













作者 | 崔皓
審校 | 重樓
摘要
本文探討了知識(shí)圖譜與大型語(yǔ)言模型如何聯(lián)手提升行業(yè)應(yīng)用。你將了解知識(shí)圖譜的開發(fā)流程,尤其是實(shí)體識(shí)別、關(guān)系抽取和圖的構(gòu)建三個(gè)關(guān)鍵環(huán)節(jié)。通過(guò)實(shí)戰(zhàn)示例,文章將展示如何利用自然語(yǔ)言處理(NLP)和大型語(yǔ)言模型生成知識(shí)圖譜。此外,文章還將介紹一個(gè)開源的知識(shí)圖譜項(xiàng)目GraphGPT。
開篇
眾所周知,知識(shí)圖譜是一種以圖結(jié)構(gòu)組織和表示信息或知識(shí)的方式。在這樣的結(jié)構(gòu)中,節(jié)點(diǎn)表示實(shí)體(如人、地點(diǎn)、事物等),邊則代表實(shí)體之間的各種關(guān)系。知識(shí)圖譜能夠幫助我們更有效地組織和檢索信息,從而在搜索、推薦系統(tǒng)、自然語(yǔ)言理解和多種應(yīng)用場(chǎng)景中發(fā)揮關(guān)鍵作用。隨著大模型發(fā)展愈來(lái)愈快,利用大模型生成知識(shí)圖譜的方式也悄然興起。本文通過(guò)實(shí)戰(zhàn)的方式帶大家利用大語(yǔ)言模型生成知識(shí)圖譜。
知識(shí)圖譜的應(yīng)用與開發(fā)
知識(shí)圖譜的應(yīng)用
說(shuō)起知識(shí)圖譜可能大家并不陌生,它在各個(gè)領(lǐng)域都發(fā)揮著重要的作用。
1. 醫(yī)療健康
疾病診斷與治療: 通過(guò)分析疾病、癥狀、藥物之間的關(guān)系,知識(shí)圖譜可以幫助醫(yī)生做出更準(zhǔn)確的診斷和治療方案。
藥物研發(fā): 知識(shí)圖譜可以整合各種生物醫(yī)學(xué)信息,加速新藥的研發(fā)過(guò)程。
2. 金融行業(yè)
風(fēng)險(xiǎn)管理與評(píng)估: 知識(shí)圖譜能夠整合個(gè)人或企業(yè)的多維度信息,從而更準(zhǔn)確地評(píng)估貸款或投資的風(fēng)險(xiǎn)。
反欺詐: 通過(guò)分析交易模式和行為,知識(shí)圖譜可以有效地檢測(cè)和預(yù)防欺詐活動(dòng)。
3. 電商和推薦系統(tǒng)
個(gè)性化推薦:知識(shí)圖譜可以根據(jù)用戶行為和偏好,以及商品屬性進(jìn)行更精準(zhǔn)的個(gè)性化推薦。
供應(yīng)鏈優(yōu)化: 通過(guò)分析供應(yīng)鏈中各環(huán)節(jié)的數(shù)據(jù),知識(shí)圖譜可以幫助企業(yè)優(yōu)化存貨管理和物流。
知識(shí)圖譜的開發(fā)
知識(shí)圖譜通過(guò)連接龐大且復(fù)雜的數(shù)據(jù)點(diǎn),為多個(gè)行業(yè)提供了高度相關(guān)和實(shí)用的洞見。這使得它成為現(xiàn)代信息時(shí)代不可或缺的一部分。
知識(shí)圖譜開發(fā)過(guò)程也比較繁瑣,需要經(jīng)過(guò)如下步驟:
數(shù)據(jù)收集: 從各種來(lái)源(如文本、數(shù)據(jù)庫(kù)、網(wǎng)站等)收集原始數(shù)據(jù)。
數(shù)據(jù)清洗: 對(duì)收集的數(shù)據(jù)進(jìn)行預(yù)處理,包括去除噪聲、標(biāo)準(zhǔn)化等。
實(shí)體識(shí)別: 識(shí)別文本中的重要實(shí)體(如名詞或?qū)S忻~)。
關(guān)系抽取: 確定實(shí)體之間的關(guān)系(如“是”、“有”、“屬于”等)。
構(gòu)建圖: 使用識(shí)別出的實(shí)體和關(guān)系構(gòu)建知識(shí)圖譜。
驗(yàn)證與更新: 通過(guò)人工或自動(dòng)方式對(duì)知識(shí)圖譜進(jìn)行驗(yàn)證和動(dòng)態(tài)更新。
三元組
雖然上述過(guò)程的每個(gè)步驟都很重要,但是“實(shí)體識(shí)別”,“關(guān)系抽取”,“構(gòu)建圖”這三個(gè)步驟是整個(gè)開發(fā)過(guò)程的重中之重。我們需要使用三元組的方式完成識(shí)別,抽取和構(gòu)建。
在大語(yǔ)言模型如GPT或BERT出現(xiàn)之前,知識(shí)圖譜主要依賴于規(guī)則匹配、詞性標(biāo)注、依存解析和各類機(jī)器學(xué)習(xí)方法來(lái)抽取三元組(實(shí)體1、關(guān)系、實(shí)體2)。這些傳統(tǒng)方法各有優(yōu)缺點(diǎn),如需大量人工規(guī)則、標(biāo)記數(shù)據(jù)或計(jì)算資源,泛化能力和準(zhǔn)確性也有限。
例如:對(duì)下面三句話進(jìn)行三元組的抽取
1. 小紅是我的同學(xué)。
2. 小紅是小明的鄰居。
3. 小明是我的籃球隊(duì)隊(duì)友。
我可以使用NLP方式對(duì)其進(jìn)行處理,代碼如下:
from snownlp import SnowNLP
# 初始化三元組列表
triplets = []
# 待處理的文本列表
sentences = [
"小紅是我的同學(xué)。",
"小紅是小明的鄰居。",
"小明是我的籃球隊(duì)隊(duì)友。"
]
# 遍歷每個(gè)句子進(jìn)行處理
for sentence in sentences:
# 使用SnowNLP進(jìn)行自然語(yǔ)言處理
s = SnowNLP(sentence)
# 從句子中抽取名詞和動(dòng)詞
words = [word for word, tag in s.tags if tag in ('nr', 'n', 'v')]
# 假設(shè)我們的三元組格式為: (實(shí)體1, 關(guān)系, 實(shí)體2)
# 在這個(gè)簡(jiǎn)單的例子里,我們只取前兩個(gè)名詞作為實(shí)體1和實(shí)體2,動(dòng)詞作為關(guān)系
if len(words) >= 3:
triplets.append((words[0], words[2], words[1]))
# 輸出抽取出來(lái)的三元組
print(triplets)這里對(duì)代碼稍微做一下解釋:
- 先初始化一個(gè)空的triplets列表,用于存放抽取出來(lái)的三元組。
- 然后,定義了一個(gè)sentences列表,包含三個(gè)待處理的句子。
- 使用for循環(huán)遍歷這些句子。
- 使用SnowNLP對(duì)每個(gè)句子進(jìn)行自然語(yǔ)言處理。
- 通過(guò)s.tags獲取詞性標(biāo)注,并抽取出名詞('n')和人名('nr')以及動(dòng)詞('v')。
- 如果一個(gè)句子中包含至少三個(gè)這樣的詞(兩個(gè)實(shí)體和一個(gè)關(guān)系),則形成一個(gè)三元組并添加到triplets列表中。
上述代碼結(jié)果如下:
[('是', '鄰居', '小明'), ('小明', '籃球隊(duì)', '是')]通過(guò)結(jié)果可以看出自然語(yǔ)言處理(NLP)任務(wù)存在的問(wèn)題:
1. 三元組的構(gòu)造不準(zhǔn)確:例如第一個(gè)三元組`('是', '鄰居', '小明')`,其中“是”并不是一個(gè)實(shí)體,而應(yīng)該是一個(gè)關(guān)系。
2. 丟失了一些關(guān)鍵信息:例如第三個(gè)句子"我和小明是籃球隊(duì)的隊(duì)友"并沒(méi)有正確抽取為三元組。
這些問(wèn)題揭示了一般NLP任務(wù)(尤其是基于規(guī)則或淺層NLP工具的任務(wù))存在的一些局限性:
1. 詞性標(biāo)注和句法分析的不準(zhǔn)確性:依賴于詞性標(biāo)注和句法分析工具的準(zhǔn)確性,一旦工具出錯(cuò),后續(xù)的信息抽取也會(huì)受到影響。
2. 缺乏深度語(yǔ)義理解:僅僅通過(guò)詞性標(biāo)注和淺層句法分析,難以準(zhǔn)確地抽取復(fù)雜或模糊的關(guān)系。
3. 泛化能力差:對(duì)于不同類型或結(jié)構(gòu)的句子,可能需要不斷地調(diào)整規(guī)則或模型。
4. 對(duì)上下文信息的利用不足:這種方法通常只考慮單個(gè)句子內(nèi)的信息,而忽視了上下文信息,這在復(fù)雜文本中是非常重要的。
