













聊一聊幾款主流消息隊列之間的差異,我們應該如何選擇
為什么需要消息隊列
消息隊列是歷史最悠久的中間件之一,它可以和不同的進程進行通信,從而實現上下游之間的消息傳遞。基于此特性,我們可以在以下三個場景中使用消息隊列。
- 解耦;
- 限流;
- 流量削峰;
1)解耦
先來看解耦,假設有兩個服務:A 和 B,當服務 A 依賴服務 B 時,請求的耗時就是這兩個服務之和。但如果服務 B 耗時比較長怎么辦?
顯然這時服務 A 可以將消息發送到隊列中,服務 B 從隊列里面去取即可,從而實現兩個服務之間的邏輯解耦 + 物理解耦。
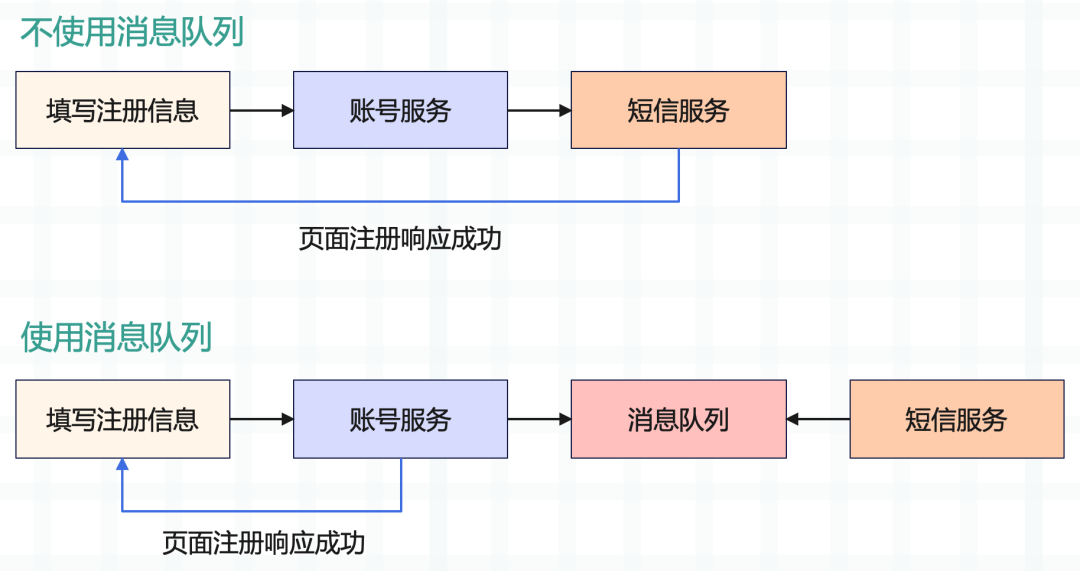
當用戶注冊賬號時,會將注冊信息發給賬號服務,賬號服務將信息寫入數據庫后,會調用短信服務給用戶發送短信。如果不使用消息隊列,那么必須等短信發送成功之后才能返回。
但為了給用戶更好的體驗,我們可以將發送短信這一步獨立出去,賬號服務將用戶手機號和短信內容投入消息隊列中就可以返回了,這樣用戶就能立刻收到注冊結果。而短信服務會消費消息,異步執行發送短信邏輯,這就是消息隊列的作用之一:解耦。
使用消息隊列進行解耦,不僅可以提升性能,還可以使整個系統更加的模塊化。以電商為例,訂單服務是電商系統中的核心部分,它會被一系列下游服務依賴。并且隨著業務的發展,依賴訂單的下游服務會不斷增加、不斷變化。
因此負責訂單服務的開發團隊不得不花費大量精力,應對不斷增加變化的下游服務,不停地修改調試訂單服務與這些下游服務的接口。任何一個下游服務的接口產生變更,都需要訂單模塊重新進行一次上線,對于一個電商的核心服務來說,這幾乎是不可接受的。
因此所有的電商系統都選擇用消息隊列,來解決這種系統耦合過于緊密的問題。引入消息隊列后,訂單服務在訂單變化時發送一條消息到消息隊列的一個主題 order 中,所有下游服務都訂閱主題 order,這樣每個下游服務都可以獲得一份實時完整的訂單數據。并且此時下游服務發生變化,不會影響訂單服務。
2)限流
一個完善的系統一定具備自我保護的能力,即使面對海量請求,也能盡最大努力去處理,處理不了的則會拒絕掉,從而保證系統運行正常。因此如果我們能預估出系統的最大處理能力,就可以用消息隊列實現一個令牌桶,進行流量控制。
令牌桶控制流量的原理是:單位時間內發放固定數量的令牌到令牌桶中,規定服務在處理請求之前必須先從桶中取走一個令牌,如果桶里面沒有令牌,則拒絕請求。這樣就保證單位時間內,能處理的請求數不超過發放令牌的數量,起到了流量控制的作用。
令牌桶可以簡單地用一個有固定容量的消息隊列加一個令牌生成器來實現:令牌生成器按照預估的處理能力,勻速生產令牌并放入令牌隊列(如果隊列滿了則丟棄令牌)。網關(流量的入口)在收到請求時從令牌隊列消費一個令牌,獲取到令牌則繼續調用后端服務,如果獲取不到令牌則直接返回失敗。
3)流量削峰
