













知識圖譜入門:使用Python創建知識圖,分析并訓練嵌入模型
本文中我們將解釋如何構建KG、分析它以及創建嵌入模型。

構建知識圖譜
加載我們的數據。在本文中我們將從頭創建一個簡單的KG。
import pandas as pd
# Define the heads, relations, and tails
head = ['drugA', 'drugB', 'drugC', 'drugD', 'drugA', 'drugC', 'drugD', 'drugE', 'gene1', 'gene2','gene3', 'gene4', 'gene50', 'gene2', 'gene3', 'gene4']
relation = ['treats', 'treats', 'treats', 'treats', 'inhibits', 'inhibits', 'inhibits', 'inhibits', 'associated', 'associated', 'associated', 'associated', 'associated', 'interacts', 'interacts', 'interacts']
tail = ['fever', 'hepatitis', 'bleeding', 'pain', 'gene1', 'gene2', 'gene4', 'gene20', 'obesity', 'heart_attack', 'hepatitis', 'bleeding', 'cancer', 'gene1', 'gene20', 'gene50']
# Create a dataframe
df = pd.DataFrame({'head': head, 'relation': relation, 'tail': tail})
df
接下來,創建一個NetworkX圖(G)來表示KG。DataFrame (df)中的每一行都對應于KG中的三元組(頭、關系、尾)。add_edge函數在頭部和尾部實體之間添加邊,關系作為標簽。
import networkx as nx
import matplotlib.pyplot as plt
# Create a knowledge graph
G = nx.Graph()
for _, row in df.iterrows():
G.add_edge(row['head'], row['tail'], label=row['relation'])然后,繪制節點(實體)和邊(關系)以及它們的標簽。
# Visualize the knowledge graph
pos = nx.spring_layout(G, seed=42, k=0.9)
labels = nx.get_edge_attributes(G, 'label')
plt.figure(figsize=(12, 10))
nx.draw(G, pos, with_labels=True, font_size=10, node_size=700, node_color='lightblue', edge_color='gray', alpha=0.6)
nx.draw_networkx_edge_labels(G, pos, edge_labels=labels, font_size=8, label_pos=0.3, verticalalignment='baseline')
plt.title('Knowledge Graph')
plt.show()
現在我們可以進行一些分析。
分析
對于KG,我們可以做的第一件事是查看它有多少個節點和邊,并分析它們之間的關系。
num_nodes = G.number_of_nodes()
num_edges = G.number_of_edges()
print(f'Number of nodes: {num_nodes}')
print(f'Number of edges: {num_edges}')
print(f'Ratio edges to nodes: {round(num_edges / num_nodes, 2)}')
1、節點中心性分析
節點中心性度量圖中節點的重要性或影響。它有助于識別圖結構的中心節點。一些最常見的中心性度量是:
Degree centrality 計算節點上關聯的邊的數量。中心性越高的節點連接越緊密。
degree_centrality = nx.degree_centrality(G)
for node, centrality in degree_centrality.items():
print(f'{node}: Degree Centrality = {centrality:.2f}')
Betweenness centrality 衡量一個節點位于其他節點之間最短路徑上的頻率,或者說衡量一個節點對其他節點之間信息流的影響。具有高中間性的節點可以作為圖的不同部分之間的橋梁。
betweenness_centrality = nx.betweenness_centrality(G)
for node, centrality in betweenness_centrality.items():
print(f'Betweenness Centrality of {node}: {centrality:.2f}')
Closeness centrality 量化一個節點到達圖中所有其他節點的速度。具有較高接近中心性的節點被認為更具中心性,因為它們可以更有效地與其他節點進行通信。
closeness_centrality = nx.closeness_centrality(G)
for node, centrality in closeness_centrality.items():
print(f'Closeness Centrality of {node}: {centrality:.2f}')
可視化
