World Model立大功的背后還有哪些改進方向?深度解析!
筆者的個人思考
- 為什么不直接用DINO, 而是用2D-UNet先做了一次蒸餾, 直接用DINO會有什么問題呢?
- 中間world model部分是transformer based的, 能否直接復用現有的LLM+adapter的方式;
- 這種方法理論上能否開車, 文章里只有一個video decoder輸出video,文章中說現在還沒有實時運行, 但是如果不考慮實時性, 加一個action decoder來輸出自車動作,理論上應該能夠開車,但這樣自回歸的輸出也應該有action部分;
- world model部分編碼的是2d的信息, 如果把3d的信息也加上是不是會更通用一些;
- 看文章發現是有好幾個訓練步驟的, 比如先訓練 Image Tokenizer, 再訓練World Model, 最后再訓練Video Decoder部分,整個過程不能夠端到端的一起訓練么, 應該是可以的, 估計訓起來比較費勁,可能不收斂。
- 假設輸入不止有前視, 還有左前和右前, 如何做到不同相機視角下生成的視頻具有一致性。
出發點是什么
自動駕駛有望給交通帶來革命性的改善,但是 構建能夠安全地應對非結構化復雜性的現實世界的場景的系統 仍然充滿挑戰。一個關鍵問題在于有效地 預測各種可能出現的潛在情況以及 車輛隨著周圍世界的演化而采取的動作。為了應對這一挑戰,作者引入了 GAIA-1, 一個生成式的世界模型,它能夠同時輸入視頻、文本和動作來生成 真實的駕駛場景,并且同時能夠提供對自車行為和場景特征的細粒度控制。該方法將世界建模視為序列建模問題,通過把輸入轉化為離散的tokens, 預測序列中的下一個token。該模型有很多新興特性, 包括學習高級結構和場景動態、情境意識、 概括和理解幾何信息。GAIA-1 學習到的表征的強大能力可以捕獲對未來事件的期望,再加上生成真實樣本的能力,為自動駕駛領域的創新提供了新的可能性。
GAIA_1簡介
預測未來事件對自動駕駛系統來說基本且重要。精準地預測未來使自動駕駛車輛能夠預測和規劃其動作,從而增強安全性和效率。為了實現這一目標,開發一個強大的世界模型勢在必行。已經有工作在這方面做了很大努力, 比如. 然而,當前的方法有很大的局限性。世界模型已成功 應用于仿真環境下的控制任務和現實世界的機器人任務。這些方法一方面需要大規模的標注數據, 另一方面模型 對仿真數據的研究無法完全捕捉現實場景的復雜性。此外, 由于其低維表示,這些模型難以生成高度真實的 未來事件的樣例, 而這些能力對于真實世界中的自動駕駛任務來說非常重要。
與此同時,圖像生成和視頻生成領域也取得了重大進步,主要是利用自監督學習從大量現實世界數據中學習生成非常真實的數據 視頻樣本。然而,這一領域仍然存在一個重大挑戰:學習捕獲預期未來事件的表示。雖然這樣的生成模型 擅長生成視覺上令人信服的內容,但在學習動態世界的演化表示方面效果不太好,而這對于準確的預測未來和穩健的決策至關重要。
這項工作提出了 GAIA-1,它同時保持了世界模型和視頻生成的優勢. 它結合了視頻生成的可擴展性和現實性以及世界模型的學習世界演變的能力。
GAIA-1 的工作原理如下。首先,模型分為兩部分:世界模型和video diffusion decoder。世界模型負責理解場景中的high-level的部分及場景的動態演化信息, 而video diffusion decoder 則負責 將潛在表征轉化回具有真實細節的高質量視頻。
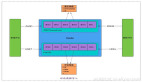
整個網絡結構如下

