













試過GPT-4V后,微軟寫了個166頁的測評報告,業內人士:高級用戶必讀
一周之前,ChatGPT迎來重大更新,不管是 GPT-4 還是 GPT-3.5 模型,都可以基于圖像進行分析和對話。與之對應的,多模態版GPT-4V模型相關文檔也一并放出。當時 OpenAI 放出的文檔只有18頁,很多內容都無從得知,對于想要更深入了解GPT-4V應用的人來說,難度還是相當大的。
短短幾天時間,當大家還在死磕OpenAI 放出的18頁文檔時,微軟就公布了一份長達166頁的報告,定性地探討了GPT-4V的功能和使用情況。

報告地址:https://arxiv.org/pdf/2309.17421.pdf
MedARC(醫療人工智能研究中心)聯合創始人兼CEO Tanishq Mathew Abraham表示,「這篇報告將是GPT-4V高級用戶的必讀之作。」

該報告共分為11個章節,重點是對最新模型 GPT-4V(ision)進行分析,以加深大眾對 LMM(大型多模態模型) 的理解。文章用很大篇幅介紹了GPT-4V可以執行的任務,包括用測試樣本來探索GPT-4V的質量和通用性,現階段GPT-4V能夠支持的輸入和工作模式,以及提示模型的有效方法。
在探索 GPT-4V 的過程中,該研究還精心策劃組織了涵蓋各個領域和任務的一系列定性樣本。對這些樣本的觀察表明,GPT-4V 在處理任意交錯的多模態輸入方面具有前所未有的能力,并且其功能的通用性使 GPT-4V 成為強大的多模態通用系統。
此外,GPT-4V 對圖像獨特的理解能力可以催生新的人機交互方法,例如視覺參考提示(visual referring prompting)。報告最后深入討論了基于 GPT-4V 的系統的新興應用場景和未來研究方向。該研究希望這一初步探索能夠激發未來對下一代多模態任務制定的研究,開發和增強 LMM 解決現實問題的新方法,并更好地理解多模態基礎模型。
下面我們逐一介紹每個章節的具體內容。
論文概覽
論文第一章介紹了整個研究的基本情況。作者表示,他們對GPT-V4的探討主要在以下幾個問題的指導下進行:
1、GPT-4V 支持哪些輸入和工作模式?多模態模型的通用性必然要求系統能夠處理不同輸入模態的任意組合。GPT-4V 在理解和處理任意混合的輸入圖像、子圖像、文本、場景文本和視覺指針方面表現出了前所未有的能力。他們還證明,GPT-4V 能夠很好地支持在 LLM 中觀察到的test-time技術,包括指令跟隨、思維鏈、上下文少樣本學習等。
2、GPT-4V 在不同領域和任務中表現出的質量和通用性如何?為了了解 GPT-4V 的能力,作者對涵蓋廣泛領域和任務的查詢進行了采樣,包括開放世界視覺理解、視覺描述、多模態知識、常識、場景文本理解、文檔推理、編碼、時間推理、抽象推理、情感理解等。GPT-4V 在許多實驗領域都表現出了令人印象深刻的人類水平的能力。
3、使用和提示 GPT-4V 的有效方法是什么?GPT-4V 能夠很好地理解像素空間編輯,例如在輸入圖像上繪制的視覺指針和場景文本。受這種能力的啟發,研究者討論了「視覺參考提示」,它可以直接編輯輸入圖像以指示感興趣的任務。視覺參考提示可與其他圖像和文本提示無縫結合使用,為教學和示例演示提供了一個細致入微的界面。
4、未來的發展方向是什么?鑒于 GPT-4V 在跨領域和跨任務方面的強大能力,我們不禁要問,多模態學習乃至更廣泛的人工智能的下一步是什么?作者將思考和探索分為兩個方面,即需要關注的新出現的應用場景,以及基于 GPT-4V 系統的未來研究方向。他們介紹了他們的初步探索結果,以啟發未來的研究。
GPT-4V的輸入模式
論文第二章總結了GPT-4V支持的輸入,分為純文本、單個圖像-文本對、交錯圖像-文本輸入(如圖1)三種情況。

GPT-4V的工作模式和提示技術
論文第三章總結了GPT-4V的工作模式和提示技術,包括:
1、遵循文字說明:

2、視覺指向和視覺參考提示:


3、視覺+文本提示:

4、上下文少樣本學習:



視覺-語言能力
論文第四章研究了如何利用 GPT-4V 來理解和解釋視覺世界。
首先4.1節探討了GPT-4V對不同域圖像的識別能力,包括識別不同的名人,并能詳細描述名人的職業、行為、背景、事件等信息。

除了識別名人外,GPT-4V能準確識別測試圖像中的地標,還能產生生動而詳細的敘述,從而捕捉地標的特性。

GPT-4V還可以識別各種菜肴,并給出菜肴中的特定成分,裝飾物或烹飪技術。

除此以外,GPT-4V還可以識別常見的疾病,例如其能根據肺部的CT掃描指出潛在的問題,又或者對給定的x光片中的牙齒和頜骨,解釋下頜左下方和右側部分出現的智齒可能需要切除;GPT-4V能正確識別徽標,并提供詳細的描述,包括其設計,顏色,形狀和符號;如果提示中出現的問題與照片不符,GPT-4V也能進行反事實推理。

4.2節探討了GPT-4V對目標的定位、計數和密集字幕生成。
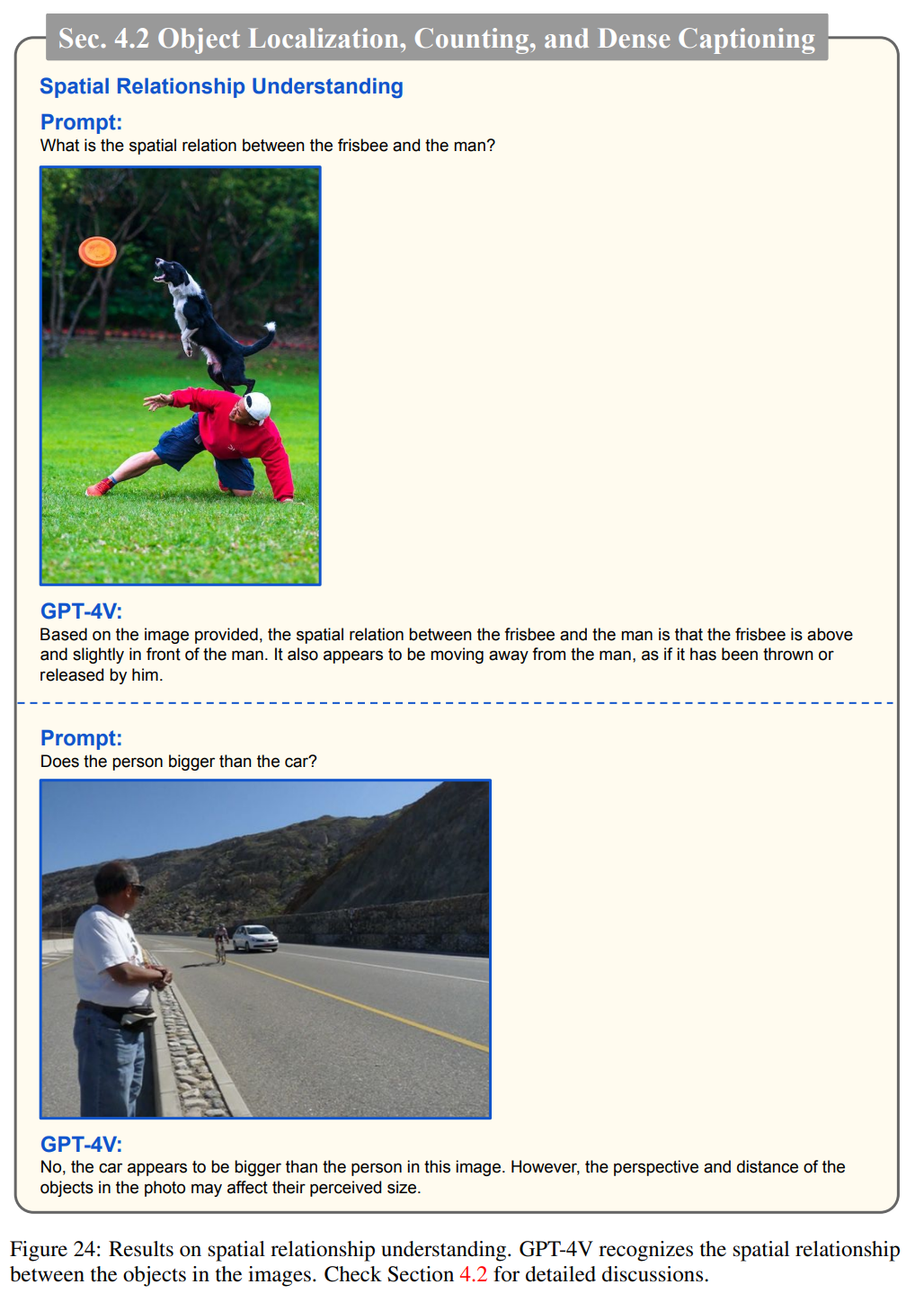
下圖表明GPT-4V能夠理解圖像中人與物體之間的空間關系,例如識別飛盤和人之間的空間關系。
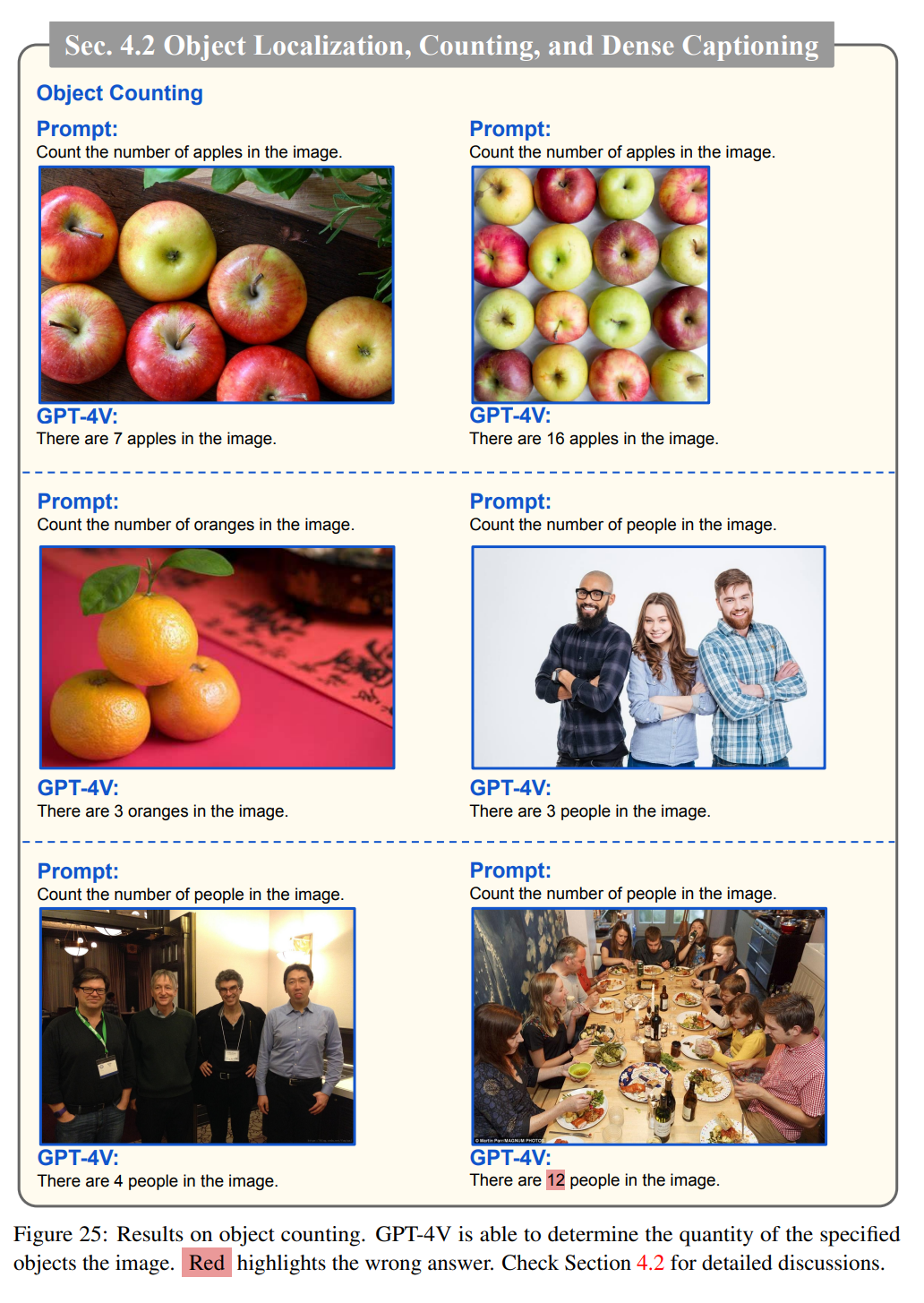
GPT-4V能夠確定圖像中指定物體的數量,下圖表明GPT-4V成功地計算出圖像中出現的物體的數量,如蘋果、橘子和人。
GPT-4V成功地定位和識別圖像中的個體,然后為每個個體提供簡潔的描述。