任何的大型服務,特別是秒殺服務,都離不開消息隊列。因為消息隊列除了解耦和限流之外,還可以起到流量削峰的作用,就是緩沖瞬時的突發流量,使其更平滑。
對于那些發送能力很強的上游系統,如果沒有消息隊列的保護,脆弱的下游系統可能會直接被壓垮導致全鏈路服務雪崩。而一旦有了消息隊列,它就能夠有效地對抗上游的流量沖擊,避免了流量的震蕩。
我們舉一個實際的例子,比如在京東購買商品,當點擊購買的時候,會調用訂單服務生成對應的訂單。然而要處理該訂單則會依次調用下游的多個子服務,比如查詢登錄信息、驗證商品信息、確認地址信息,調用銀行等支付接口進行扣款等等。
顯然上游的訂單操作比較簡單,它的 TPS 要遠高于處理訂單的下游服務。因此如果上游和下游直接對接,勢必會出現下游服務無法及時處理上游訂單從而造成訂單堆積的情況。特別是當出現雙十一以及秒殺業務的時候,上游訂單流量會瞬間增加,可能出現的結果就是直接壓垮下游子系統服務。
解決此問題的一個做法是對上游的訂單服務進行限流,比如采用上面說的令牌桶。但對于一個電商系統來說,這么做很明顯是不合適的,因為問題不是出現在訂單服務上面,而且用戶買東西還限流,這樣錢送到嘴邊都賺不到。
所以會引入消息隊列來對抗這種上下游系統的 TPS 不一致以及瞬時的峰值流量,引入消息隊列之后,上游系統不再直接與下游系統進行交互。當新訂單生成之后它僅僅向隊列中發送一條消息,而下游消費隊列中的消息,從而實現上游訂單服務和下游訂單處理服務的解耦。
這樣當出現秒殺業務的時候,消息隊列能夠將瞬時增加的訂單流量全部以消息的形式保存在隊列中,既不影響上游服務的 TPS,同時也給下游服務留出了足夠的時間去消費,這就是消息隊列存在的最大意義所在。
簡單來說,我們在單體應用里面需要使用本地隊列解決的問題,在分布式系統中大多都可以用消息隊列來解決。但同時我們也要認識到,消息隊列也有它的一些問題:
- 引入消息隊列帶來的延遲問題;
- 增加了系統的復雜度;
- 可能產生數據不一致的問題;
所以在軟件開發中沒有銀彈,需要根據業務的特點和自身條件選擇合適的架構。
消息隊列該怎么選擇
消息隊列如同數據結構一樣,沒有最好的,只有最合適的。但不管哪種消息隊列,如果想要用于生產環境中,都應該具備以下幾個特點:
- 消息的傳遞一定是可靠的;
- 支持阻塞等待拉取消息;
- 支持發布 / 訂閱模式;
- 具備 ack 機制,消費失敗后可重新消費,消息不丟失;
- 實例宕機了,消息也不會丟失,也就是支持數據持久化;
- 消息可積壓;
- 支持集群部署;
- 開源免費,社區具有一定的活躍度;
- 生態完善;
- 性能足夠好,能滿足絕大部分場景;
符合以上需求的消息隊列,主要有以下幾種。
1)RabbitMQ
RabbitMQ 是一個在 AMQP(高級消息隊列協議)基礎上完成的可復用的企業消息系統,最早為電信行業系統之間的可靠通信而設計,是當前最主流的消息隊列之一。
早期的 RabbitMQ 只支持 AMQP 協議,現在也支持 MQTT 協議。
RabbitMQ 都具備哪些優點呢?