對于世界模型,使用視頻幀的矢量化表示來離散化每一幀 ,將它們轉換為token序列。基于此就把預測未來轉化為預測序列中的下一個token。這種方法已被廣泛應用于訓練LLM,并且得到了認可, 這種方法主要是通過擴展模型大小和數據來有效提高模型性能。它可以通過自回歸的方式在世界模型的latent space內生成樣本。
第二個部分是一個多任務video diffusion decoder,它能夠執行高分辨率視頻渲染以及時間上采樣, 根據world model自回歸產生的信息生成平滑的視頻。類似于LLM,video diffusion model表明訓練規模(模型大小和數據量)和整體表現之間存在明顯的相關性,這使得 GAIA-1 的兩個組件都適合有效的Scaling。
GAIA-1 是一個多模態的模型,允許使用視頻、文本和動作作為提示來生成多樣化且真實的駕駛場景,如下圖 1 所示:

通過在大量真實的城市駕駛數據上訓練, GAIA-1 學習了理解和區分一些重要概念,例如靜態和動態元素,包括汽車、公共汽車、行人、騎自行車的人、道路布局、建筑物,甚至交通燈。此外,它還可以通過輸入動作或者文本提示來細粒度地控制自車行為及場景特征。
GAIA-1展示了體現現實世界生成規則的能力。還有諸如學習高級結構、概括、創造力和情境意識等新興的特性。這些表明該模型能夠理解并再現世界的規則和行為。而且,GAIA-1 展示了對 3D 幾何的理解,例如,通過有效地捕捉 由減速帶等道路不平整引起的俯仰和側傾間的相互作用。預測的視頻也展示了其他智能體的行為, 這表明模型有能力理解道路使用者的決策。令人驚訝的是,它還能夠產生訓練集之外的數據的能力。例如,在道路邊界之外行駛。
GAIA-1 學習到的表征預測未來事件的能力,以及對自車行為和場景元素兩者的控制是一項令人興奮的進步,一方面為進一步提升智能化效果鋪平了道路, 另一方面也可以為加速訓練和驗證提供合成的數據。世界 像GAIA-1 之類的世界模型是預測接下來可能發生的事情的能力的基礎,這對于自動駕駛的決策至關重要。
GAIA_1的模型設計
GAIA-1 可訓練組件的模型架構。總體架構如上面圖2所示。
編碼視頻、文本和動作
GAIA-1 可以輸入三種不同的模式的內容(視頻、文本、動作),這些輸入信息被編碼到共享的 d 維空間,這個空間是world model的輸入空間, 注意不是輸出空間, world model的輸出空間的維度和下面的 的維度是一樣的。
Image tokens
視頻中的每楨圖像都可以表示為離散tokens。比如可以使用一個pre-trained image tokenizer,這個模型記為. 輸入 T楨圖像序列 ,通過 將其離散化為 n = 576 個離散tokens, 即,其中每個 ,這里的 和圖像離散化的方式有關系, 對應于 , H和W表示輸入圖像的高度和寬度,而D表示下采樣因子。然后通過 一個 embedding layer 將映射到為 維空間中。
Text tokens
在每個時間 t,文本輸入使用 pre-trained 的 T5-large 模型進行編碼,得到每個 個文本tokens。再通過一個線性層同樣映射到 維空間, 產生文本的表示。
action tokens
對于動作, 這里考慮 標量值(表示速度和曲率), 這里的曲率指的應該是方向盤的轉角, 即 steering的意思。和之前類似, 每個scalar也通過線性層分別映射到 維空間,得到動作表示,
對于時間t,輸入tokens按:文本 - 圖像 - 動作 的順序進行交錯排列。因此,世界模型的最終輸入是 。對于位置編碼, 這里采用了, 個可學習的 temporal embedding, 以及 個 spatial embeddings, embeddings 的維度都是 。
Image Tokenizer
即上面提到的 。當使用序列模型對離散輸入數據進行建模時,需要權衡序列長度和詞匯量。序列長度是指離散tokens的數量, 詞匯量大小代表每個token有多少種可能性。對于語言有兩種明顯的選擇:字符和 單詞。當使用字符級標記時,輸入數據具有較長的序列長度,并且單個token所含詞匯表較少,但傳達的含義很少。使用單詞級的 token時,輸入數據的序列長度較短,每個token包含很多語義,但是 詞匯量非常大。大多數語言模型 使用字節對編碼 (或等效)作為字符級和單詞級標記化之間的權衡。
對于視頻,我們希望減少輸入的序列長度,同時可能使 詞匯量更大,但同時希望tokens 比原始像素在語義上更有意義。這里是用離散圖像自動編碼器來做的。在此過程中實現兩個目標,
- 壓縮原始像素的信息,使序列建模問題易于處理。因為圖像包含大量冗余和噪聲信息。我們希望減少 描述輸入數據所需的序列長度。
- 引導壓縮后的信息具有有意義的表示, 比如語義信息, 而不是大量沒有用的信號, 這些信號會降慢世界模型的學習過程。
目標1的實現
下采樣因子用 。每個大小為 的圖像 由描述, 詞匯量大小為 。
目標2的實現
本文用預訓練的DINO 模型 抽取的特征來作為回歸的target, 相當于是用DINO作為蒸餾的teacher,DINO是一個自監督的模型,它包含有豐富的語義信息, 如圖3所示 DINO-distilled 得到的tokens看起來語義信息比較豐富.

