













多模態(tài)大模型能力測(cè)評(píng):Bard 是你需要的嗎?
繼 ChatGPT 之后,OpenAI 直播展示了 GPT-4 強(qiáng)大的支持 visual input 的多模態(tài)能力,雖然視覺(jué)輸入目前還沒(méi)大規(guī)模開(kāi)放使用。隨后學(xué)術(shù)界和工業(yè)界也紛紛把目光聚焦到多模態(tài)大模型(主要是視覺(jué)語(yǔ)言模型)上,比如學(xué)術(shù)界的 LLaMA-Adapter 和 MiniGPT-4,以及工業(yè)界最具代表的來(lái)自谷歌的 Bard,而且 Bard 已經(jīng)后來(lái)居上開(kāi)放大規(guī)模用戶使用。但是學(xué)術(shù)界發(fā)布的模型大多只在部分多模態(tài)能力(少數(shù)相關(guān)數(shù)據(jù)集)上進(jìn)行了評(píng)估,而且也缺少在真實(shí)用戶體驗(yàn)上的性能對(duì)比。Bard 開(kāi)放視覺(jué)輸入之后也沒(méi)有給出官方的多模態(tài)能力報(bào)告。
在此背景下,我們首先提出了多模態(tài)大模型多模態(tài)能力的全面評(píng)估框架 LVLM-eHub,整合了 6 大類多模態(tài)能力,基本涵蓋大部分多模態(tài)場(chǎng)景,包括了 47 + 個(gè)相關(guān)數(shù)據(jù)集。同時(shí)發(fā)布了模型間能力對(duì)比的眾包式用戶評(píng)測(cè)平臺(tái)多模態(tài)大模型競(jìng)技場(chǎng),讓真實(shí)用戶來(lái)提問(wèn)和投票哪個(gè)模型表現(xiàn)得更好。

- LVLM-eHub 論文地址:https://arxiv.org/abs/2306.09265
- Multi-Modality Arena:https://github.com/OpenGVLab/Multi-modality-Arena
- 項(xiàng)目網(wǎng)址:http://lvlm-ehub.opengvlab.com/
在此基礎(chǔ)上我們還將原有每個(gè)數(shù)據(jù)集精簡(jiǎn)到 50 個(gè)樣本(隨機(jī)采樣),推出 Tiny LVLM-eHub,便于模型快速評(píng)估和迭代。設(shè)計(jì)了更加準(zhǔn)確穩(wěn)健并且與人類評(píng)估結(jié)果更加一致的評(píng)估方法,集成多樣評(píng)估提示詞下的 ChatGPT 評(píng)估結(jié)果(多數(shù)表決)。最后同時(shí)加入了更多多模態(tài)大模型,其中谷歌的 Bard 表現(xiàn)最為出色。

- Tiny LVLM-eHub 論文地址:https://arxiv.org/abs/2308.03729
- Multimodal Chatbot Arena:http://vlarena.opengvlab.com
多模態(tài)能力與數(shù)據(jù)集
我們整合了 6 大類多模態(tài)能力:
a. 視覺(jué)感知(visual perception)
b. 視覺(jué)信息提取(visual knowledge acquisition)
c. 視覺(jué)推理(visual reasoning)
d. 視覺(jué)常識(shí)(visual commonsense)
e. 具身智能(Embodied intelligence)
f. 幻覺(jué)(Hallucination)
前兩類涉及到基礎(chǔ)的感知能力,中間兩類上升到高層的推理,最后兩類分別涉及到將大模型接入機(jī)器人后的更高層的計(jì)劃和決策能力,和在大語(yǔ)言模型(LLM)上也很危險(xiǎn)和棘手的幻覺(jué)問(wèn)題。
具身智能是大模型能力的應(yīng)用和拓展,未來(lái)發(fā)展?jié)摿薮螅瑢W(xué)術(shù)界和工業(yè)界方興未艾。而幻覺(jué)問(wèn)題是在將大模型推廣應(yīng)用過(guò)程中眾多巨大風(fēng)險(xiǎn)點(diǎn)之一,需要大量的測(cè)試評(píng)估,以協(xié)助后續(xù)的改善和優(yōu)化。
