語言作“紐帶”,拳打腳踢各模態(tài),超越Imagebind
北大聯(lián)合騰訊打造了一個多模態(tài)15邊形戰(zhàn)士!
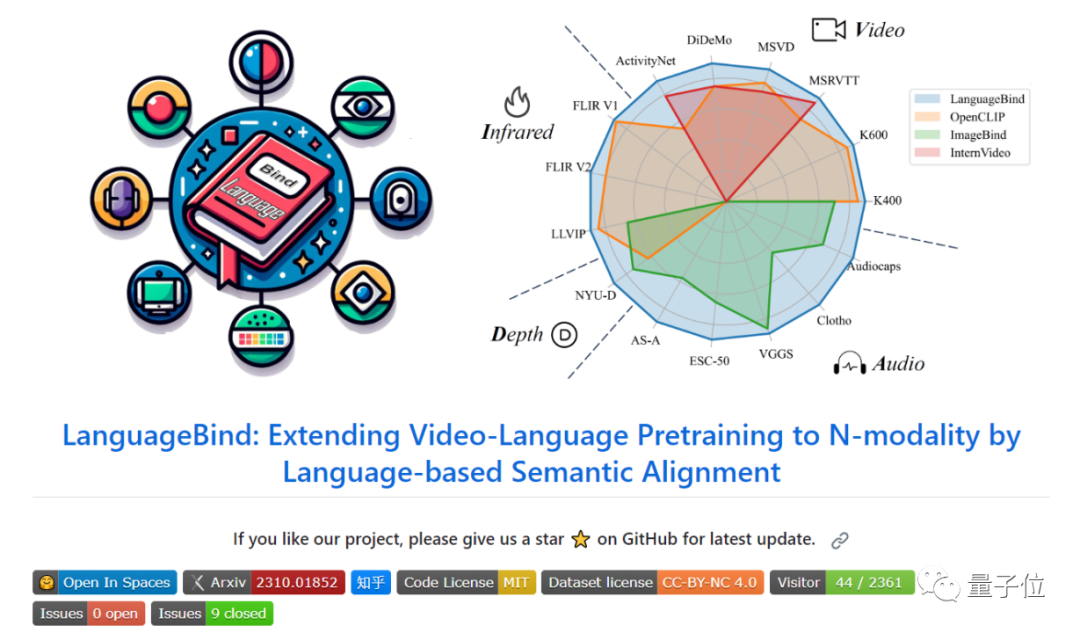
以語言為中心,“拳打腳踢”視頻、音頻、深度、紅外理解等各模態(tài)。
具體來說,研究人員提出了一個叫做LanguageBind的多模態(tài)預訓練框架。
用語言作為與其它模態(tài)之間的紐帶,凍結語言編碼器,然后用對比學習方法,將各個模態(tài)映射到一個共享的特征空間,實現多模態(tài)數據的語義對齊。
使用這種方法,模型在5個數據集上的性能拿下新SOTA,在15個zero-shot檢索等任務中取得了顯著的性能提升,全面超越ImageBind、OpenCLIP。