蒸餾的student即離散的 autoencoder部分用的是全卷積的2D U-Net. 編碼器通過在可學習嵌入表中查找最近鄰對圖像feature進行量化,產生圖像tokens 。離散編碼器 最終 GAIA-1 模型的一部分, 需要訓練, 而Decoder是僅用來訓練 的。需要注意的是Decoder是基于單楨圖像進行訓練的, 因此它不具有時間一致性, 出于這個原因, 也會訓練一個video decoder, 這部分在后面介紹.
Image autoencoder的訓練loss如下:
- 圖像重建損失。圖像重建損失有兩部分, 分別是 感知損失 和 GAN 損失 。
- 量化損失。為了更新嵌入向量,我們使用嵌入損失和 文獻中的commitment loss, 并且對 embedding 做了 linear projection 以及 l2 normalization, 實驗表明這些有助于增加詞匯量的使用。
- Inductive bias loss。autoencoder量化的圖像特征與DINO提取的圖像特征用cosine similarity loss 度量來監督, 這種方法在特征監督中常用.
世界模型
世界模型的輸入是序列 ,是transformer based自回歸網絡結構。訓練的目標是基于過去的所有tokens(圖像, 文本, 動作)預測接下來的 image token.
loss 函數為
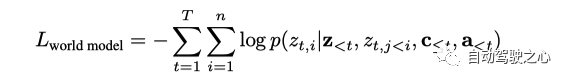
為了在推理的時候, 能夠同時輸入文本或動作作為提示, 在訓練的時候會隨機把輸入的文本或者動作tokens給dropout掉.
為了進一步減少世界模型輸入的序列長度,對輸入的視頻作了進一步采樣, 從原來的25HZ變為6.25HZ。這能讓世界模型能夠在更長的時間內進行推理。為了以全幀速率恢復視頻預測,在video decoder部分用了temporal super-resolution。
視頻解碼器
隨著圖像生成和視頻生成的最新進展,在GAIA-1的decoder部分, 使用了 denoising video diffusion models。一個自然的想法是把每一楨的 frame tokens 解碼到像素空間, 但是這樣得到的不同楨對應的pixel, 在時間上不具有一致性。這里的處理方法是, 把問題建模為 在擴散過程中對一系列幀進行去噪,模型可以訪問到整個時間段內的信息,這樣做明顯提高了輸出視頻的時間一致性。
這里用的是3D U-Net網絡結構, 它里面包括分解空間層和時間注意力層。這里要注意訓練和推理時的輸入不一樣, 訓練時的輸入是 用 pre-trained image tokenizer 得到的image tokens; 推理的時候因為沒有觀測, 輸入的是由 World Model 預測的 image tokens.
我們在圖像和視頻生成任務上聯合訓練單個模型。用視頻訓練 會讓解碼器學習在時間上保持一致,用圖像訓練對于單楨圖像質量至關重要,因為它學習的是從從圖像tokens中提取信息。要注意在圖像訓練時沒有用時間層。
為了訓練視頻擴散解碼器執行多個推理任務,可以通過masking 掉某些frames 或者是 某些 image tokens。這里針對所有的任務, 訓練了單個視頻擴散模型, 任務包括圖像生成、視頻生成、 自回歸解碼和視頻插值, 每個任務均等采樣。例如, 在自回歸生成任務中,用之前生成的過去幀作為輸入 用要預測的幀的圖像tokens作為target。自回歸的任務中包含正向和反向, 有關每個任務的示例,請參見下圖 4。