- 采用 Erlang 語言編寫,Erlang 語言最初用于交換機領域,它有著和原生 socket 一樣的延遲,因此性能較好,吞吐量在萬級,并且時效性在微秒級。
- 功能完善,健壯、穩定、易用、跨平臺。
- 支持大部分主流語言,文檔豐富,還提供了管理界面,并擁有非常高的社區活躍度和更新頻率。
有優點,自然就有缺點,缺點如下:
- RabbitMQ 對消息堆積的支持并不好,在它的設計理念里面,消息隊列是一個管道,大量的消息積壓是一種不正常的情況,應當盡量去避免。當大量消息積壓的時候,會導致 RabbitMQ 的性能急劇下降。
- RabbitMQ 的性能比較差,根據官方給出的測試數據以及使用經驗,隨著硬件配置的不同,它大概每秒鐘可以處理幾萬到十幾萬條消息。其實這個性能也足夠支撐絕大多數的應用場景了,但如果你的應用對消息隊列的性能要求非常高,那就不適合選擇 RabbitMQ 了。
- RabbitMQ 使用的編程語言 Erlang,這個編程語言不僅非常小眾,學習曲線也很陡峭。
2)RocketMQ
阿里巴巴開源的一款消息隊列,用 Java 語言實現,在設計時參考了 Kafka,并做了一些改進。在阿里內部廣泛應用于訂單、交易、重置、流計算、消息推送、日志流式處理、以及 binlog 分發等場景,經歷過多次雙十一考驗,其性能、穩定性和可靠性都是值得信賴的。
優點如下:
- 支持單機吞吐量達到數十萬級,可用性高,分布式架構保證消息零丟失;
- 功能較為完善,擴展性好,支持 10 億級別的消息堆積,不會因為消息堆積導致性能下降;
- 對在線業務的響應時延做了很多的優化,大多數情況下可以做到毫秒級的響應;
所以 RocketMQ 在吞吐量和消息堆積方面要比 RabbitMQ 高很多,如果你比較在意這兩個方面,那么可以使用 RocketMQ。而 RocketMQ 的缺點就是支持的客戶端語言不多,社區活躍度一般。
3)Kafka
大數據的殺手锏,談到大數據領域的消息傳輸,必然離不開 Kafka。這款為大數據而生的消息隊列,有著百分級 TPS 的吞吐量,在數據采集、傳輸、存儲的過程中發揮至關重要的作用,任何的大公司、或者做大數據的公司都離不開 Kafka。
- Kafka 的特點是性能卓越,單機寫入 TPS 在百萬條每秒,時效性也在毫秒級。
- Kafka 是分布式的,一個數據多個副本,少數的機器宕機也不會丟失數據。
- 消費者采用 pull 方式獲取消息,消息有序、并且可以保證所有消息被消費且僅被消費一次。
- 擁有優秀的第三方 Kafka Web 管理界面 Kafka-Manager,在日志領域比較成熟,在大數據領域的實時計算以及日志采集等場景中被大規模使用。
- 和周邊生態系統的兼容性非常好,在大數據和流計算領域,幾乎所有的開源軟件系統都會優先支持 kafka。
Kafka 使用 Scala 和 Java 語言開發,設計上大量使用了批量和異步的思想,這種設計使得 Kafka 能做到超高的性能。但也正是這種異步批量設計使得 Kafka 的響應時延比較高,因為客戶端發送消息的時候,不會立即發出,而是攢夠一批之后一起發送。
所以 Kafka 不太適合在線業務場景,它的重點是吞吐量,而不是低延遲。并且 Kafka 還有如下缺點:
- 單機超過 64 個分區,CPU 使用率會發生明顯的飆高現象,隊列越多 CPU 使用率越高,發送消息響應時間變長;
- 使用短輪詢方式,實時性取決于輪詢間隔時間,消費失敗不支持重試;
- 雖然支持消息有序,但如果某臺機器宕機,就會產生消息亂序。
那么這些消息隊列,我應該選擇哪一種呢?
RabbitMQ:如果說消息隊列并不是你系統的主角之一,你對消息隊列的功能和性能都沒有很高的要求,只需要一個開箱即用易于維護的產品,建議使用 RabbitMQ。
RocketMQ:天生為金融領域而生,適合可靠性要求很高的場景,尤其是電商里面的訂單扣款、以及業務削峰。RocketMQ 在穩定性上絕對值得信賴,畢竟這些業務場景在阿里雙十一已經經歷了多次考驗,如果你的業務也有類似場景,那么建議選擇 RocketMQ。
Kafka:基于 Pull 模式來處理消息,追求高吞吐量,一開始的目的就是用于日志收集和傳輸,高吞吐量是 Kakfka 的目標。因此如果要處理海量的消息(比如日志采集、監控信息、前端埋點),或者使用了大數據、流計算相關的開源產品,那么首選 Kafka。
消息隊列的存儲模型
任何一款消息隊列,都可以視為三部分:生產者、broker、消費者。
- 生產者和消費者都可以視為客戶端;
- broker 便是服務端啟動之后的進程,比如 Kafka broker;
生產者會將消息發送至 broker 中,broker 會對消息進行存儲以及持久化,消費者負責從 broker 中拉取消息。如果拋開那些花里胡哨的概念,其實整個過程是非常簡單的。
而這里我們要探討的是,消息在隊列中是如何存儲的?
最初的消息隊列,就是一個嚴格意義上的隊列,它是一個先進先出的線性表,通常使用鏈表或數組來實現。隊列只允許在后端(稱為 rear)進行插入操作,在前端(稱為 front)進行刪除操作。
這個定義里面包含幾個關鍵點:
- 先進先出:這意味著消息在入隊和出隊的過程中,需要保證這些消息嚴格有序,消息的寫入順序和讀取順序是一致的;
- 早期的消息隊列,就是按照隊列的數據結構來設計的;
- 生產者發消息是入隊操作,消費者收消息是出隊(刪除)操作;
- 服務端存放消息的容器自然就是隊列

如果有多個生產者往同一個隊列里面發消息,這個隊列中可以消費到的消息就是這些生產者生產的所有消息的合集,消息的順序就是這些生產者發送消息的自然順序。
同理,如果有多個消費者接收同一個隊列的消息,這些消費者之間就是競爭關系,每個消費者只能收到隊列中的一部分消息,也就是說任何一條消息只能被其中的一個消費者收到。