將各模態(tài)與語言綁定
LanguageBind包含三個部分:
多模態(tài)編碼器(Multi-modal Encoders),語言編碼器(Language Encoder),以及多模態(tài)聯(lián)合學習(Multi-modal Joint Learning)。
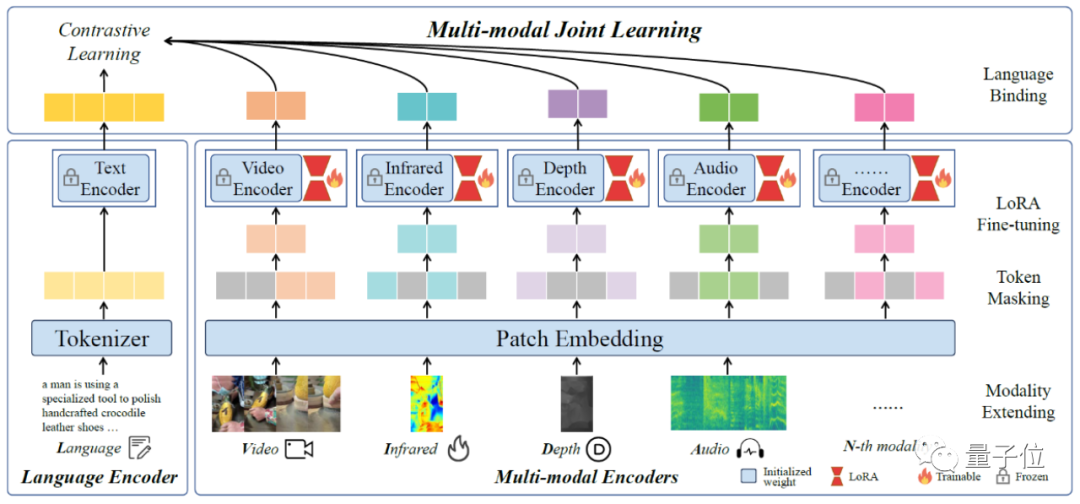
先來看多模態(tài)編碼器部分。
除了語言之外的其它模態(tài),研究人員使用24層、1024維的視覺Transformer,具有14的Patch大小。編碼器是從OpenCLIP-large初始化的。
深度和紅外被視為RGB圖像,在通道維度上復制3次與RGB圖像對齊。
按照ImageBind的方式,音頻數據被轉換為持續(xù)10秒(128個mel-bins)的頻譜圖,并進行重復和填充。
- Patch masking
為了解決在編碼器中處理所有Token的低效問題,研究人員將圖像分成補丁,并通過Mask獲取一小部分圖片序列,按照MAE的方法進行。
- LoRA fine-tuning
同時使用LoRA技術來加速微調。對于具有權重矩陣W0∈Rd×k的模態(tài)編碼器,在學習新的權重矩陣BA時,保持權重矩陣W0不變。
- Modality extending
將LanguageBind方法擴展到多個(N個)模態(tài)的第一步是將數據處理成令牌序列。隨后,參數將從OpenCLIP進行初始化。然后通過令牌屏蔽和LoRA微調來訓練不同模態(tài)的編碼器,同時保持語言編碼器凍結。最后,將該模態(tài)與語言特征空間對齊。
再來看看語言編碼器以及多模態(tài)聯(lián)合學習部分。
對于語言編碼器,研究人員使用了一個12層的transformer模型,維度為768,初始化來源于OpenCLIP。
對于給定的文本,他們首先使用BPE分詞器將單詞分割成相對常見的子詞。每個子詞對應一個唯一的標記,這些標記在一個詞嵌入層內嵌入。最終,這些標記被語言編碼器編碼,以獲得文本對數:

其中L表示序列的長度。為了確保跨不同模態(tài)的對齊,研究人員采用了對比學習原則。
這種方法的目標是增加配對數據的相似性,將它們帶到相同的語義空間,同時減小不配對數據的相似性。研究人員利用對比學習將各個模態(tài)與語言綁定在一起。
構建高質量數據集
此外,研究人員還創(chuàng)建了一個名為“VIDAL-10M”的高質量數據集,其中包含1000萬個具有對齊視頻-語言、紅外-語言、深度-語言、音頻-語言的數據對,是第一個具有深度和紅外模態(tài)的大規(guī)模視頻多模態(tài)數據集。

數據集構建方法如下:

△VIDAL-10M 構建框架
第一步是生成搜索詞數據庫,這個過程中,研究人員設計了一種獨特的搜索詞獲取策略,利用來自各種視覺任務數據集的文本數據,包括標簽和標題,以構建具有豐富視覺概念和多樣性的視頻數據集。
第二步是從互聯(lián)網收集相關視頻和音頻,并進行一系列過濾處理,以確保數據集的質量和準確性。
這個過程中,研究人員使用了多種過濾方法,包括基于文本的過濾、基于視覺與音頻的過濾,以確保數據集中的視頻和音頻與搜索詞相關且質量高。
第三步是進行紅外和深度模態(tài)生成,以及多視角文本生成和增強。
在空間信息增強方面,研究人員采用了OFA模型生成多個關鍵幀描述,以提升視頻內容的空間表達質量。
同時,在時間信息增強方面,將視頻內容、標題以及Hashtag標簽輸入到mPLUG-owl模型中,以獲取更為精煉和豐富的時間維度描述。
最后,研究人員運用ChatGPT模型對文本描述進行進一步細化和增強。
綜合而言,多視角文本增強涵蓋了標題、標簽、關鍵幀描述以及視頻描述等多個組成部分,為視頻內容提供了全面且詳盡的描述。
多個測試拿下SOTA
在測試階段,大量的實驗驗證了VIDAL-10M數據集和LanguageBind方法的有效性,在視頻、音頻以及其它模態(tài)理解任務中取得了顯著的性能。

