













新多模態大模型霸榜!支持圖文混合輸入,不懂知識還能現學
多模態大模型家族,又有新成員了!
不僅能將多張圖像與文本結合分析,還能處理視頻中的時空關系。
這款免費開源的模型,在MMbench和MME榜單同時登頂,目前浮動排名也保持在前三位。
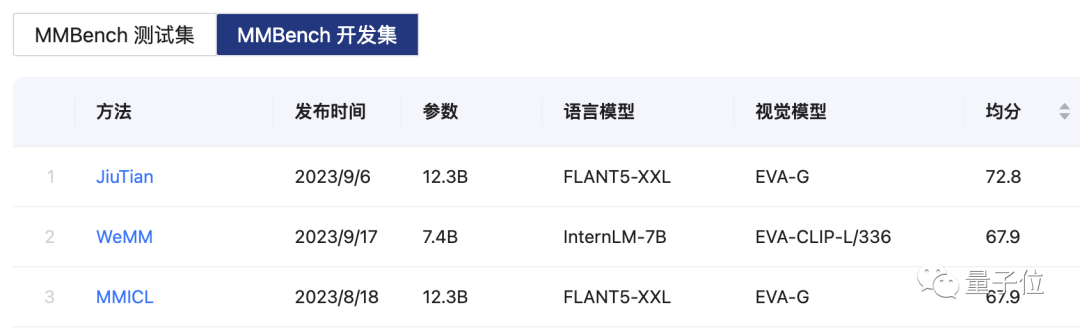
△MMBench榜單,MMBench是上海AI lab和南洋理工大學聯合推出的基于ChatGPT的全方位多模能力評測體系

△MME榜單,MME為騰訊優圖實驗室聯合廈門大學開展的多模態大語言模型測評
這款多模態大模型名叫MMICL,由北京交通大學、北京大學、UCLA、足智多模公司等機構聯合推出。
MMICL一共有兩個基于不同LLM的版本,分別基于Vicuna和FlanT5XL兩種核心模型。
這兩個版本都已經開源,其中,FlanT5XL版可以商用,Vicuna版本只能用于科研用途。
在MME的多項任務測試中,FlanT5XL版MMICL的成績已連續數周保持著領先地位。
其中認知方面取得了428.93的總成績(滿分800),位列第一,大幅超過了其他模型。
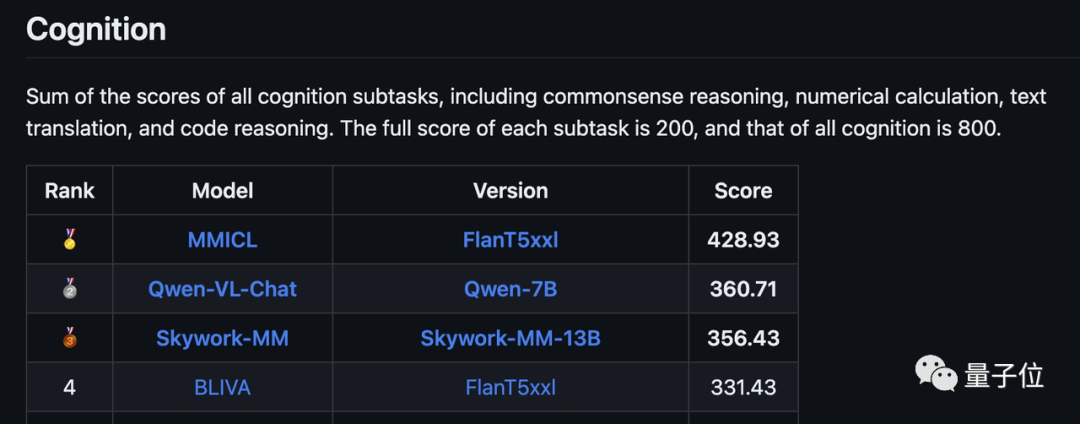
感知方面的總分1381.78(滿分2000),在最新版榜單中僅次于阿里的千問-7B和昆侖萬維的天工模型。

