云應用容器的向左監控方法
在彈性容器化環境中,擁有低效代碼是非常昂貴的。通過向左監控方法和可觀測性解決方案,可以幫助解決這個問題。
向左移動(Shift-left)是一種軟件開發和運維的方法,強調在軟件開發生命周期的早期進行測試、監控和自動化。向左移動的目標是在問題出現之前及時發現并迅速解決,以防止問題的發生。
當您早期識別到可擴展性問題或錯誤時,解決起來更快、更具成本效益。將低效代碼轉移到云容器中可能非常昂貴,因為它可能會激活自動擴展功能,增加您的月度費用。此外,在您能夠識別、隔離和修復問題之前,您將處于緊急狀態。
問題陳述
我想給您演示一個案例,我們成功地避免了一個潛在的應用程序問題,在生產環境中可能會造成重大影響。
2022年我們的Kubernetes報告提供了關于團隊如何利用Kubernetes、AI中的K8s、集群可觀測性方面的見解等內容。
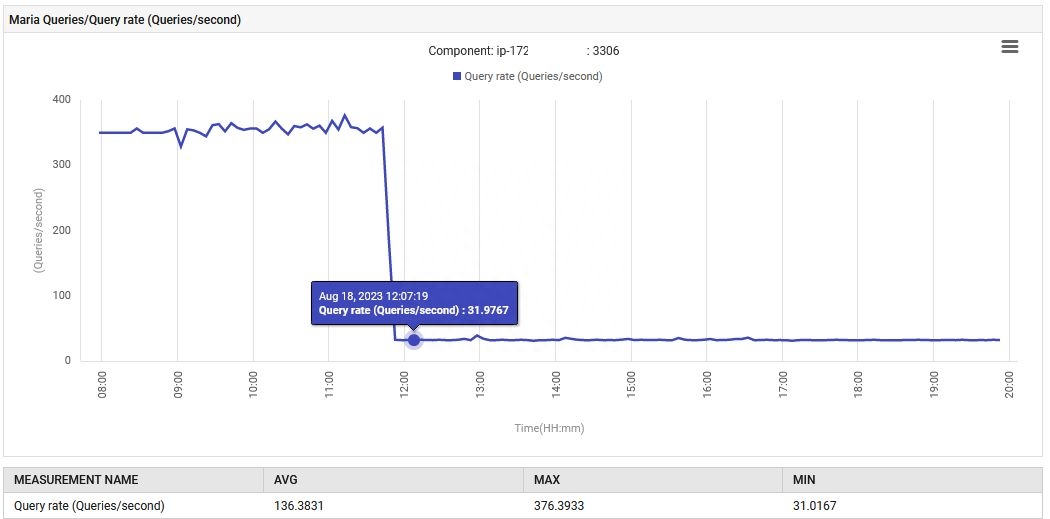
我正在審查最近應用程序更改后的UAT基礎架構的性能報告。這是一個使用MariaDB作為后端、運行在Apache反向代理和AWS應用負載均衡器后面的Spring Boot微服務。新功能成功集成,并且通過了所有UAT測試用例。然而,我注意到MariaDB性能儀表板中的性能圖表與部署前的模式有所偏離。
以下是事件的時間軸。
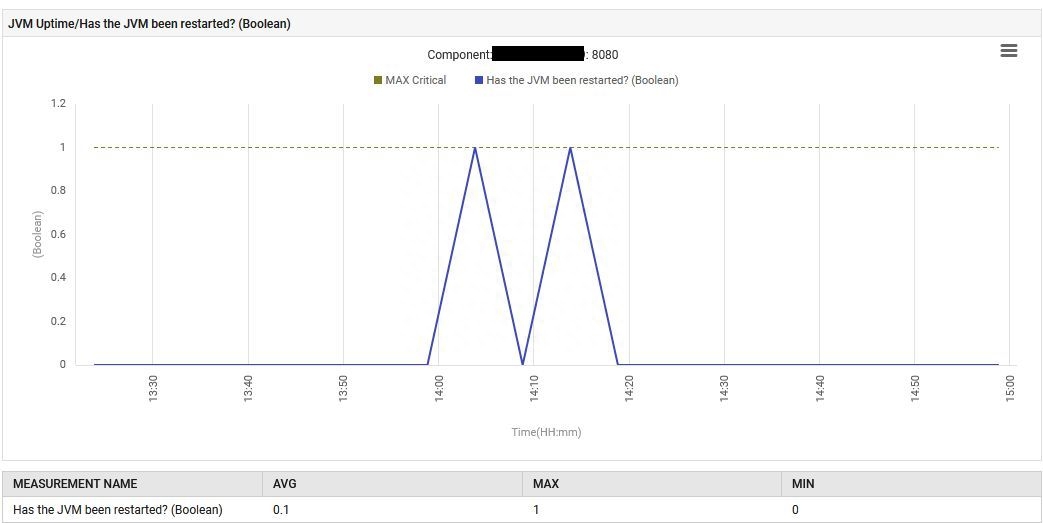
8月6日14:13,應用程序使用包含嵌入式Tomcat的新Spring Boot jar文件重新啟動。
14:52,MariaDB的查詢處理速率從每秒0.1增加到88次查詢/秒,然后增加到301次查詢/秒。
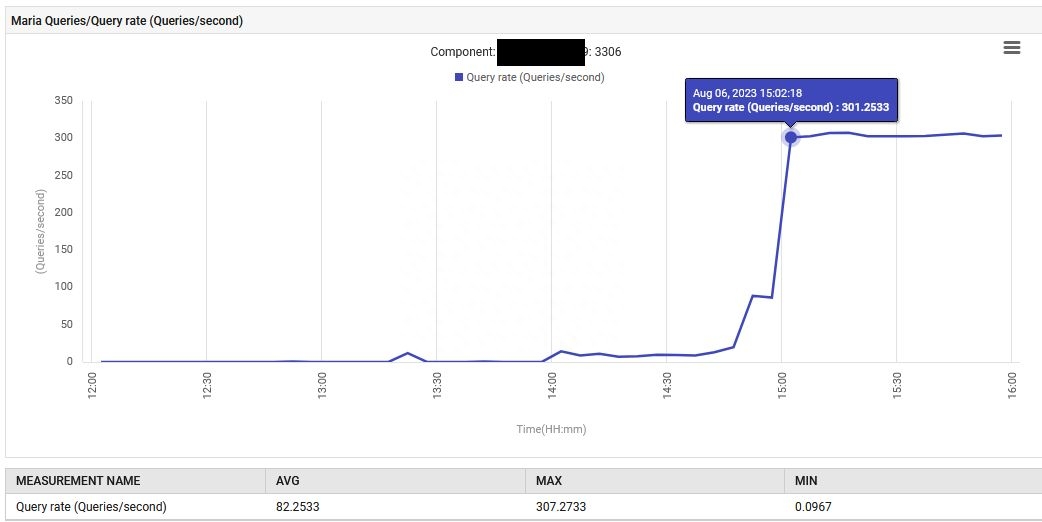
此外,系統CPU利用率從1%提高到6%。

最后,JVM在G1 Young Generation Garbage Collection上花費的時間從0%增加到0.1%,并保持在這個水平。
該應用程序在UAT階段異常地發出300次查詢/秒,遠遠超出了其設計要求。新功能導致數據庫連接增加,因此查詢量顯著增加。然而,監控儀表板顯示,在部署新版本之前,問題措施是正常的。
解決方案
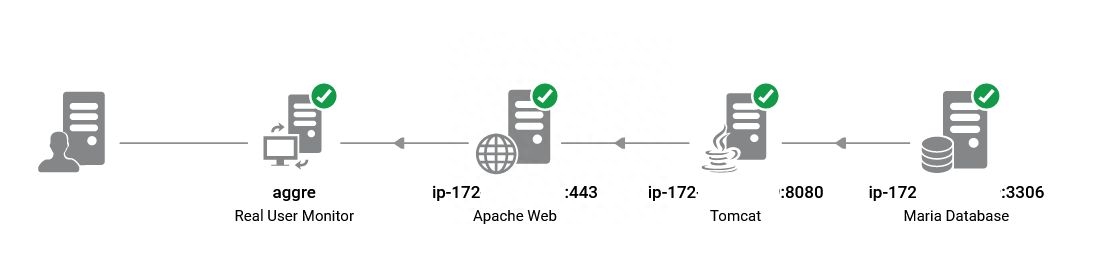