大語(yǔ)言模型如何助力知識(shí)圖譜
大語(yǔ)言模型,如GPT或BERT,是基于深度學(xué)習(xí)的自然語(yǔ)言處理模型,具有出色的文本理解和生成能力。它們能夠理解自然語(yǔ)言,從而使復(fù)雜的查詢和推理變得更加簡(jiǎn)單。相比于傳統(tǒng)方法,大模型有以下幾點(diǎn)優(yōu)勢(shì):
- 文本理解能力:可以準(zhǔn)確地抽取和理解更復(fù)雜、模糊或多義的實(shí)體和關(guān)系。
- 上下文敏感性:大模型能夠理解詞語(yǔ)在不同上下文中的不同含義,這對(duì)于精準(zhǔn)抽取實(shí)體和關(guān)系至關(guān)重要。這種上下文敏感性讓模型能夠理解復(fù)雜和模糊的句子結(jié)構(gòu)。
- 強(qiáng)大的泛化能力:由于在大量多樣化數(shù)據(jù)上進(jìn)行了訓(xùn)練,這些模型能夠很好地泛化到新的、未見過(guò)的數(shù)據(jù)。這意味著即使面對(duì)具有復(fù)雜結(jié)構(gòu)或不常見表達(dá)方式的文本,它們也能準(zhǔn)確地進(jìn)行實(shí)體和關(guān)系抽取。
同樣的例子,我們看看大模型是如何做的。代碼如下:
from snownlp import SnowNLP
# 初始化三元組列表
triplets = []
# 待處理的文本列表
from langchain.llms import OpenAI
llm = OpenAI(model_name="gpt-3.5-turbo")
texts = '''小紅是我的同學(xué)。小紅是小明的鄰居。小明是我的籃球隊(duì)隊(duì)友。'''
#知識(shí)圖譜索引創(chuàng)建
from langchain.indexes import GraphIndexCreator
#知識(shí)圖譜問(wèn)答的chain
from langchain.chains import GraphQAChain
#知識(shí)圖譜三元素的一個(gè)類。 三元素:主 謂 賓。
from langchain.graphs.networkx_graph import KnowledgeTriple
#創(chuàng)建圖譜的索引,解析文本內(nèi)容
index_creator = GraphIndexCreator(llm=llm)
#創(chuàng)建圖譜的索引,顯示對(duì)象之間的關(guān)系
f_index_creator = GraphIndexCreator(llm=llm)
final_graph = f_index_creator.from_text('')
#對(duì)文本進(jìn)行切割
for text in texts.split("."):
#將切割以后的文本生成三元組
triples = index_creator.from_text(text)
for (node1, node2, relation) in triples.get_triples():
#將三元組的信息放到final_graph中用以顯示
final_graph.add_triple(KnowledgeTriple(node1, node2,relation ))
print("=================")
print(node1)
print(relation)
print(node2)上面這段代碼用于構(gòu)建知識(shí)圖譜。它用到了三個(gè)主要的模塊:`OpenAI`、`GraphIndexCreator` 和 `GraphQAChain`,以及一個(gè)輔助類:`KnowledgeTriple`。主要內(nèi)容包括:
- OpenAI 初始化:`llm = OpenAI(model_name="gpt-3.5-turbo")` 。初始化了 `gpt-3.5-turbo` 的大型語(yǔ)言模型(LLM)。
- 輸入文本:`texts = '小紅是我的同學(xué)。小紅是小明的鄰居。小明是我的籃球隊(duì)隊(duì)友。'` 定義要處理的文本,其中包含多個(gè)句子。