# Calculate centrality measures
degree_centrality = nx.degree_centrality(G)
betweenness_centrality = nx.betweenness_centrality(G)
closeness_centrality = nx.closeness_centrality(G)
# Visualize centrality measures
plt.figure(figsize=(15, 10))
# Degree centrality
plt.subplot(131)
nx.draw(G, pos, with_labels=True, font_size=10, node_size=[v * 3000 for v in degree_centrality.values()], node_color=list(degree_centrality.values()), cmap=plt.cm.Blues, edge_color='gray', alpha=0.6)
plt.title('Degree Centrality')
# Betweenness centrality
plt.subplot(132)
nx.draw(G, pos, with_labels=True, font_size=10, node_size=[v * 3000 for v in betweenness_centrality.values()], node_color=list(betweenness_centrality.values()), cmap=plt.cm.Oranges, edge_color='gray', alpha=0.6)
plt.title('Betweenness Centrality')
# Closeness centrality
plt.subplot(133)
nx.draw(G, pos, with_labels=True, font_size=10, node_size=[v * 3000 for v in closeness_centrality.values()], node_color=list(closeness_centrality.values()), cmap=plt.cm.Greens, edge_color='gray', alpha=0.6)
plt.title('Closeness Centrality')
plt.tight_layout()
plt.show()
2、最短路徑分析
最短路徑分析的重點是尋找圖中兩個節點之間的最短路徑。這可以幫助理解不同實體之間的連通性,以及連接它們所需的最小關系數量。例如,假設你想找到節點“gene2”和“cancer”之間的最短路徑:
source_node = 'gene2'
target_node = 'cancer'
# Find the shortest path
shortest_path = nx.shortest_path(G, source=source_node, target=target_node)
# Visualize the shortest path
plt.figure(figsize=(10, 8))
path_edges = [(shortest_path[i], shortest_path[i + 1]) for i in range(len(shortest_path) — 1)]
nx.draw(G, pos, with_labels=True, font_size=10, node_size=700, node_color='lightblue', edge_color='gray', alpha=0.6)
nx.draw_networkx_edges(G, pos, edgelist=path_edges, edge_color='red', width=2)
plt.title(f'Shortest Path from {source_node} to {target_node}')
plt.show()
print('Shortest Path:', shortest_path)
源節點“gene2”和目標節點“cancer”之間的最短路徑用紅色突出顯示,整個圖的節點和邊緣也被顯示出來。這可以幫助理解兩個實體之間最直接的路徑以及該路徑上的關系。
圖嵌入
圖嵌入是連續向量空間中圖中節點或邊的數學表示。這些嵌入捕獲圖的結構和關系信息,允許我們執行各種分析,例如節點相似性計算和在低維空間中的可視化。
我們將使用node2vec算法,該算法通過在圖上執行隨機游走并優化以保留節點的局部鄰域結構來學習嵌入。
from node2vec import Node2Vec
# Generate node embeddings using node2vec
node2vec = Node2Vec(G, dimensinotallow=64, walk_length=30, num_walks=200, workers=4) # You can adjust these parameters
model = node2vec.fit(window=10, min_count=1, batch_words=4) # Training the model
# Visualize node embeddings using t-SNE
from sklearn.manifold import TSNE
import numpy as np
# Get embeddings for all nodes
embeddings = np.array([model.wv[node] for node in G.nodes()])
# Reduce dimensionality using t-SNE
tsne = TSNE(n_compnotallow=2, perplexity=10, n_iter=400)
