













大模型總結(jié)摘要靠譜嗎?比人類寫的流暢,用GPT-4幻覺還少
文本摘要,作為自然語言生成(NLG)中的一項任務,主要用來將一大段長文本壓縮為簡短的摘要,例如新聞文章、源代碼和跨語言文本等多種內(nèi)容都能用到。
隨著大模型(LLM)的出現(xiàn),傳統(tǒng)的在特定數(shù)據(jù)集上進行微調(diào)的方法已經(jīng)不在適用。
我們不禁會問,LLM 在生成摘要方面效果到底如何?
為了回答這一問題,來自北京大學的研究者在論文《 Summarization is (Almost) Dead 》中進行了深入的探討。他們使用人類生成的評估數(shù)據(jù)集評估了 LLM 在各種摘要任務(單條新聞、多條新聞、對話、源代碼和跨語言摘要)上的表現(xiàn)。
在對 LLM 生成的摘要、人工撰寫的摘要和微調(diào)模型生成的摘要進行定量和定性的比較后發(fā)現(xiàn),由 LLM 生成的摘要明顯受到人類評估者的青睞。
接著該研究在對過去 3 年發(fā)表在 ACL、EMNLP、NAACL 和 COLING 上的 100 篇與摘要方法相關的論文進行抽樣和檢查后,他們發(fā)現(xiàn)大約 70% 的論文的主要貢獻是提出了一種總結(jié)摘要方法并在標準數(shù)據(jù)集上驗證了其有效性。因此,本文表示「摘要(幾乎)已死( Summarization is (Almost) Dead )」。
盡管如此,研究者表示該領域仍然存在挑戰(zhàn),例如需要更高質(zhì)量的參考數(shù)據(jù)集、改進評估方法等還需要解決。

論文地址:https://arxiv.org/pdf/2309.09558.pdf
方法及結(jié)果
該研究使用最新的數(shù)據(jù)來構(gòu)建數(shù)據(jù)集,每個數(shù)據(jù)集由 50 個樣本組成。
例如在執(zhí)行單條新聞、多條新聞和對話摘要任務時,本文采用的方法模擬了 CNN/DailyMail 、Multi-News 使用的數(shù)據(jù)集構(gòu)建方法。對于跨語言摘要任務,其策略與 Zhu 等人提出的方法一致。關于代碼摘要任務,本文采用 Bahrami 等人提出的方法。
數(shù)據(jù)集構(gòu)建完成之后,接下來就是方法了。具體來說,針對單條新聞任務本文采用 BART 和 T5 ;多條新聞任務采用 Pegasus 和 BART;T5 和 BART 用于對話任務;跨語言任務使用 MT5 和 MBART ;源代碼任務使用 Codet5 。
實驗中,該研究聘請人類評估員來比較不同摘要的整體質(zhì)量。結(jié)果如圖 1 所示,LLM 生成的摘要在所有任務中始終優(yōu)于人工生成的摘要和微調(diào)模型生成的摘要。
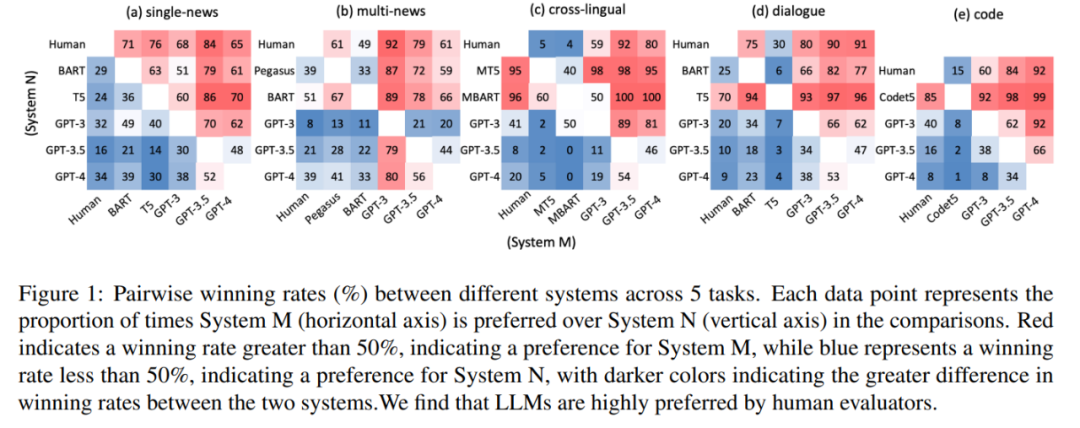
這就提出了一個問題:為什么 LLM 能夠勝過人類撰寫的摘要,而傳統(tǒng)上人們認為這些摘要是完美無缺的。此外,經(jīng)過初步的觀察表明,LLM 生成的摘要表現(xiàn)出高度的流暢性和連貫性。
本文進一步招募注釋者來識別人類和 LLM 生成摘要句子中的幻覺問題,結(jié)果如表 1 所示,與 GPT-4 生成的摘要相比,人工書寫的摘要表現(xiàn)出相同或更高數(shù)量的幻覺。在多條新聞和代碼摘要等特定任務中,人工編寫的摘要表現(xiàn)出明顯較差的事實一致性。

人工撰寫的摘要和 GPT-4 生成摘要中出現(xiàn)幻覺的比例,如表 2 所示:

本文還發(fā)現(xiàn)人工編寫的參考摘要存在這樣一個問題,即缺乏流暢性。如圖 2 (a) 所示,人工編寫的參考摘要有時存在信息不完整的缺陷。并且在圖 2 (b) 中,一些由人工編寫的參考摘要會出現(xiàn)幻覺。

本文還發(fā)現(xiàn)微調(diào)模型生成的摘要往往具有固定且嚴格的長度,而 LLM 能夠根據(jù)輸入信息調(diào)整輸出長度。此外,當輸入包含多個主題時,微調(diào)模型生成的摘要對主題的覆蓋率較低,如圖 3 所示,而 LLM 在生成摘要時能夠捕獲所有主題:

由圖 4 可得,人類對大模型的偏好分數(shù)超過 50%,表明人們對其摘要有強烈的偏好,并凸顯了 LLM 在文本摘要方面的能力:































