(fù)雜的移動和較長的序列而言,但它為進(jìn)一步的研究和改進(jìn)奠定了基礎(chǔ)。
從本質(zhì)上講,這項工作是朝著使人體模型數(shù)字化更唾手可得邁出的一步,為其應(yīng)用范圍由專業(yè)工作室擴(kuò)大到個人創(chuàng)作者和小型制作團(tuán)隊提供了可能性。
原文標(biāo)題:They found a new NeRF technique to turn videos into controllable 3D models,作者:Mike Young






