embeddings_2d = tsne.fit_transform(embeddings)
# Visualize embeddings in 2D space with node labels
plt.figure(figsize=(12, 10))
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], c='blue', alpha=0.7)
# Add node labels
for i, node in enumerate(G.nodes()):
plt.text(embeddings_2d[i, 0], embeddings_2d[i, 1], node, fnotallow=8)
plt.title('Node Embeddings Visualization')
plt.show()
node2vec算法用于學習KG中節點的64維嵌入。然后使用t-SNE將嵌入減少到2維。并將結果以散點圖方式進行可視化。不相連的子圖是可以在矢量化空間中單獨表示的
聚類
聚類是一種尋找具有相似特征的觀察組的技術。因為是無監督算法,所以不必特別告訴算法如何對這些觀察進行分組,算法會根據數據自行判斷一組中的觀測值(或數據點)比另一組中的其他觀測值更相似。
1、K-means
K-means使用迭代細化方法根據用戶定義的聚類數量(由變量K表示)和數據集生成最終聚類。
我們可以對嵌入空間進行K-means聚類。這樣可以清楚地了解算法是如何基于嵌入對節點進行聚類的:
# Perform K-Means clustering on node embeddings
num_clusters = 3 # Adjust the number of clusters
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(embeddings)
# Visualize K-Means clustering in the embedding space with node labels
plt.figure(figsize=(12, 10))
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], c=cluster_labels, cmap=plt.cm.Set1, alpha=0.7)
# Add node labels
for i, node in enumerate(G.nodes()):
plt.text(embeddings_2d[i, 0], embeddings_2d[i, 1], node, fnotallow=8)
plt.title('K-Means Clustering in Embedding Space with Node Labels')
plt.colorbar(label=”Cluster Label”)
plt.show()
每種顏色代表一個不同的簇。現在我們回到原始圖,在原始空間中解釋這些信息:
from sklearn.cluster import KMeans
# Perform K-Means clustering on node embeddings
num_clusters = 3 # Adjust the number of clusters
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(embeddings)
# Visualize clusters
plt.figure(figsize=(12, 10))
nx.draw(G, pos, with_labels=True, font_size=10, node_size=700, node_color=cluster_labels, cmap=plt.cm.Set1, edge_color=’gray’, alpha=0.6)
plt.title('Graph Clustering using K-Means')
plt.show()
2、DBSCAN
DBSCAN是基于密度的聚類算法,并且不需要預設數量的聚類。它還可以將異常值識別為噪聲。下面是如何使用DBSCAN算法進行圖聚類的示例,重點是基于從node2vec算法獲得的嵌入對節點進行聚類。
from sklearn.cluster import DBSCAN
# Perform DBSCAN clustering on node embeddings
dbscan = DBSCAN(eps=1.0, min_samples=2) # Adjust eps and min_samples
cluster_labels = dbscan.fit_predict(embeddings)
# Visualize clusters
plt.figure(figsize=(12, 10))
nx.draw(G, pos, with_labels=True, font_size=10, node_size=700, node_color=cluster_labels, cmap=plt.cm.Set1, edge_color='gray', alpha=0.6)
plt.title('Graph Clustering using DBSCAN')
plt.show()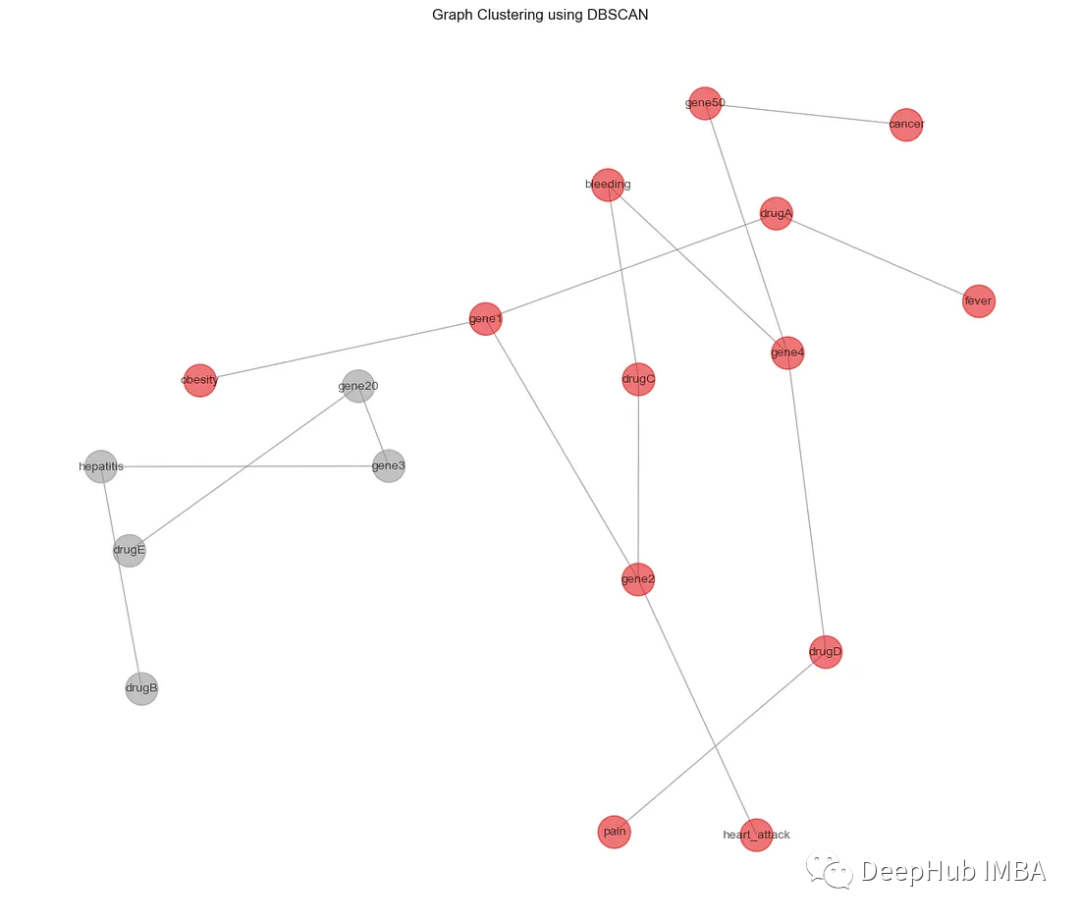
上面的eps參數定義了兩個樣本之間的最大距離,,min_samples參數確定了一個被認為是核心點的鄰域內的最小樣本數。可以看到DBSCAN將節點分配到簇,并識別不屬于任何簇的噪聲點。
總結
分析KGs可以為實體之間的復雜關系和交互提供寶貴的見解。通過結合數據預處理、分析技術、嵌入和聚類分析,可以發現隱藏的模式,并更深入地了解底層數據結構。
本文中的方法可以有效地可視化和探索KGs,是知識圖譜學習中的必要的入門知識。


