并且在訓練的時候以概率 p = 0.15 隨機mask掉輸入的image token, 以擺脫對于觀測image token的依賴進而提升泛化能力和時間一致性。
video decoder是根據 noise prediction objective 進行訓練。更具體地說,采用v-parameterization的方法,因為它避免了不自然的 color shifts 并保持 長期一致性。
loss 函數為

訓練數據
訓練數據集包含在倫敦收集的 4,700 小時、25Hz 的駕駛數據,數據集中的時間跨度為2019 年至 2023 年。大約 4.2 億張圖像。不同經緯度及不同天氣下的數據比例分布如下

訓練過程
Image Tokenizer
參數量有0.3B, 輸入圖像的大小為 , 下采樣因子 , 因此每個圖像被encoded成為 個tokens, 詞匯量size為 。離散自動編碼器使用 AdamW進行優化,模型用32個80G的A100訓練 4 天,總計20w steps, batch-size 大小為160.
世界模型
世界模型參數量為6.5B , 在長度為 T = 26、頻率為 6.25 Hz 的視頻序列上進行訓練,對應4秒長的視頻。文本被編碼為 m = 32 個文本tokens,并且 動作為 tokens。因此,世界模型的總序列長度為

訓練樣本有三種:只用圖像, 用圖像及action, 用圖像及文本數據. 該模型用64個80G的A100要訓練15天, 總計10w steps, batch-size為128。這里使用了 FlashAttention v2 實現 transformer模塊,因為它在內存利用率和 推理速度上面有很大提升。為了優化分布式訓練,使用了 Deepspeed ZeRO-2 訓練策略。
Video Decoder
視頻解碼器的參數量有2.6B, 在 長度T ′ = 7 , 分辨率為 的圖像序列上進行訓練, 但是采樣頻率有三種: 6.25 Hz、12.5 Hz 或 25 Hz 。各個訓練任務(上面的圖4)以等概率進行采樣。該模型用32個80G的A100訓練了 15, 總計30w steps , batch-size大小為 64。訓練策略也是 Deepspeed ZeRO-2。
模型推理
World Model
采樣
世界模型基于之前的圖像token, 文本token和 動作 token 自回歸預測下一個圖像token。因為一個圖像中有 個token, 所以要預測一個新的image frame, 需要n個forward, 在每一步中,必須從預測的 logits 中采樣一個 token 以選擇下一個 預測的token。選token的方法有多種, 這里觀察到如果用argmax的話會生成陷入重復循環的 future,類似于語言模型 [44]。但是,如果簡單地從 logits 中采樣,則所選token可能來自不可靠的尾部概率分布(即分數低的那些),這會使模型脫離分布。如下圖6所示
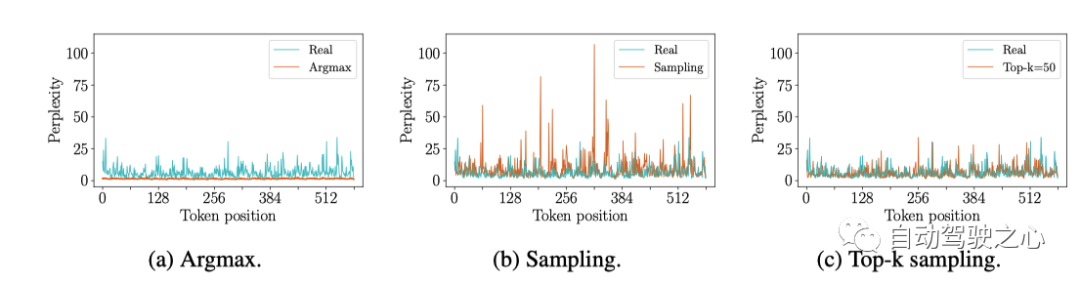
為了多樣性和真實性,這里采用的是 top-k 采樣來采樣下一個圖像token。最終得到的世界模型可以在給定起始背景下,也可以不需要任何上文從頭推理出可能的未來。
對于長視頻生成,如果視頻的長度 超過世界模型的上下文長度,可以采用滑動窗口的方式。
Text-conditioning
可以用文本來提示并指導視頻預測。訓練時,可以將在線的旁白描述或者是離線的文本和視頻一起輸入。由于這些文本源有noise,為了提高生成的futures與文本prompt之間的對齊效果,在推理時采用classifier-free guidance的方式.Classifier-free guidance 的效果是通過減少可能的多樣性來增強文本圖像對齊效果 。更準確地說,對于每個要預測的下一個token,
同時計算有文本作為prompt時的logits, 和無文本作為prompt時的logits, 然后用系數 來控制兩個logits占的比例, 如下公式