如果需要將一份消息數據分發給多個消費者,要求每個消費者都能收到全量的消息,比如一份訂單數據,要求風控系統、分析系統、支付系統等都需要接收消息。這時單個隊列就滿足不了需求,一個可行的解決方式是,為每個消費者創建一個單獨的隊列,讓生產者發送多份。
顯然這是個比較笨的做法,同樣的一份消息被復制到多個隊列中會浪費資源。更重要的是,生產者必須知道有多少個消費者,為每個消費者單獨發送一份消息,這實際上違背了消息隊列的解耦這個設計初衷。
為了解決這個問題,演化出了另外一種消息模型:發布/訂閱模型。
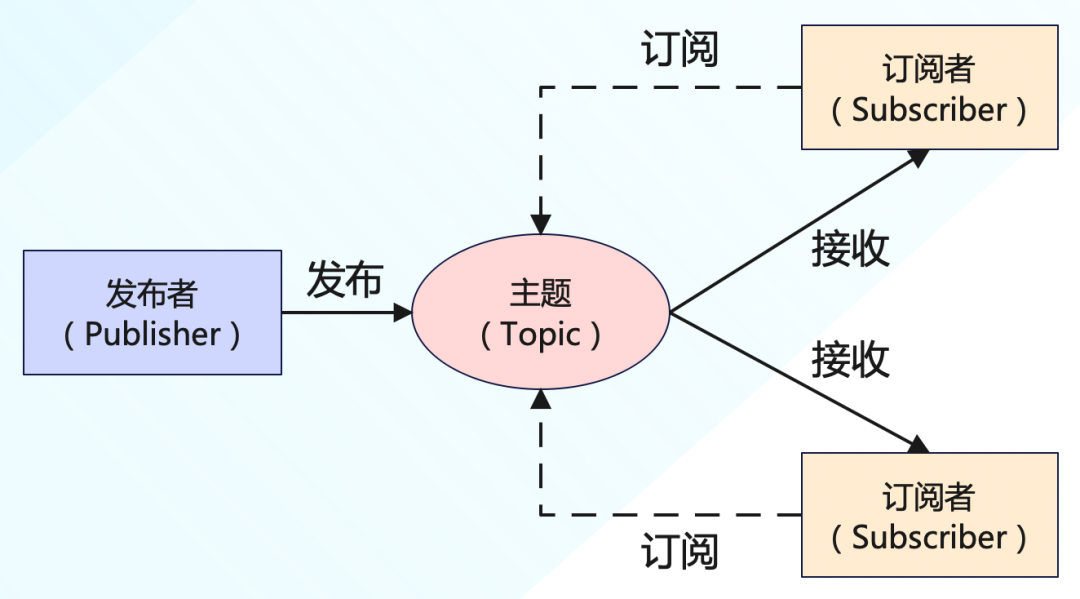
在發布/訂閱模型中,消息的發送方被稱為發布者(Publisher),消息的接收方被稱為訂閱者(Subscriber),服務端存放消息的容器稱為主題(Topic)。發布者將消息發送到主題中,訂閱者在接收消息之前需要先訂閱主題,每份訂閱中,訂閱者都可以接收到主題的所有消息。
在消息領域的歷史上很長的一段時間,隊列模式和發布/訂閱模式是并存的,有些消息隊列同時支持這兩種消息模型。但我們仔細對比一下這兩種模型,會發現它們并沒有本質的區別,生產者就是發布者,消費者就是訂閱者,隊列就是主題。它們最大的區別其實就是,一份消息數據能不能被消費多次的問題。
實際上,在這種發布/訂閱模型中,如果只有一個訂閱者,那它和隊列模型就基本是一樣的了,因此發布/訂閱模型在功能層面上可以兼容隊列模型。
現代的消息隊列產品使用的消息模型大多是這種發布/訂閱模型,當然也有例外。
RabbitMQ 的消息模型
RabbitMQ 是少數依然堅持使用隊列模型的產品之一,那它是怎么解決多個消費者的問題呢?在 RabbitMQ 里面有一個別的消息隊列都沒有的概念:Exchange(交換機),它位于生產者和隊列之間,生產者并不關心將消息發送給哪個隊列,而是將消息發送給 Exchange,由 Exchange 上配置的策略來決定將消息投遞到哪些隊列中。
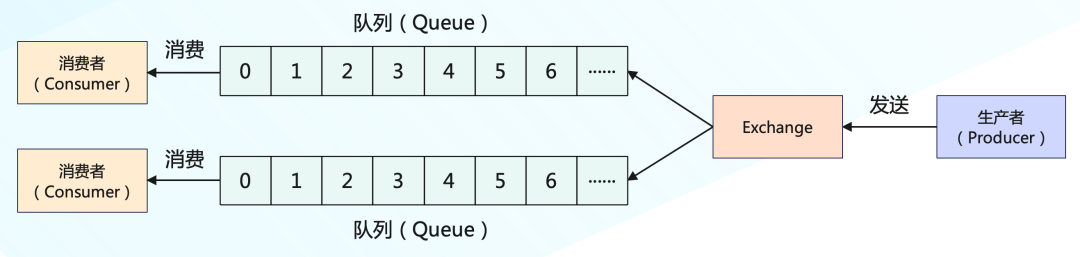