4.3節介紹了GPT-4V能夠進行多模態理解以及對常識的掌握能力。下圖展示了GPT-4V能夠解釋笑話和梗圖:

GPT-4V能夠回答科學問題:

GPT-4V還能進行多模態常識推理:

4.4節介紹了GPT-4V對場景文本、表格、圖表和文檔的推理能力。
GPT-4V可以進行數學推理:

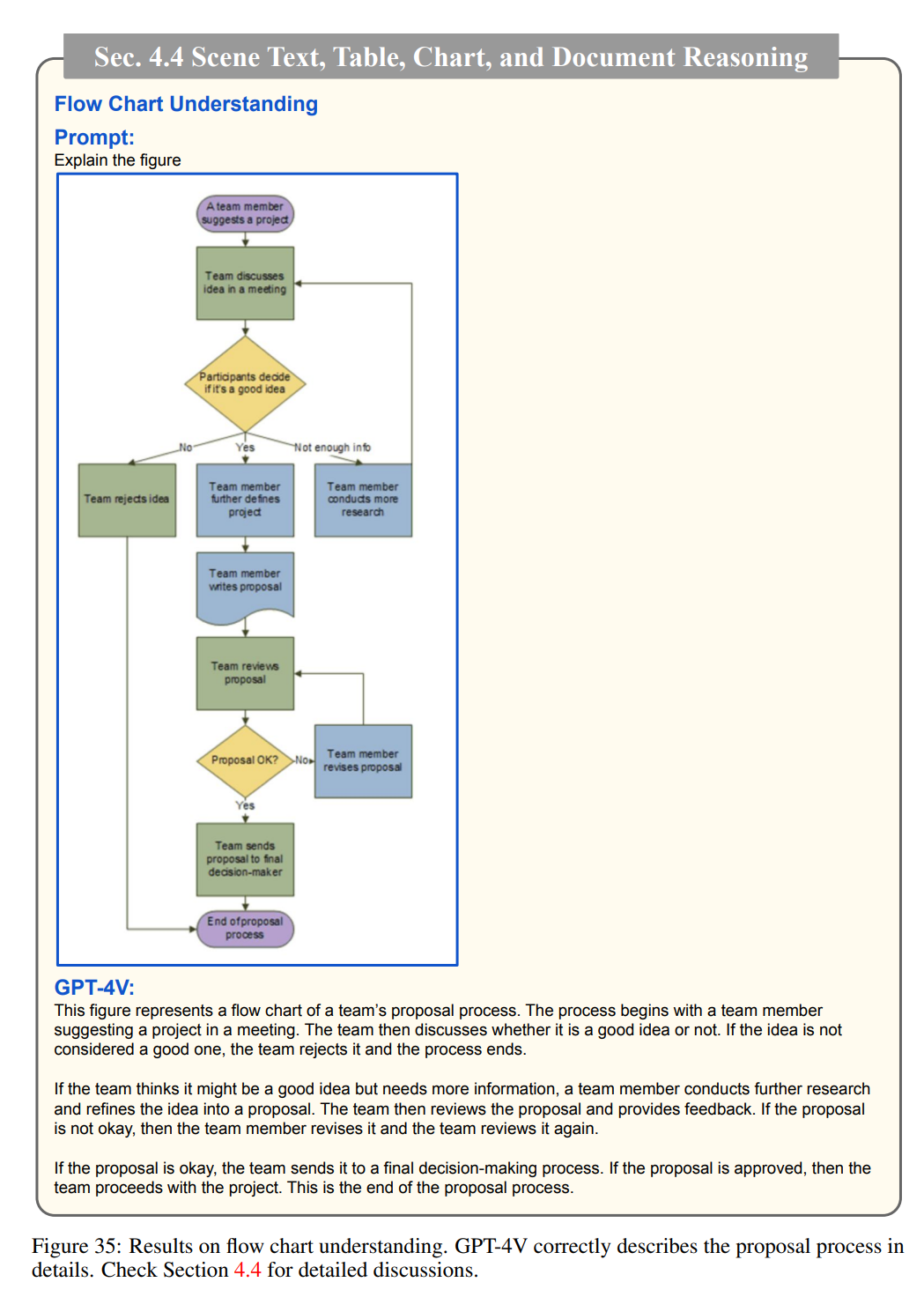
理解流程圖:
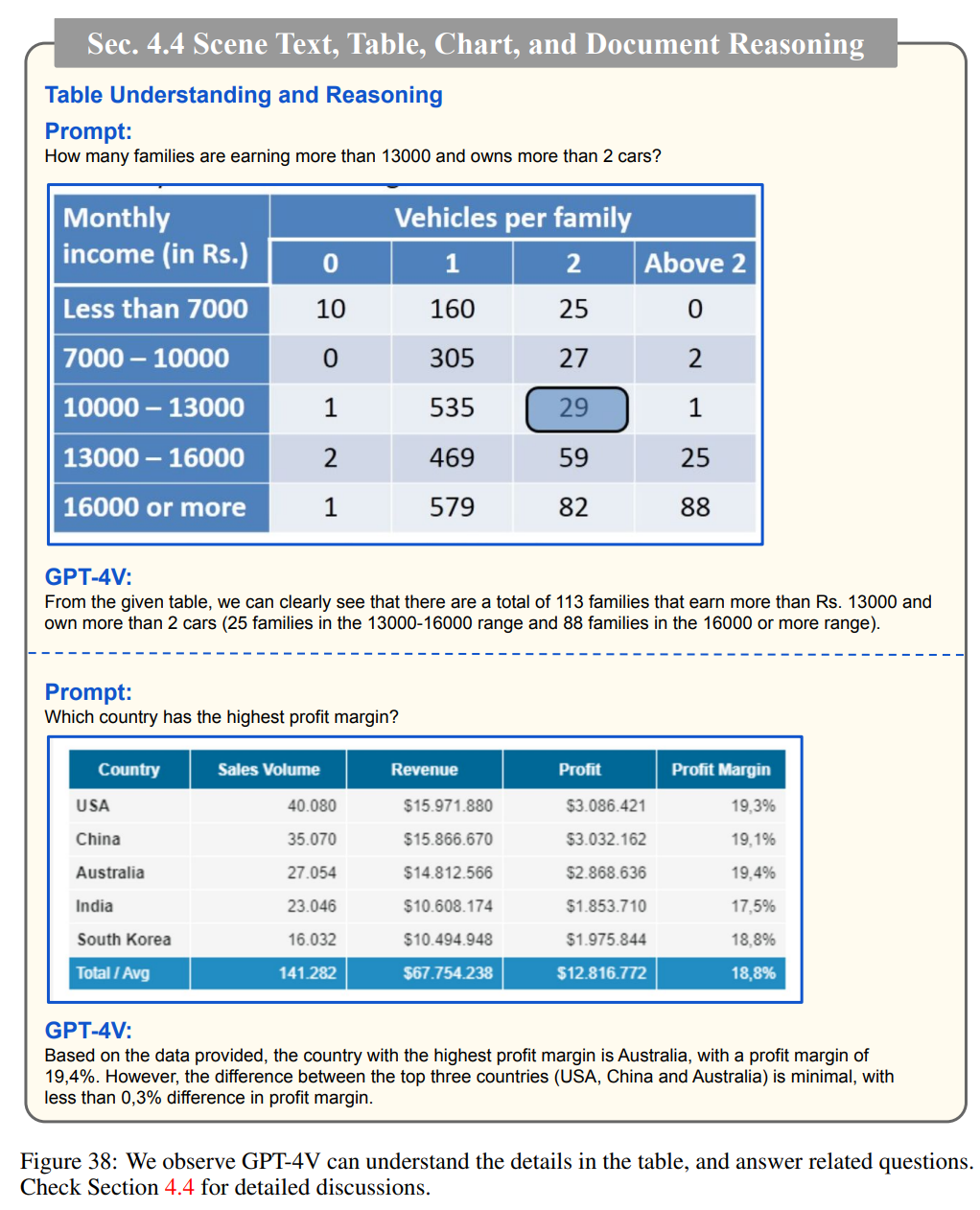
理解表格細節:
GPT-4V還能閱讀一份多頁的技術報告,理解每個部分的內容,并對該技術報告進行總結:

4.5節介紹了GPT-4V對多語言多模態的理解。
GPT-4V能夠生成不同語言的圖像描述:

GPT-4V對多語言文本識別、翻譯和描述的結果:

4.6節介紹了GPT-4V的編碼能力。
基于手寫數學方程生成LaTeX代碼的能力:

GPT-4V生成Markdown/LaTex代碼以重建圖像中表的能力:

GPT-4V編寫代碼以復制輸入圖形的能力:

與人類的互動:視覺參考提示
在與多模態系統的人機交互中,指向特定空間位置是一項基本能力,例如進行基于視覺的對話。第 5.1 節顯示,GPT-4V 可以很好地理解直接畫在圖像上的視覺指針。基于這一觀察結果,研究者提出了一種名為「視覺參考提示(visual referring prompting)」的新型模型交互方法。如圖 50 所示,其核心思想是直接編輯圖像像素空間,繪制視覺指針或場景文本,作為人類的參照指示。作者在第 5.2 節詳細介紹了這種方法的用途和優勢。




最后,他們在第 5.3 節探討了如何讓 GPT-4V 生成視覺指針輸出,以便與人類互動。這些視覺指針對于人類和機器來說都能直觀地生成和理解,是人機交互的良好渠道。

時間和視頻理解
在第六章,作者討論了GPT4V 的時間和視頻理解能力。盡管 GPT4V 主要以圖像作為輸入,但評估其對時間序列和視頻內容的理解能力仍然是對其整體評估的一個重要方面。這是因為現實世界中的事件會隨著時間的推移而展開,而人工智能系統理解這些動態過程的能力在現實世界的應用中至關重要。時序預測、時序排序、時序定位、時序推理和基礎時序理解等能力有助于衡量模型在一系列靜態圖像中理解事件順序、預測未來事件發生和分析隨時間變化的活動的能力。
盡管 GPT-4V 以圖像為中心,但它能夠以類似人類理解的方式理解視頻和時間序列。為了提高像 GPT-4V 這樣復雜的人工智能模型的通用性和適用性,這方面的測試對其發展和完善至關重要。
在這一章的實驗中,研究者使用了多個選定的視頻幀作為輸入,以測試模型在理解時間序列和視頻內容方面的能力。
多圖像序列

視頻理解




基于時間理解的視覺參考提示

視覺推理與智商測試
對抽象視覺刺激和符號的理解和推理是人類智能的一項基本能力。論文第七章測試了GPT-4V是否可以從視覺信號中抽象語義,并可以執行不同類型的人類智商(IQ)測試。
抽象視覺刺激

部件和物體的發現與關聯

韋氏成人智力量表

瑞文推理測驗


情商測驗
在與人類互動時,GPT-4V 必須具備同理心和情商(EQ),以理解和分享人類的情感。受人類情商測試定義的啟發,作者研究了 GPT-4V 在以下方面的能力:從人的面部表情中識別和解讀人的情緒;理解不同的視覺內容如何激發情緒;根據所需的情緒和情感生成適當的文本輸出。
從面部表情中讀出情感

理解視覺內容如何激發情感


情緒條件輸出

新興應用亮點
這一章展示了 GPT-4V 的卓越功能可能帶來的無數高價值應用場景和新用例。誠然,其中一些應用場景可以通過精心策劃用于微調現有視覺和語言(VL)模型的訓練數據來實現,但作者想強調的是,GPT-4V 的真正威力在于它能夠毫不費力地實現開箱即用。此外,他們還介紹了 GPT-4V 如何與外部工具和插件無縫集成,從而進一步拓展其潛力,實現更多創新和協作應用。
找不同


工業





醫藥




汽車保險


編寫照片說明


圖像理解與生成




具身智能體




圖形用戶界面(GUI)交互


基于LLM的智能體
論文第十章討論了 GPT-4V 未來可能的研究方向,重點是 LLM 中的有趣用法如何擴展到多模態場景。
基于ReAct的GPT-4V多模態鏈擴展:

使用自我反思來改進文本到圖像模型SDXL生成的文本提示的示例:

自洽性:

檢索增強LMM,圖74顯示了一個檢索增強的LMM幫助雜貨店結帳的示例。

關于GPT-4V的更多場景應用細節,請查看原論文。





















