能總結經驗、持續進化,上交把智能體優化參數的成本打下來了
大模型的出現引發了智能體設計的革命性變革,在 ChatGPT 及其插件系統問世后,對大模型智能體的設計和開發吸引了極大的關注。幫助完成預訂、下單等任務,協助編寫文案,自主從網絡上搜索最新的知識與新聞等等,這種通用、強大的智能助理,讓大模型強大的語義理解、推理能力將之變成了可能。

為了提升大模型智能體交互的性能和可靠性,目前學界已經提出了多種基于不同提示語技術的智能體框架,如將思維鏈結合至決策過程的 ReAct、利用大模型的自檢查能力的 RCI 等。
盡管大模型智能體已經表現出強大的能力,但上述方案都缺乏讓大模型智能體從自身的既往交互經歷中學習進化的能力。而這種持續進化的能力,正成為大模型智能體發展中亟待解決的問題。
一般來說,決策交互任務中通常會采用強化學習,基于過往交互歷程來優化智能體的交互策略,但對于大模型來說,直接優化其參數的代價巨大。
Algorithm Distillation(算法蒸餾)等工作提出了 「即境強化學習」(in-context reinforcement learning)的概念,將強化學習訓練過程輸入預訓練過的決策 transformer,就可以讓模型在不需要更新參數的情況下,從輸入的訓練歷程中學習到性能演進的模式,并優化下一步輸出的策略。
然而這種模式卻難以直接應用于文本大模型。因為復雜的觀測、動作表示成文本需要消耗更多的詞元(token),這將導致完整的訓練歷程難以塞入有限的上下文。
針對該問題,上海交通大學跨媒體語言智能實驗室(X-LANCE)提出了一種解決方案:通過外置經驗記憶來保存大模型的交互歷史,憑借強化學習來更新經驗記憶中的經歷,就可以讓整個智能體系統的交互性能得到進化。這樣設計出來的智能體構成了一種半參數化的強化學習系統。論文已由 NeurIPS 2023 接收。

論文地址:https://arxiv.org/abs/2306.07929
實驗顯示,通過該方法設計的 「憶者」(Rememberer)智能體,在有效性與穩定性上均展現出了優勢,超越了此前的研究成果,建立了新的性能基準。
方法

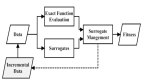
「憶者」智能體的技術架構
該工作為 「憶者」 智能體設計了一種 RLEM(Reinforcement Learning with Experience Memory)框架,使得智能體能夠在交互中,根據當前交互狀態從經驗記憶中動態抽取過往經驗來提升自身的交互行為,同時還可以利用環境返回的回報(reward)來更新經驗記憶,使得整體策略得到持久改進。
在經驗記憶中存儲任務目標 、觀測
、觀測 、候選動作
、候選動作 以及對應的累積回報(Q 值)
以及對應的累積回報(Q 值) 。訓練中,可以采用多步 Q 學習來更新記憶池中記錄的 Q 值
。訓練中,可以采用多步 Q 學習來更新記憶池中記錄的 Q 值  :
:


在推斷過程中,智能體依據任務相似度與觀測相似度,從經驗記憶中提取最相似的 k 條經歷,來構成即境學習(in-context learning)的范例。
由于訓練過程中得到的經歷有成功的也有失敗的,不同于此前基于經驗記憶的方法只利用成功的經歷,該工作提出了一種特別的輸出格式來將失敗經歷也加以利用。
這種輸出格式稱為 「動作建議」(action advice),即要求模型輸出時同時輸出推薦的(encouraged)與不推薦的(discouraged)動作及其 Q 值估計,從而促使模型能夠學習到范例中部分動作的失敗,并在新的決策中避免。
結果
該工作在 WebShop 與 WikiHow 兩個任務集上測試了所提出的 「憶者」智能體。


測試了采用不同初始經歷、不同訓練集構建的 「憶者」智能體,相比于 ReAct 及采用靜態范例的基線,「憶者」不僅取得了更高的平均性能,而且性能對各種不同的初始化條件更加穩定,展現了巨大的優勢。
同時還采用人類標注的經驗記憶(Rememberer (A))做了實驗,證明了所設計的相似度函數提取出的動態范例的有效,同時也證明,強化學習訓練相比人類標注的經驗記憶能夠取得更好的性能。

消融實驗的結果也證實了所采用的多步 Q 學習以及 「動作建議」輸出格式的作用。

這一結果也證明,訓練過程中,通過更新經驗記憶,「憶者」智能體的交互性能確實在逐步進化,進一步說明了所設計方法的有效。
結論
針對大模型智能體難以利用自身交互經歷進化自身交互性能的問題,上海交通大學跨媒體語言智能實驗室(X-LANCE)提出了 RLEM 框架,設計了「憶者」智能體。實驗結果顯示,通過增強以外置經驗記憶,并輔以強化學習對經驗記憶更新,「憶者」智能體能夠充分利用自身的交互經歷進化交互策略,顯著提升在基準任務集上的性能。
該工作為大模型智能體進化自身性能,以及將大模型智能體與強化學習結合,提供了富有價值的方案和見解,未來或有機會在此方向上探索得更深更遠。