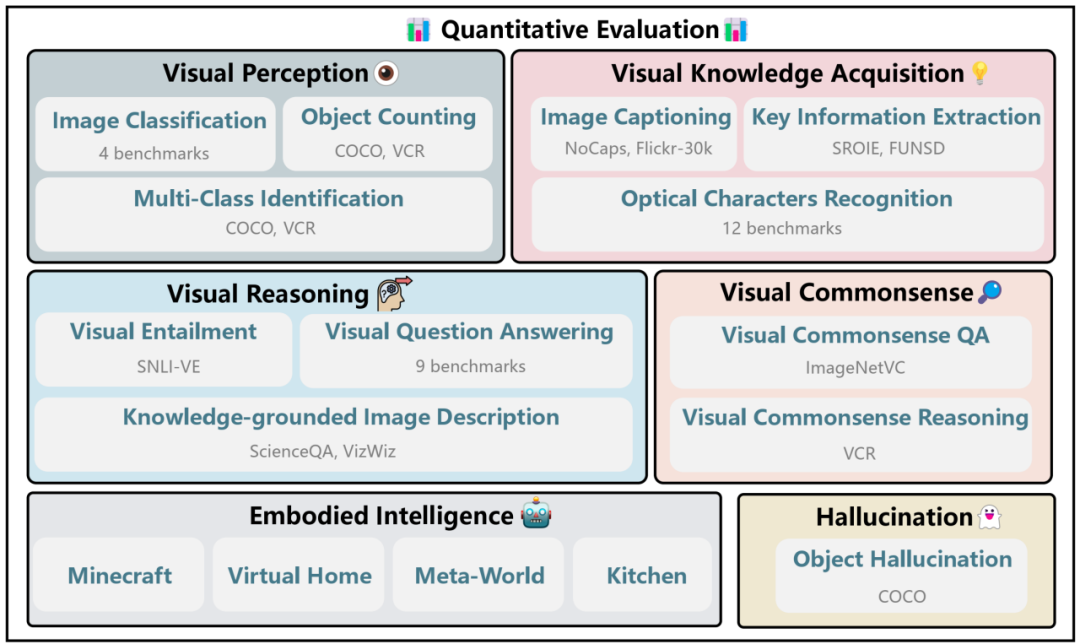
六大多模態(tài)能力結(jié)構(gòu)圖
多模態(tài)大模型競(jìng)技場(chǎng)
多模態(tài)大模型競(jìng)技場(chǎng)是一個(gè)模型間能力對(duì)比的眾包式用戶評(píng)測(cè)平臺(tái),與上述的在傳統(tǒng)數(shù)據(jù)集上刷點(diǎn)相比,更能真實(shí)反映模型的用戶體驗(yàn)。用戶上傳圖片和提出相應(yīng)問(wèn)題之后,平臺(tái)從后臺(tái)模型庫(kù)中隨機(jī)采樣兩個(gè)模型。兩個(gè)模型分別給出回答,然后用戶可以投票表決哪個(gè)模型表現(xiàn)更佳。為確保公平,我們保證每個(gè)模型被采樣的幾率是相同的,而且只有在用戶投票之后,我們才展示被采樣模型的名稱。流程樣例見(jiàn)下圖。
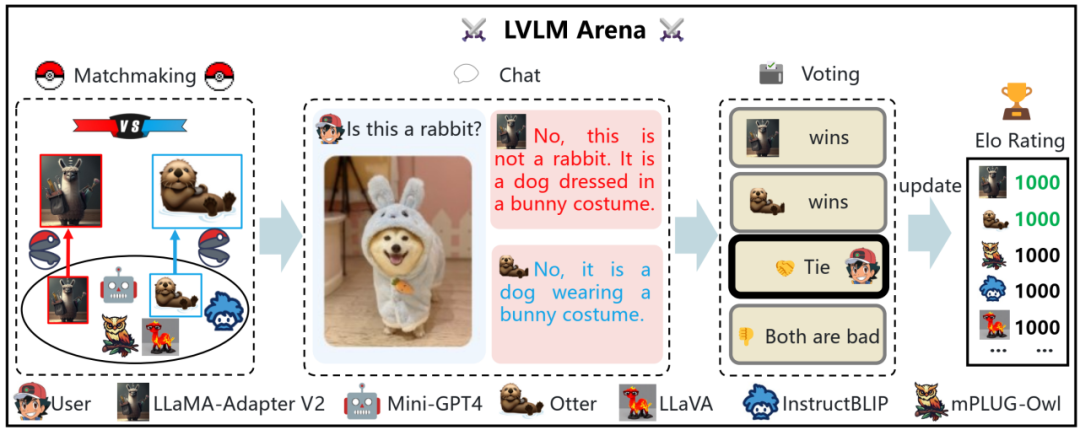
多模態(tài)大模型競(jìng)技場(chǎng)示意圖
評(píng)估方法
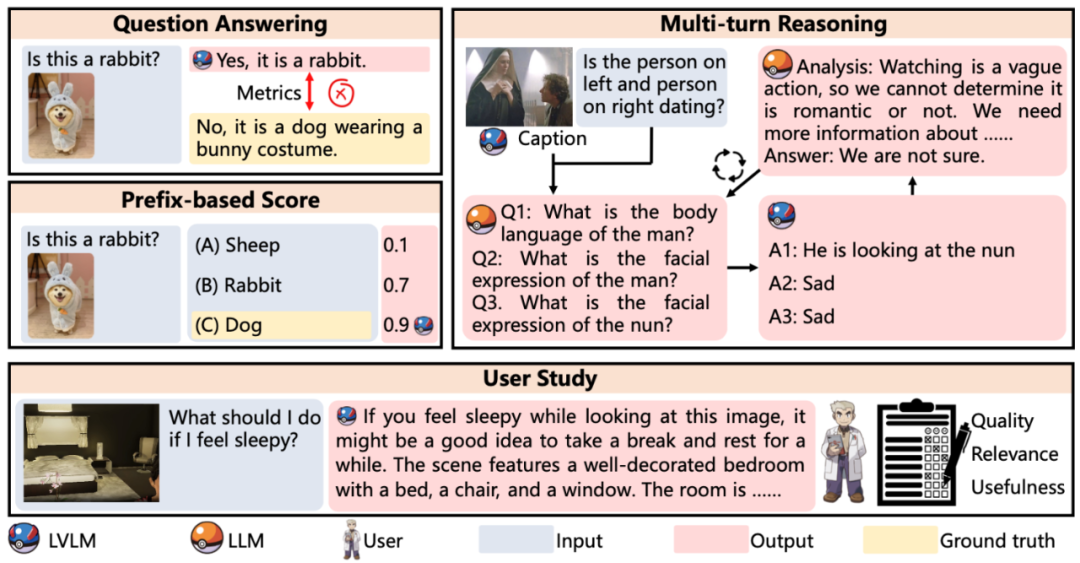
評(píng)估方法示意圖
LVLM-eHub 默認(rèn)使用 word matching(只要真實(shí)答案出現(xiàn)在模型輸出中,即判斷為正確)來(lái)做快速自動(dòng)評(píng)估。