所需配置方面,官方給出的說法是在訓練階段需要6塊A40,推理階段則可以在一塊A40上運行。
僅僅只需要從開源數據集中構建的0.5M的數據即可完成第二階段的訓練,耗時僅需幾十小時。
那么,這個多模態大模型都有哪些特色呢?
會看視頻,還能“現學現賣”
MMICL支持文本和圖片穿插形式的prompt,用起來就像微信聊天一樣自然。
用正常說話的方式把兩張圖喂給MMICL,就可以分析出它們的相似和不同之處。

除了超強的圖像分析能力,MMICL還知道“現學現賣”。
比如我們丟給MMICL一張“我的世界”中像素風格的馬。
由于訓練數據都是真實世界的場景,這種過于抽象的像素風MMICL并不認識。

但我們只要讓MMICL學習幾個例子,它便能很快地進行類比推理。
下圖中,MMICL分別學習了有馬、驢和什么都沒有這三種場景,然后便正確判斷出了更換背景后的像素馬。

除了圖片,動態的視頻也難不倒MMICL,不僅是理解每一幀的內容,還能準確地分析出時空關系。
不妨來看一下這場巴西和阿根廷的足球大戰,MMICL準確地分析出了兩支隊伍的行動。

針對視頻當中的細節,也可以向MMICL提問,比如巴西球員是怎么阻擋阿根廷隊員的。

除了準確把握視頻中的時空關系,MMICL還支持實時視頻流輸入。
我們可以看到,監控畫面中的人正在摔倒,MMICL檢測到了這一異常現象并發出了提示,詢問是否需要幫助。

如果把MME榜上感知和認知兩項的前五名放在一張圖里比較,我們可以看出,MMICL的表現在各個方面都有不俗的成績。

那么,MMICL是如何做到的,背后又有什么樣的技術細節呢?
訓練分兩階段完成
MMICL致力于解決視覺語言模型在理解具有多個圖像的復雜多模態輸入方面遇到的問題。
MMICL利用Flan-T5 XXL模型作為骨干,整個模型的結構和流程如下圖所示:

MMICL使用類似于BLIP2的結構,但是能夠接受交錯的圖文的輸入。
MMICL將圖文平等對待,把處理后的圖文特征,都按照輸入的格式,拼接成圖文交錯的形式輸入到語言模型中進行訓練和推理。
類似于InstructBLIP,MMICL的開發過程是將LLM凍結,訓練Q-former,并在特定數據集上對其進行微調。
MMICL的訓練流程和數據構造如下圖所示:

具體來說,MMICL的訓練一共分成了兩個階段:
- 預訓練階段,使用了LAION-400M(參考LLaVA)數據集
- 多模態in-context tuning,使用了自有的MIC(Multi-Model In-Context Learning)數據集

MIC數據集由公開數據集構建而來,上圖展示了MIC數據集當中所包含的內容,而MIC數據集還具有這幾個特色:
第一是圖文間建立的顯式指代,MIC在圖文交錯的數據中,插入圖片聲明(image declaration),使用圖片代理(image proxy)token來代理不同的圖片,利用自然語言來建立圖文間的指代關系。

第二是空間,時間或邏輯上互相關聯的多圖數據集,確保了MMICL模型能對圖像間的關系有更準確的理解。

第三個特色是示例數據集,類似于讓MMICL“現場學習”的過程,使用多模態的上下文學習來增強MMICL對圖文穿插式的復雜圖文輸入的理解。

MMICL在多個測試數據集上取得的成績超過了同樣使用FlanT5XXL的BLIP2和InstructionBLIP。
尤其是對于涉及多張圖的任務,對這種復雜圖文輸入,MMICL表現了極大的提升。

研究團隊認為,MMICL解決了視覺語言模型中常常存在的語言偏見(language bais)問題是取得優異成績的原因之一。
大多數視覺語言模型在面對大量文本的上下文內容時會忽視視覺內容,而這是回答需要視覺信息的問題時的致命缺陷。
而得益于研究團隊的方法,MMICL成功緩解了在視覺語言模型中的這種語言偏見。

對這個多模態大模型感興趣的讀者,可以到GitHub頁面或論文中查看更多詳情。
GitHub頁面:https://github.com/HaozheZhao/MIC
論文地址:https://arxiv.org/abs/2309.07915在線demo:
http://www.testmmicl.work/




