同一份消息如果需要被多個消費者消費,則需要配置 Exchange 將消息發送到多個隊列,每個隊列中都存放一份完整的消息數據,可以為一個消費者提供消費服務。這也可以變相地實現發布/訂閱模型中,一份消息數據可以被多個訂閱者來多次消費這樣的功能。
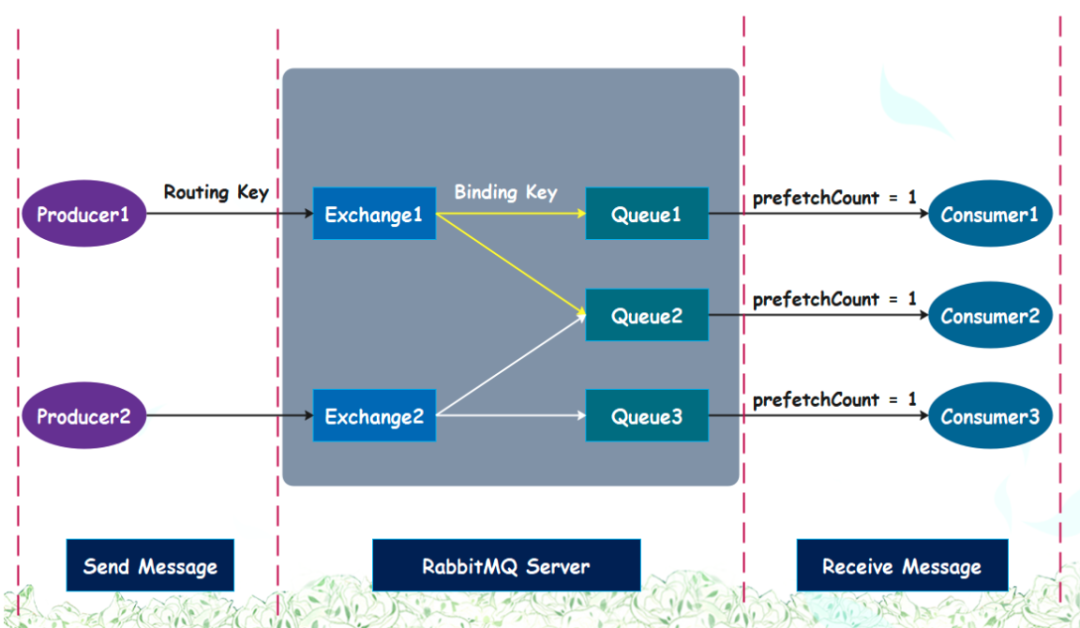
所以 RabbitMQ 消息傳遞模型的核心思想是:生產不會直接將消息發送到隊列,而是先發送到交換機。交換機的工作內容就是接收生產者的消息,并且按照指定的規則將消息推入隊列,因此交換機必須清楚地知道如何處理接收到的消息,是把這些消息推送到特定隊列、還是多個隊列,亦或是丟棄它們,這要由交換機的類型決定。
交換機有 4 種類型:direct、fanout、topic、headers,默認是 direct,不同的類型的交換機會有不同的表現。
RabbitMQ 會通過 Binding 將 Exchange 和 Queue 綁定在一起,并且在綁定 Exchange 和 Queue 的同時(可多次綁定),會指定一個 Binding key。而生產者將消息發送到 Exchange 的時候,也會帶上一個 Routing key。
- 如果交換機的類型是 direct,它會將消息推送到 Binding Key 和 Routing Key 相匹配的 Queue 中。因為交換機和隊列可以多次綁定,所以一個隊列可以有多個 Binding Key,只要一個能匹配上即可;
- 如果交換機的類型是 fanout,它會直接把消息推送到所有與它綁定的隊列中;
- 如果交換機的類型是 topic,那么 Binding Key 會支持 * 通配符,從而和 Routing Key 進行模糊匹配;
- 如果交換機類型是 headers,會根據發送的消息內容中的 headers 屬性進行匹配;
RocketMQ 的消息模型
RocketMQ 使用標準的發布/訂閱模型,但它除了生產者、消費者和主題之外,也有隊列這個概念,并且隊列在 RocketMQ 中是一個非常重要的概念。每個主題包含多個隊列,通過多個隊列來實現并行生產和消費。需要注意的是,RocketMQ 只在隊列上保證消息的有序性,主題層面是無法保證消息的嚴格順序的。
RocketMQ 中,訂閱者的概念是通過消費者組(Consumer Group)來體現的,每個消費者組都消費主題中一份完整的消息,不同消費者組之間消費進度彼此不受影響。也就是說,一條消息被 Consumer Group1 消費過,也可以再給 Consumer Group2 消費。
但消費者組中包含多個消費者,同一個組內的消費者是競爭關系,每個消費者負責消費組內的一部分消息。如果一條消息被消費者 Consumer1 消費了,那同組的其它消費者就不會再收到這條消息。
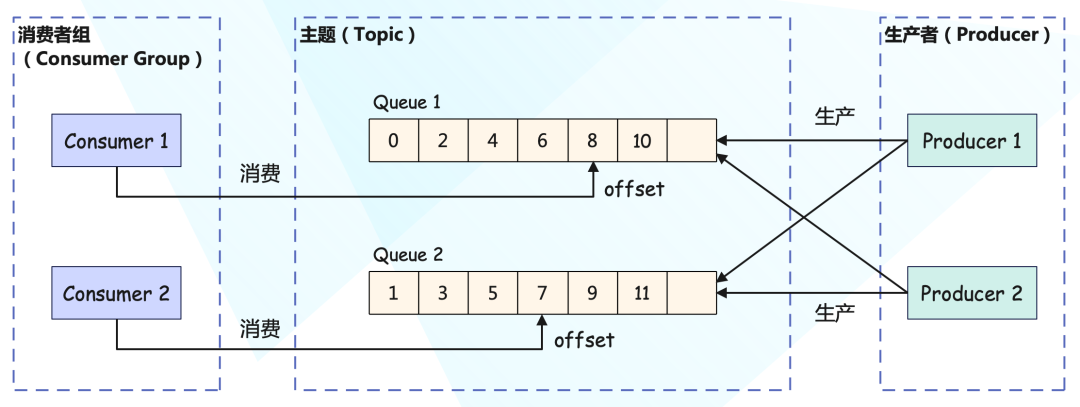
在 Topic 的消費過程中,由于消息需要被不同的組進行多次消費,所以消費完的消息并不會立即被刪除,這就需要 RocketMQ 為每個消費者組在每個隊列上維護一個消費位移(Consumer Offset)。這個位移之前的消息都被消費過,之后的消息都沒有被消費過,每成功消費一條消息,消費位移就加一。
如果你對 RocketMQ 中的這些概念還有些困惑的話,那么沒關系,我們看一下 Kafka 的消息模型。如果你熟悉 Kafka 的話,那么你會瞬間理解 RocketMQ。
Kafka 的消息模型
Kafka 的消息模型和 RocketMQ 是完全一樣的,上面說的所有 RocketMQ 中的概念,和生產消費過程中的確認機制,都完全適用于 Kafka。唯一的區別是,在 Kafka 中,隊列這個概念的名稱不一樣,Kafka 中對應的名稱是分區(Partition),但含義以及功能和 RocketMQ 的隊列是沒有任何區別的。
所以如果你熟悉 Kafka,那么你會瞬間理解 RocketMQ,因為兩者的消息模型是一樣的。只不過 RocketMQ 是一個主題對應多個隊列,而 Kafka 是一個主題對應多個分區。
小結
以上我們就探討了消息隊列的應用場景,以及它們存儲模型之間差異。關于這些隊列更詳細的內容,可以參考網上的資料。
總之當你的數據量不大時,使用 RabbitMQ 是一個不錯的選擇。



