LanguageBind在四個數據集上都性能拿下SOTA。
在MSR-VTT上比InterVideo方法高出1.9%,在MSVD上比 InterVideo高出 8.8%,在DiDeMo上比InterVideo高出 6.3%,在ActivityNet上比InterVideo高出 4.4%。
值得注意的是,InterVideo采用了更廣泛的訓練數據,正表明LanguageBind的有效性。
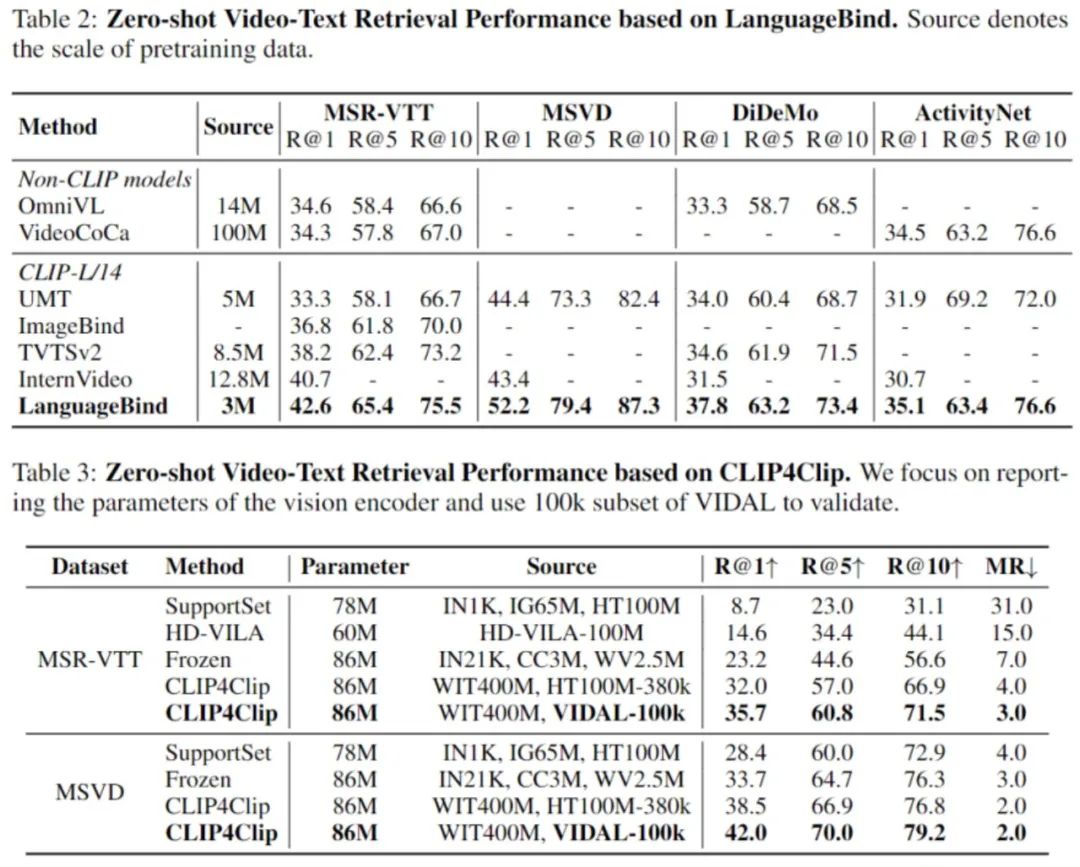
△Zero-Shot視頻-文本檢索結果
視頻-語言、紅外-語言、深度-語言和音頻-語言Zero-Shot分類,在所有數據集上的準確率均優(yōu)于ImageBind、OpenCLIP:

Zero-Shot音頻-語言檢索性能同樣優(yōu)越:

論文鏈接:https://arxiv.org/pdf/2310.01852.pdf