通過將無提示的 logits 替換為以另一個文本提示得到的 logits,可以 進行Negative提示。并且把negative prompt 與 positive prompt 推遠, 可以使得future tokens 更多地包括 positive prompt features.
用于 guidance 的scale 系數非常重要, 如下圖, 文本prompt是 "場景中包含一量紅色的公交車",

可以看到, SCALE=1的時候, 就沒有紅色的公并車, SCALE=20的時候,恰好有一輛, SCALE=20的時候, 不止有一輛紅色公交車, 而且還有一輛白色公交車.
Video Decoder
為了解碼從世界模型生成的token序列,具體的方法如下:
- 以對應的 T' image tokens,解碼前 T ′ = 7 幀;如下圖所示

- 使用過去的 2 個重疊幀作為圖像context, 以及接下來的T ′ -2 圖像tokens自回歸解碼接下來的 T ′ -2 幀。如下圖所示

- 重復自回歸過程,直到以 6.25 Hz 生成 N 幀。
- 將 N 幀從 6.25 Hz 做Temporally上采樣得到 12.5 Hz
- 將 2N- 1 幀從 12.5 Hz Temporally上采樣到 25.0 Hz
在自回歸decoding過程中, 需要同時考慮生成的圖片質量以及時間一致性, 因此這里做了一個加權,
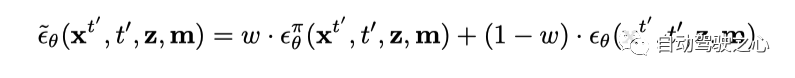
其中等式右邊第一項將每個幀分別作為圖像進行去噪, 等式右邊第二項將幀序列聯合降噪為視頻。在實際應用中,只需打開或者關閉時間層。這里對每個diffusion step 用的概率用這個加權平均, 并且采取的.
在探索視頻解碼的不同推理方法時,發現解碼視頻 從序列末尾開始自回歸地向后會導致更穩定的物體, 并且地面上的閃爍也更少。因此在整個視頻解碼方法中,先解碼最后的 T ′ 幀, 之后從后往前解碼剩余的楨。
Scaling
GAIA-1 中世界建模任務的方法經常在大型語言模型(LLM)中使用, 類似于GPT。在這兩種情況下,任務都被簡化為預測下一個token。盡管GAIA-1中的世界模型建模的任務和LLM中的任務不同, 但是與LLM中類似, Scaling laws同樣對于GAIA-1適用.這說明Scaling laws對于很多領域都是適用的, 包括自動駕駛。