- 創(chuàng)建圖譜索引:`index_creator = GraphIndexCreator(llm=llm)` 使用 `GraphIndexCreator` 類來(lái)創(chuàng)建一個(gè)圖索引生成器,它會(huì)用到先前初始化的大型語(yǔ)言模型。
- 初始化最終圖:`final_graph = f_index_creator.from_text('')` 初始化了一個(gè)空的知識(shí)圖譜,用于存放最終的三元組信息。
- 文本切割和三元組生成: `for text in texts.split("."):`這個(gè)循環(huán)通過(guò)句號(hào)切割文本,然后對(duì)每一個(gè)非空句子生成三元組。
- `triples = index_creator.from_text(text)`通過(guò) `index_creator` 的 `from_text` 方法,為每個(gè)句子生成三元組。
- 三元組存儲(chǔ)和輸出:`final_graph.add_triple(KnowledgeTriple(node1, node2,relation ))`將生成的三元組添加到 `final_graph` 知識(shí)圖譜中。
下面是運(yùn)行結(jié)果:
=================
小紅
是
我的同學(xué)
=================
小紅
是
小明的鄰居
=================
小明
是
我的籃球隊(duì)隊(duì)友看起來(lái)是不是比上面NLP處理的結(jié)果要好些。
如果我們將texts變量進(jìn)行修改:
texts = '''小鳥國(guó),正式名稱飛禽國(guó)度(ISO:飛禽國(guó)度),是位于新世界南部的國(guó)家。它以領(lǐng)土面積而言是世界第七大國(guó)家;是人口最多的國(guó)家,一直是世界上人口最多的民主國(guó)家。小鳥國(guó)南臨翡翠海,西南瀕臨藍(lán)色海洋,東南瀕臨碧玉海,與翼足國(guó)家在西部接壤;北部與巨翼國(guó)、鳴蟲國(guó)和象牙國(guó)相鄰;東部與彩虹國(guó)和翡翠國(guó)接壤。在翡翠海中,小鳥國(guó)位于雙島國(guó)家和翡翠群島,與彩虹國(guó)、碧玉國(guó)和綠洲國(guó)共享海上邊界。翡翠海是7大文明遺跡之一,在天門東邊'''用一個(gè)特別復(fù)雜的例子來(lái)表示,這個(gè)例子是我們虛擬的一個(gè)國(guó)家,并且描述了和這個(gè)國(guó)家相關(guān)的一些其他國(guó)家,看上去比較復(fù)雜。此時(shí),我們加入圖表的方式,通過(guò)節(jié)點(diǎn)和邊展示這樣的復(fù)雜關(guān)系。加入如下代碼:
import networkx as nx
import matplotlib.pyplot as plt
#創(chuàng)建一個(gè)空的有向圖
G = nx.DiGraph()
#將上面得到的三元組放到圖像的邊中
#source - node1 , target - node2 , relation - relation
G.add_edges_from((source, target, {'relation': relation}) for source, relation, target in final_graph.get_triples())
#指定圖像的大小和分辨率
plt.figure(figsize=(8,3), dpi=500)
#通過(guò)spring算法定義節(jié)點(diǎn)的布局
pos = nx.spring_layout(G, k=3, seed=0)
edge_labels = nx.get_edge_attributes(G, 'relation')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=8,font_family='simhei')
#定義顯示中文字體
nx.draw_networkx(G, font_family = 'simhei')
#關(guān)閉坐標(biāo)軸顯示
plt.axis('off')
plt.show()這段代碼使用了`networkx`和`matplotlib.pyplot`庫(kù)來(lái)可視化一個(gè)有向圖(即知識(shí)圖譜),其中的節(jié)點(diǎn)和邊是從之前抽取的三元組(實(shí)體-關(guān)系-實(shí)體)中得到的。
1. 創(chuàng)建空的有向圖: `G = nx.DiGraph()`
2. 添加邊到圖中:
`G.add_edges_from((source, target, {'relation': relation}) for source, relation, target in final_graph.get_triples())`
把之前從文本中抽取出的三元組添加到圖`G`中作為邊。每一條邊都有一個(gè)起點(diǎn)(`source`),一個(gè)終點(diǎn)(`target`)以及一個(gè)表示兩者關(guān)系的標(biāo)簽(`relation`)。
3. 設(shè)置圖像大小和分辨率:
`plt.figure(figsize=(8,3), dpi=500)`
設(shè)置了圖像的大小(8x3)和分辨率(500 DPI)。
4. 定義節(jié)點(diǎn)布局:
`pos = nx.spring_layout(G, k=3, seed=0)`
使用“spring”布局算法來(lái)確定圖中每個(gè)節(jié)點(diǎn)的位置。`k`是一個(gè)用于設(shè)置節(jié)點(diǎn)間距的參數(shù),`seed`是隨機(jī)數(shù)生成器的種子。
5. 獲取邊標(biāo)簽并繪制:
`edge_labels = nx.get_edge_attributes(G, 'relation')`
`nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=8, font_family='simhei')`
獲取了圖中每一條邊的標(biāo)簽(即`relation`)并進(jìn)行了繪制。
6. 繪制圖:
`nx.draw_networkx(G, font_family = 'simhei')`
繪制了整個(gè)圖,其中使用了`simhei`字體以支持中文字符。
7. 關(guān)閉坐標(biāo)軸顯示并展示圖像:
`plt.axis('off')`
`plt.show()`
關(guān)閉了坐標(biāo)軸的顯示,并展示了最終的圖像。
看看結(jié)果如何:
=================
小鳥國(guó)
是
新世界南部的國(guó)家
=================
小鳥國(guó)
以
領(lǐng)土面積而言是世界第七大國(guó)家
=================
小鳥國(guó)
是
人口最多的國(guó)家
=================
小鳥國(guó)
是
世界上人口最多的民主國(guó)家
=================
小鳥國(guó)
南臨
翡翠海
=================
小鳥國(guó)
西南瀕臨
藍(lán)色海洋
=================
小鳥國(guó)
東南瀕臨
碧玉海
=================
小鳥國(guó)
與翼足國(guó)家
在西部接壤
=================
小鳥國(guó)
北部與巨翼國(guó)、鳴蟲國(guó)和象牙國(guó)
相鄰
=================
小鳥國(guó)
東部與彩虹國(guó)和翡翠國(guó)
接壤
=================
小鳥國(guó)
在翡翠海中
位于雙島國(guó)家和翡翠群島
=================
小鳥國(guó)
與彩虹國(guó)、碧玉國(guó)和綠洲國(guó)
共享海上邊界
=================
翡翠海
是
7大文明遺跡之一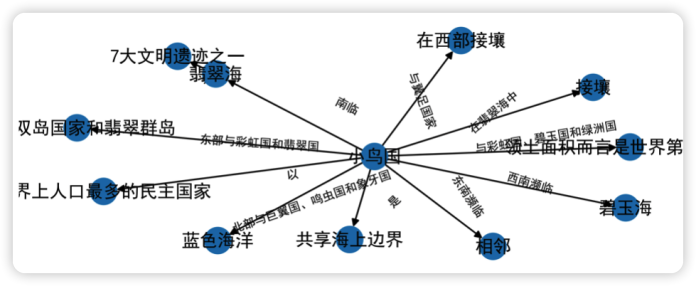
生成的知識(shí)圖譜圍繞著小鳥國(guó)把與之相關(guān)的地方都連接起來(lái)了。
接著針對(duì)上面的知識(shí)圖譜提出問(wèn)題,如下代碼:
chain = GraphQAChain.from_llm(llm, graph=final_graph, verbose=True)
chain.run('翡翠海在哪里?')結(jié)果返回:
> Entering new chain...