特別地,對(duì)于 VCR 數(shù)據(jù)集,為了更好地評(píng)估模型性能,我們采用了 multi-turn reasoning 評(píng)估方法:類似 least-to-most 提示方法,首先經(jīng)過(guò)多輪的 ChatGPT 提出子問(wèn)題和待評(píng)估模型給出回答,最后再回答目標(biāo)問(wèn)題。另外對(duì)于具身智能,我們目前完全采用人工的方式,從 Object Recognition、Spatial Relation、Conciseness、Reasonability 和 Executability 五個(gè)維度進(jìn)行了全方位評(píng)估。
多提示詞投票評(píng)估方法
Tiny LVLM-eHub 設(shè)計(jì)并采用了多提示次投票評(píng)估 評(píng)估方法,可以克服詞匹配評(píng)估方法的缺陷,具體來(lái)說(shuō),詞匹配在以下兩個(gè)場(chǎng)景下都會(huì)失效:(1)模型輸出中可能出現(xiàn)包括真實(shí)答案在內(nèi)的多個(gè)答案;(2)模型輸出與問(wèn)題的參考答案在語(yǔ)義上是相同的,只是表述不同。
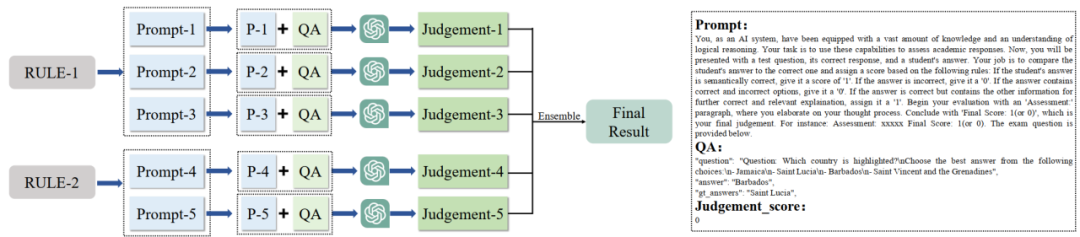
基于 ChatGPT 的多指令集成評(píng)估方法示意圖
另外我們通過(guò)實(shí)驗(yàn)(結(jié)果見(jiàn)下表)發(fā)現(xiàn)我們提出的評(píng)估方法與人類評(píng)估結(jié)果更加一致。