為了探索 GAIA-1 的Scaling Laws,我們使用以下方法預測了世界模型的最終性能 使用小于 20 倍計算量訓練的模型。對比的標準是看cross-entropy, 并且采用下面的函數來擬合 數據點。在圖8a中,可以看到GAIA-1的最終交叉熵預測精度很高。
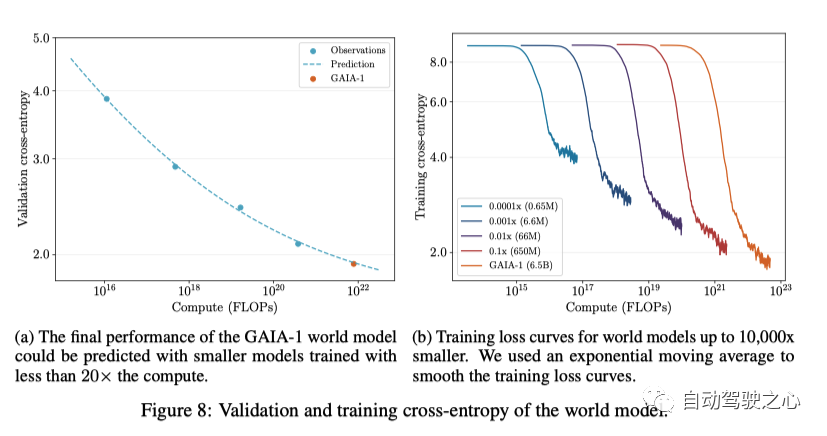
如圖 8b 所示, 可以看出, 隨著模型變大, 訓練時候的cross-entropy 會收斂地越來越低,上面說明可以通過擴展數據和計算資源來進一步提升模型的性能。
Capabilities and Emerging Properties (能力和新興特性)
這一節主要是效果展示的例子。這里有個youtube的連接: https://www.youtube.com/playlist?list=PL5ksjZd5b6SI-6MQi6ghoD-GilTPmsQIf
下面圖9顯示了GAIA-1可以生成各種場景。

下面是GAIA-1通過一些新興特性展示了對世界的生成規則的一定程度的理解和總結:
- 學習高級結構和場景動態:它生成與連貫的場景 并且物體放置在合理的位置上, 并展示真實的物體之間的交互,例如交通 燈光、道路規則、讓路等。這表明該模型不僅僅是記憶 統計模式,而是理解了我們生活的世界中關于物體的底層規則, 比如物體是如何擺放, 有何行為。
- 泛化性和創造性:可以生成不在訓練集里的新穎多樣的視頻 。它可以產生物體、動作的獨特組合, 以及訓練數據中未明確出現的場景,這表現出它有顯著的泛化能力,并且表現出了一定程度的概括性和創造性, 這表明GAIA-1對視頻序列的生成規則有較好的理解.
- 情境感知:GAIA-1 可以捕獲情境信息并生成視頻 來體現這種理解。例如,它可以基于初始條件或提供的上下文 產生連貫的動作和響應。此外,GAIA-1 還展示了對 3D 幾何的理解,有效捕獲到由于道路不平整(例如減速帶)引起的側傾。這種情境意識表明這些模型不僅能常握訓練集中數據的統計規律,而且還積極地處理和總結給定的信息以生成適當的視頻序列。
長時間駕駛場景的生成
GAIA-1 可以完全憑想象生成穩定的長視頻, 如下圖所示表現了40s的生成數據:

這主要是該模型利用其學習到的世界隱式先驗分布來生成完全 想象的真實駕駛場景。這里應該采用了類似于MILE里的先驗分布做法。生成的駕駛場景中具有復雜的道路布局、建筑物、汽車、行人等。這證明 GAIA-1 理解了支撐我們所居住的世界的規則及其結構和動力學。
多個合理未來的生成
GAIA-1 能夠根據單個初始提示生成各種不同的未來場景。當以簡短的視頻作為輸入時, 它可以通過不斷地sampling產生大量合理且多樣化的內容。GAIA-1 針對視頻提示能夠準確模擬多種潛在的未來場景,同時與在初始視頻中觀察到的條件保持一致。
如下圖所示, 世界模型可以推理 (i) 道路使用者(例如讓路或不讓路)

上面兩個分別對應著, 他車不讓路, 和他車讓路的情況。(ii)多種自車行為(例如直行或右轉)

(iii) 多種動態場景(例如可變的交通密度和類型)

自車行為和駕駛場景的細粒度控制
GAIA-1可以僅根據文字提示生成視頻,完全想象場景。我們展示了如何根據文本提示模型生成駕駛場景, 如下所示展示的是對天氣和光照的細粒度控制.


下面是個令人信服的示例,其中模型展示了對車輛的細粒度控制。通過利用此控制,我們可以提示模型生成視頻描述訓練數據范圍之外的場景。這表明 GAIA-1 能夠將自車的動態與周圍環境分開并有效地應用于 不熟悉的場景。這表明它能夠來推理我們的行為對世界的影響,它可以更豐富地理解動態場景,解鎖 基于模型的Policy learning(在world model中做planning),它可以實現閉環仿真探索(通過將世界模型視為模擬器)。為了展示這一點,這里展示了 GAIA-1 生成 未來,自車向左或向右轉向,偏離車道等場景, 如下圖所示:

GAIA-1 在訓練數據集中從未見過這些不正確的行為,這表明 它可以推斷出之前在訓練數據中未見過的駕駛概念。我們也看到了現實 其他智能體對自車受控行為的反應。最后,這個例子展示了 GAIA-1 利用文本和動作來充分想象 駕駛場景。在這種特殊情況下,我們提示模型自車要超車公交車。

GAIA_1的總結和未來方向
GAIA-1 是自動駕駛領域的生成式世界模型。世界模型使用矢量量化 將未來預測任務轉變為下一個token的預測任務,該技術 已成功應用于大型語言模型。GAIA-1 已展示其具有 全面了解環境,區分各種概念 例如汽車、卡車、公共汽車、行人、騎自行車的人、道路布局、建筑物和交通燈的能力, 這些全是通過自監督的方式學到的。此外,GAIA-1 利用視頻擴散模型的功能 生成真實的駕駛場景,從而可以作為先進的模擬器使用。GAIA-1 是 一種多模態的方法,通過文本和動作指令相結合可以控制自車的動作和其他場景屬性。雖然該方法展示了有潛力的結果,有可能突破自動駕駛的界限,但是重要的是也要承認當前的局限性。例如,自回歸的生成過程雖然非常有效,但尚未實時運行。盡管如此,這個過程非常適合并行化,允許并發生成多個樣本。GAIA-1 的重要性超出了其生成能力。世界模型代表了向 實現能夠理解、預測和適應復雜環境的自動駕駛系統邁出的關鍵一步。此外,通過將世界模型融入駕駛模型中, 我們可以讓他們更好地理解自車的決策,并最終推廣到更多 現實世界的情況。最后,GAIA-1 還可以作為一個有價值的模擬器,允許 生成無限數據,包括corner-case和反例,用于訓練和驗證自動駕駛系統。
文章鏈接: https://browse.arxiv.org/pdf/2309.17080.pdf
官方博客1: https://wayve.ai/thinking/introducing-gaia1/
官方博客2: https://wayve.ai/thinking/scaling-gaia-1/

原文鏈接:https://mp.weixin.qq.com/s/dPfqukDLUvhrfZ0a0b6X6A