這是一個使用JPA查詢MariaDB的Spring Boot應用程序。該應用程序的設計是在兩個容器上運行以實現最小負載,但可以擴展到十個容器。
如果一個單獨的容器可以生成每秒300次查詢,那么如果所有十個容器都運行,它可以處理每秒3000次查詢嗎?數據庫能否擁有足夠的連接來滿足應用程序其他部分的需求?
我們別無選擇,只能返回開發人員的工作臺,檢查Git中的更改。
新的更改將從一個表中獲取少量記錄并進行處理。這是我們在服務類中觀察到的代碼。
List<X> findAll = this.xRepository.findAll();不,使用Spring的CrudRepository的findAll()方法而沒有分頁是低效的。分頁有助于減少從數據庫檢索數據所需的時間,通過限制獲取的數據量。這是我們主要的關系型數據庫(RDBMS)教育所教導我們的。此外,分頁有助于保持內存使用低,以防止應用程序由于數據過載而崩潰,并減少Java虛擬機的垃圾回收工作量,正如前面問題陳述中提到的。
這個測試是在一個容器中使用2000條記錄進行的。如果這段代碼被部署到生產環境中,其中每個容器有約20萬條記錄,那么可能會給團隊帶來很大的壓力和憂慮。
應用程序在將方法添加WHERE子句后重新構建。
List<X> findAll =
this.xRepository.findAllByY(Y);恢復了正常運行。每秒查詢數從300降至30,垃圾收集的工作量恢復到原始水平。此外,系統的CPU使用率降低。
學習和總結
任何從事站點可靠性工程(SRE)工作的人都會理解這個發現的重要性。我們能夠在不提高嚴重性1級別的情況下采取行動。如果這個有缺陷的軟件包部署到生產環境中,可能會觸發客戶的自動擴展閾值,即使沒有額外的用戶負載,也會啟動新的容器。
這個故事有三個主要的要點。
首先,最好從一開始就啟用一個可觀測性解決方案,因為它可以提供事件的歷史記錄,用于識別潛在問題。如果沒有這個歷史記錄,我可能不會認真對待0.1%的垃圾回收百分比和6%的CPU消耗,代碼可能會發布到生產環境中,造成災難性的后果。擴大監控解決方案的范圍到UAT服務器有助于團隊在問題發生前識別潛在根本原因并防止問題發生。
其次,在測試過程中應存在與性能相關的測試用例,并由具有可觀測性經驗的人員進行審查。這將確保對代碼的功能和性能進行測試。
第三,云原生的性能跟蹤技術對于接收有關高利用率、可用性等方面的警報非常有用。為了實現可觀測性,您可能需要準備合適的工具和專業知識。祝編碼愉快!