Entities Extracted:
翡翠海
Full Context:
翡翠海 7大文明遺跡之一 是知識(shí)圖譜通過(guò)三元組的方式告訴我們 “翡翠海”(實(shí)體1),“7大文明遺跡之一”(實(shí)體2),“是”(關(guān)系)。
開箱即用的GraphGPT
有了上面的實(shí)戰(zhàn)經(jīng)驗(yàn),告訴我們利用大模型能夠更好地進(jìn)行知識(shí)圖譜的處理,并且可以針對(duì)知識(shí)圖譜的內(nèi)容進(jìn)行提問(wèn)。如果覺(jué)得自己開發(fā)這樣一套系統(tǒng)比較麻煩的同學(xué),可以嘗試使用Github上面開源的GraphGPT。
我把地址放在這里,https://github.com/varunshenoy/GraphGPT
GraphGPT 是一個(gè)用于將非結(jié)構(gòu)化自然語(yǔ)言轉(zhuǎn)換成知識(shí)圖譜的項(xiàng)目。它可以接受各種類型的輸入,例如電影劇情梗概、維基百科頁(yè)面或視頻轉(zhuǎn)錄,然后生成一個(gè)可視化圖表來(lái)展示實(shí)體(Entities)之間的關(guān)系。GraphGPT 支持連續(xù)的查詢,可以用于更新現(xiàn)有圖譜的狀態(tài)或創(chuàng)建全新的結(jié)構(gòu)。
安裝步驟
下載依賴項(xiàng)
運(yùn)行npm install 來(lái)下載所需的依賴,當(dāng)前只需要react-graph-vis。
獲取OpenAI API密鑰
確保您擁有一個(gè)OpenAI API密鑰,這將用于在運(yùn)行查詢時(shí)輸入。
啟動(dòng)項(xiàng)目
運(yùn)行npm run start,GraphGPT應(yīng)該會(huì)在新的瀏覽器標(biāo)簽頁(yè)中打開。
通過(guò)這些步驟,您應(yīng)該能夠運(yùn)行GraphGPT并開始將自然語(yǔ)言文本轉(zhuǎn)換為知識(shí)圖譜。
運(yùn)行代碼
根據(jù)上面的步驟運(yùn)行代碼之后,會(huì)在本地http://localhost:3000 打開一個(gè)網(wǎng)站,網(wǎng)站中需要輸入知識(shí)圖譜的文本,以及OpenAI 的Key。
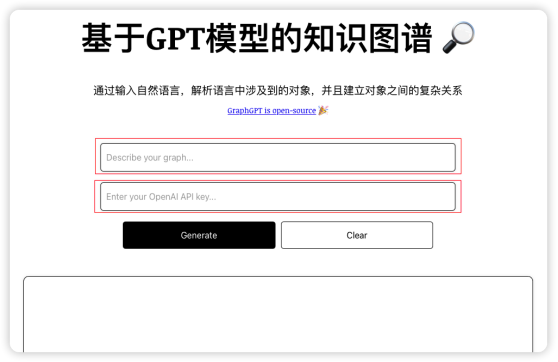
我們嘗試輸入要生成知識(shí)圖譜的文字,然后點(diǎn)擊“Generate”按鈕,然后生成圖形的關(guān)系。

代碼描述
這個(gè)開源項(xiàng)目是通過(guò)js 實(shí)現(xiàn)了大模型的調(diào)用,從而生成知識(shí)圖譜。從下圖的代碼結(jié)構(gòu)上看,主要的業(yè)務(wù)邏輯在App.js 文件和prompts 目錄下面。
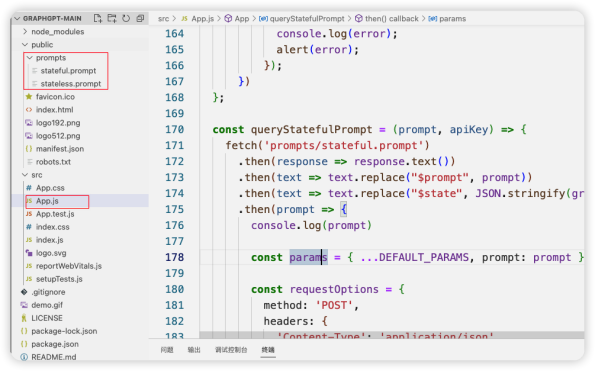
在這個(gè)React應(yīng)用中,主要的目的是通過(guò)GPT模型生成一個(gè)基于輸入自然語(yǔ)言的知識(shí)圖譜。我們把主要的函數(shù)(App.js)進(jìn)行解釋:
- 導(dǎo)入依賴import './App.css'; // 導(dǎo)入CSS樣式import Graph from "react-graph-vis"; // 導(dǎo)入react-graph-vis庫(kù),用于圖的可視化
import React, { useState } from "react"; // 導(dǎo)入React和useState鉤子 - 定義常量const DEFAULT_PARAMS = {...}; // GPT模型的默認(rèn)參數(shù)
const SELECTED_PROMPT = "STATELESS"; // 默認(rèn)使用的提示類型const options = {...}; // 圖的布局和樣式選項(xiàng) - 主要函數(shù)組件 - Appfunction App() { const [graphState, setGraphState] = useState({...}); // 使用useState管理圖的狀態(tài)
const clearState = () => {...}; // 清除圖的狀態(tài)
const updateGraph = (updates) => {...}; // 更新圖的狀態(tài)
const queryStatelessPrompt = (prompt, apiKey) => {...}; // 查詢無(wú)狀態(tài)的提示
const queryStatefulPrompt = (prompt, apiKey) => {...}; // 查詢有狀態(tài)的提示
const queryPrompt = (prompt, apiKey) => {...}; // 根據(jù)選擇的提示類型進(jìn)行查詢
const createGraph = () => {...}; // 創(chuàng)建圖 return (<div className='container'> ... </div>); // 返回應(yīng)用的JSX結(jié)構(gòu)
} - 清除圖的狀態(tài) - clearStateconst clearState = () => {
setGraphState({
nodes: [],
edges: []
});
};
這個(gè)函數(shù)清除圖的所有節(jié)點(diǎn)和邊。 - 更新圖的狀態(tài) - updateGraphconst updateGraph = (updates) => {
var current_graph = JSON.parse(JSON.stringify(graphState)); // 深拷貝當(dāng)前圖的狀態(tài)
// ...
setGraphState(current_graph); // 設(shè)置新的圖狀態(tài)
};
這個(gè)函數(shù)負(fù)責(zé)根據(jù)提供的更新信息(節(jié)點(diǎn)、邊、顏色等)來(lái)更新圖的狀態(tài)。 - 與GPT API進(jìn)行交互 - queryStatelessPrompt 和 queryStatefulPrompt這兩個(gè)函數(shù)與GPT模型進(jìn)行交互,獲取模型生成的文本,并用這些信息更新圖。
- 創(chuàng)建圖 - createGraph
const createGraph = () => {
// ...
queryPrompt(prompt, apiKey); // 調(diào)用queryPrompt進(jìn)行圖的生成
};
```這個(gè)函數(shù)獲取用戶輸入的提示和API密鑰,然后調(diào)用`queryPrompt`函數(shù)生成圖。
另外,又針對(duì)兩種prompt狀態(tài)生成兩種不同的prompt文件:stateful.prompt和stateless.prompt都用于處理知識(shí)圖譜中的實(shí)體和關(guān)系。stateful.prompt是狀態(tài)感知的,會(huì)根據(jù)當(dāng)前圖的狀態(tài)來(lái)添加或修改節(jié)點(diǎn)和邊。適用于需要持續(xù)更新的場(chǎng)景。相對(duì)地,stateless.prompt是無(wú)狀態(tài)的,只根據(jù)給定的提示生成一系列更新,與當(dāng)前圖的狀態(tài)無(wú)關(guān)。適用于一次性或獨(dú)立的更新任務(wù)。兩者主要的區(qū)別在于是否需要考慮圖的當(dāng)前狀態(tài)。
總結(jié)
文章闡述了知識(shí)圖譜和大模型在現(xiàn)代信息處理和決策中無(wú)可替代的地位。從醫(yī)療診斷到金融風(fēng)險(xiǎn)評(píng)估,再到個(gè)性化推薦,知識(shí)圖譜展示了其強(qiáng)大的應(yīng)用潛力。同時(shí),大型語(yǔ)言模型如GPT也在知識(shí)圖譜的生成和查詢中扮演了關(guān)鍵角色。借助大語(yǔ)言模型可以高效地創(chuàng)建知識(shí)圖譜,還能靈活地進(jìn)行實(shí)時(shí)更新和查詢。本文對(duì)于任何希望將大數(shù)據(jù)和AI技術(shù)融入實(shí)際應(yīng)用的人來(lái)說(shuō),都具有指導(dǎo)意義。
作者介紹
崔皓,51CTO社區(qū)編輯,資深架構(gòu)師,擁有18年的軟件開發(fā)和架構(gòu)經(jīng)驗(yàn),10年分布式架構(gòu)經(jīng)驗(yàn)。




