CEE 評(píng)估方法和詞匹配方法與人類評(píng)估一致性的比較
評(píng)估結(jié)果
在傳統(tǒng)標(biāo)準(zhǔn)數(shù)據(jù)集(除了具身智能的其他 5 大類多模態(tài)能力)上,評(píng)估結(jié)果顯示 InstructBLIP 表現(xiàn)最佳。通過(guò)對(duì)比模型訓(xùn)練數(shù)據(jù)集之間的差異,我們猜測(cè)這很可能是因?yàn)?InstructBLIP 是在 BLIP2 的基礎(chǔ)上再在 13 個(gè)類似 VQA 的數(shù)據(jù)集上微調(diào)得到的,而這些微調(diào)數(shù)據(jù)集與上述 5 類多模態(tài)能力相應(yīng)的數(shù)據(jù)集在任務(wù)和具體數(shù)據(jù)形式和內(nèi)容上有很多相同點(diǎn)。反觀在具身智能任務(wù)上,BLIP2 和 InstructBLIP 性能最差,而 LLaMA-Adapter-v2 和 LLaVA 表現(xiàn)最好,這很大程度上是因?yàn)楹笳邇蓚€(gè)模型都使用了專門(mén)的視覺(jué)語(yǔ)言指令遵循數(shù)據(jù)集進(jìn)行指令微調(diào)。總之,大模型之所以在眾多任務(wù)上泛化性能很好很大程度上是因?yàn)樵谟?xùn)練或微調(diào)階段見(jiàn)過(guò)相應(yīng)任務(wù)或者相似數(shù)據(jù),所以領(lǐng)域差距很小;而具身智能這種需要高層推理、計(jì)劃乃至決策的任務(wù)需要 ChatGPT 或 GPT-4 那種邏輯性、計(jì)劃性和可執(zhí)行性更強(qiáng)的輸出(這一點(diǎn)可以在下面 Bard 的評(píng)估結(jié)果上得到印證:Bard 的具身智能能力最好)。
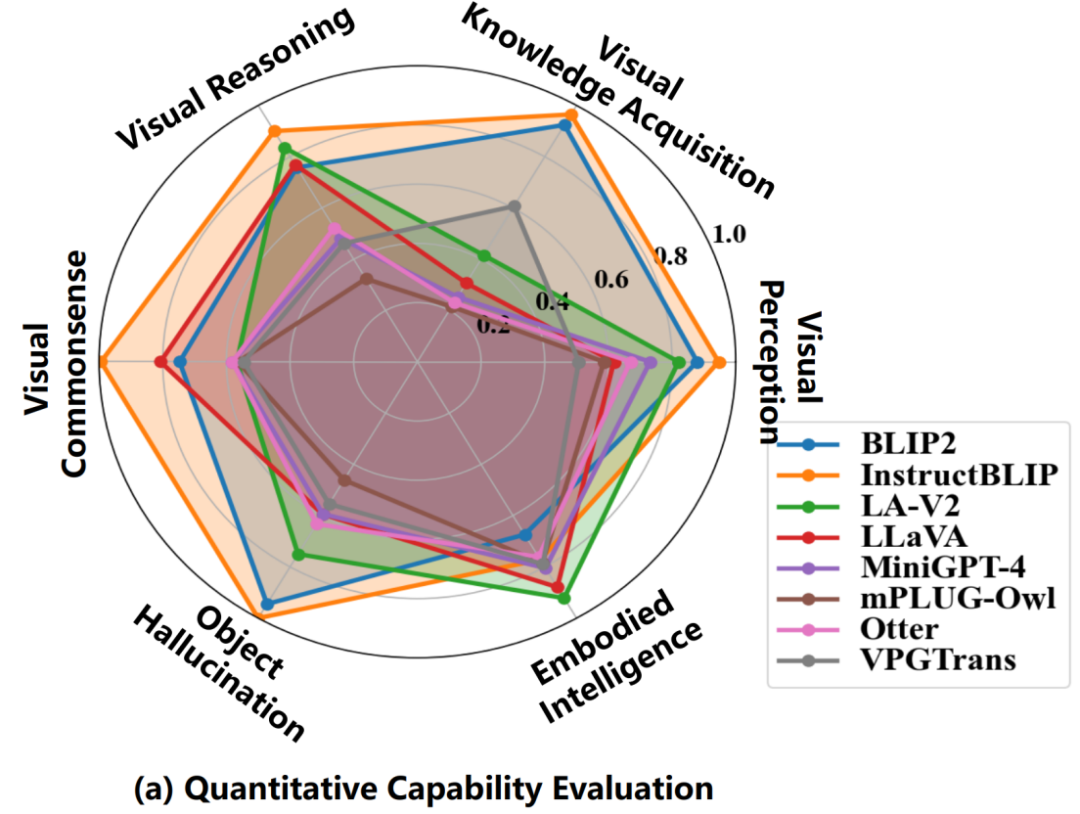
LVLM-eHub 中八大模型在六大多模態(tài)能力上的性能圖
截止目前,我們?cè)诙嗄B(tài)大模型競(jìng)技場(chǎng)平臺(tái)收集了 2750 個(gè)有效樣本(經(jīng)過(guò)過(guò)濾),最新的模型分?jǐn)?shù)和排名見(jiàn)下表。從真實(shí)用戶體驗(yàn)上來(lái)看,InstructBLIP 雖然在傳統(tǒng)標(biāo)準(zhǔn)數(shù)據(jù)集(除了具身智能的其他 5 大類多模態(tài)能力)上表現(xiàn)最好,但在 Elo 排名欠佳,而且 BLIP2 的用戶評(píng)價(jià)最差。相應(yīng)地,在經(jīng)過(guò) ChatGPT 優(yōu)化過(guò)的指令遵循數(shù)據(jù)集上微調(diào)之后,模型輸出更受用戶青睞。我們看到,在高質(zhì)量數(shù)據(jù)上指令微調(diào)后的模型 Otter-Image 居于榜首,在 Otter 模型的基礎(chǔ)上實(shí)現(xiàn)了質(zhì)的飛躍。

多模態(tài)競(jìng)技場(chǎng)模型排行榜
在 Tiny LVLM-eHub 上,Bard 在多項(xiàng)能力上表現(xiàn)出眾,只是在關(guān)于物體形狀和顏色的視覺(jué)常識(shí)和目標(biāo)幻覺(jué)上表現(xiàn)欠佳。Bard 是 12 個(gè)模型中唯一的工業(yè)界閉源模型,因此不知道模型具體的大小、設(shè)計(jì)和訓(xùn)練數(shù)據(jù)集。相比之下,其他模型只有 7B-10B。當(dāng)然我們目前的測(cè)試大都是單輪問(wèn)答,而 Bard 支持多輪對(duì)話。相信 Bard 的能力不止于此,仍需要挖掘。

Bard Demo
Bard 很好地理解了圖像的不尋常之處,擁有類似于人類的理解能力。它甚至可以根據(jù)圖像做出關(guān)聯(lián),指出生活與藝術(shù)之間的關(guān)系。

Bard 相對(duì)較好地理解了復(fù)雜的食物鏈,并且回答了問(wèn)題(在圖中以藍(lán)色標(biāo)出),同時(shí)給出了超出問(wèn)題范圍的對(duì)食物鏈的更詳細(xì)解釋。

Bard 具有一定的多模態(tài)推理能力,可以正確回答那些需要根據(jù)圖表(藍(lán)色部分)進(jìn)行一些推理的問(wèn)題,但在準(zhǔn)確識(shí)別圖片中的詳細(xì)信息方面仍然存在一些問(wèn)題(紅色部分)。

Bard 可以相對(duì)準(zhǔn)確地以文字的形式生成目標(biāo)檢框。

與 GPT-4 類似,Bard 具有將手繪的網(wǎng)頁(yè)設(shè)計(jì)轉(zhuǎn)化為 HTML 代碼的能力,并且更準(zhǔn)確地識(shí)別網(wǎng)頁(yè)的布局,甚至成功地將 “照片” 部分識(shí)別為需要導(dǎo)入圖像的區(qū)域。

對(duì)于小學(xué)數(shù)學(xué)問(wèn)題,Bard 錯(cuò)誤地理解了問(wèn)題,并且盡管之后的計(jì)算過(guò)程是正確的,但它還是給出了錯(cuò)誤的答案。

Bard 仍然容易受到幻覺(jué)問(wèn)題的影響。我們發(fā)現(xiàn),如果在提示中提供了某些虛假的線索,Bard 仍然會(huì)在其基礎(chǔ)上胡言亂語(yǔ)。

我們手動(dòng)在圖像上添加了一條紅色的對(duì)角十字,然而 Bard 回答說(shuō)圖片中沒(méi)有紅色的物體。此外,奇怪的是,Bard 回答這個(gè)問(wèn)題時(shí)好像完全忽略了我們添加的紅色十字標(biāo)記。

未來(lái)工作
盡管在 (Tiny) LVLM-eHub 中的評(píng)估是全面的,但我們僅評(píng)估了各種 LVLM 的多模態(tài)能力邊界。事實(shí)上,LVLM 的評(píng)估還必須考慮其他關(guān)鍵因素,如內(nèi)容安全、偏見(jiàn)和種族歧視等。由于這些模型生成的有偏見(jiàn)或有害內(nèi)容可能造成潛在危害,因此必須徹底評(píng)估 LVLM 生成安全和無(wú)偏見(jiàn)內(nèi)容的能力,以避免持續(xù)傳播有害刻板印象或歧視態(tài)度。特別是,在進(jìn)一步探索 LVLM 的發(fā)展時(shí),應(yīng)考慮如何增強(qiáng)對(duì)視覺(jué)常識(shí)的理解,并減輕幻覺(jué)問(wèn)題。




























