用別的模型權(quán)重訓(xùn)練神經(jīng)網(wǎng)絡(luò),改神經(jīng)元不影響輸出:英偉達(dá)神奇研究
不論計算機(jī)視覺還是 NLP,深度神經(jīng)網(wǎng)絡(luò)(DNN)是如今我們完成機(jī)器學(xué)習(xí)任務(wù)的首選方法。在基于此構(gòu)建的模型中,我們都需要對模型權(quán)重執(zhí)行某種變換,但執(zhí)行該過程的最佳方法是什么?
最近,英偉達(dá)對其 ICML 2023 研究 DWSNet 進(jìn)行了解讀。DWSNet 展示了一種全新架構(gòu),它可以有效處理神經(jīng)網(wǎng)絡(luò)的權(quán)重,同時保持其排列對稱性的等方差。
根據(jù)這種方法,我們可以根據(jù)其他網(wǎng)絡(luò)的權(quán)重來訓(xùn)練一個網(wǎng)絡(luò),這也許是一個用來做持續(xù)學(xué)習(xí)的好方法。同樣有趣的是,基于 DWSNet 的探索,我們發(fā)現(xiàn)網(wǎng)絡(luò)權(quán)重具有排列對稱性 —— 這意味著可以更改神經(jīng)元的順序而不更改輸出。

- 論文鏈接:https://arxiv.org/abs/2301.12780
- 官方 GitHub:https://github.com/AvivNavon/DWSNets
這種方法被認(rèn)為具有廣泛潛力,可以實現(xiàn)各種有趣的任務(wù),例如使預(yù)先訓(xùn)練的網(wǎng)絡(luò)適應(yīng)新的領(lǐng)域。或許我們可以訓(xùn)練一個從另一個網(wǎng)絡(luò)提取、編輯或刪除信息的網(wǎng)絡(luò)。
而在生成模型上,我們或許可以在很多針對各種任務(wù)進(jìn)行訓(xùn)練的網(wǎng)絡(luò)上進(jìn)行訓(xùn)練,然后在運行時為特定任務(wù)生成一個網(wǎng)絡(luò) —— 就像現(xiàn)代版本的快速權(quán)重網(wǎng)絡(luò)一樣。
讓我們看看 DWSNet 是怎么做到的:
在使用隱式神經(jīng)表征(Implicit Neural Representations,INR)或神經(jīng)輻射場(Neural Radiance Fields,NeRF)表征的 3D 對象數(shù)據(jù)集時,我們經(jīng)常需要「編輯」對象以更改其幾何形狀或修復(fù)錯誤,例如移除杯子的把手、使車輪更加對稱。然而,使用 INR 和 NeRF 的一個主要挑戰(zhàn)是它們必須在編輯之前先進(jìn)行渲染,編輯工具依賴于渲染和微調(diào) INR 或 NeRF 參數(shù)。

圖 1. 數(shù)據(jù)專用架構(gòu)示例。
來自英偉達(dá)的研究團(tuán)隊試圖把神經(jīng)網(wǎng)絡(luò)用作一種處理器,來處理其他神經(jīng)網(wǎng)絡(luò)的權(quán)重。
表征深度網(wǎng)絡(luò)參數(shù)最簡單的方法是將所有權(quán)重(和偏置)矢量化為簡單的平面向量,然后應(yīng)用全連接網(wǎng)絡(luò)(多層感知機(jī)(MLP))。這種方法可以預(yù)測神經(jīng)網(wǎng)絡(luò)的性能。
但這種方法有一個缺點。神經(jīng)網(wǎng)絡(luò)權(quán)重空間具有復(fù)雜的結(jié)構(gòu),將 MLP 應(yīng)用于所有參數(shù)的矢量化版本會忽略該結(jié)構(gòu),進(jìn)而損害泛化能力。
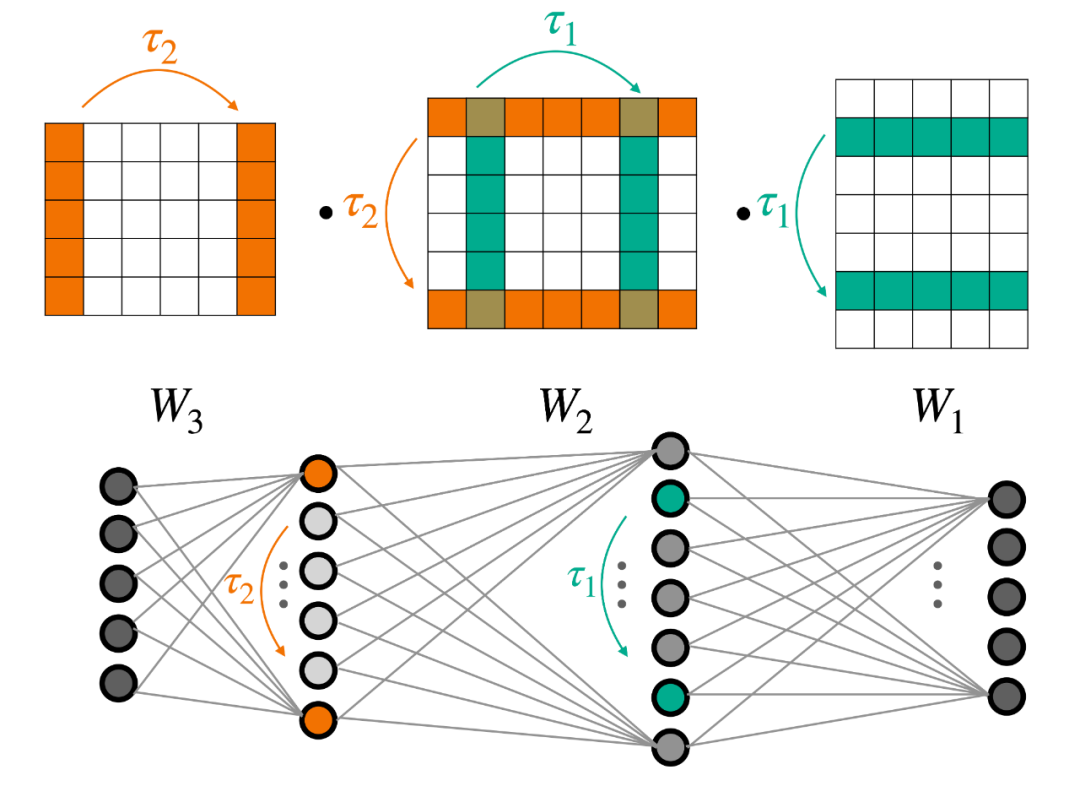
圖 2. 具有兩個隱藏層(下)的多層感知機(jī)(MLP)的權(quán)重對稱性(上)。
幾何深度學(xué)習(xí)(GDL)領(lǐng)域已經(jīng)針對 MLP 的這個問題進(jìn)行了廣泛的研究。
在許多情況下,學(xué)習(xí)任務(wù)對于一些變換是不變的。例如,查找點云類別與給網(wǎng)絡(luò)提供點的順序無關(guān)。但在有些情況下,例如點云分割(point cloud segmentation),點云中的每個點都被分配一個類,那么輸出就會隨著輸入順序的改變而改變。
這種輸出隨著輸入的變換而變換的函數(shù)稱為等變函數(shù)。對稱感知架構(gòu)因其有意義的歸納偏置而具有多種優(yōu)勢,例如它們通常具有更好的樣本復(fù)雜性和更少的參數(shù),這些因素可以顯著提高泛化能力。
權(quán)重空間的對稱性
那么,哪些變換可以應(yīng)用于 MLP 的權(quán)重,使得 MLP 所表征的底層函數(shù)不會改變?
這就涉及到一種特定類型的變換 —— 神經(jīng)元排列。如圖 2 所示,直觀地講,更改 MLP 某個中間層神經(jīng)元的順序,函數(shù)不會發(fā)生改變。此外,每個內(nèi)部層的重新排序過程可以獨立完成。
MLP 可以使用如下方程組表示:

該架構(gòu)的權(quán)重空間被定義為包含矢量化權(quán)重和偏差的所有串聯(lián)的(線性)空間。

重要的是,這樣的話,權(quán)重空間是(即將定義的)神經(jīng)網(wǎng)絡(luò)的輸入空間。
那么,權(quán)重空間的對稱性是什么?對神經(jīng)元重新排序可以正式建模為將置換矩陣應(yīng)用于一層的輸出以及將相同的置換矩陣應(yīng)用于下一層。形式上,可以通過以下等式定義一組新參數(shù):

新的參數(shù)集有所不同,但很容易看出這種變換不會改變 MLP 表示的函數(shù)。這是因為兩個置換矩陣 P 和 P^t 相互抵消(假設(shè)有像 ReLU 這樣的元素激活函數(shù))。
更普遍的,如前所述,不同的排列可以獨立地應(yīng)用于 MLP 的每一層。這意味著以下更通用的變換集不會改變底層函數(shù)。我們將它們視為權(quán)重空間的「對稱性」。

在這里,Pi 表示置換矩陣。這一觀察是由 Hecht-Nielsen 于 30 多年前在論文《ON THE ALGEBRAIC STRUCTURE OF FEEDFORWARD NETWORK WEIGHT SPACES》中提出的。類似的變換可以應(yīng)用于 MLP 的偏差。
構(gòu)建深度權(quán)重空間網(wǎng)絡(luò)
文獻(xiàn)中的大多數(shù)等變架構(gòu)都遵循相同的方法:定義一個簡單的等變層,并將架構(gòu)定義為此類簡單層的組合,它們之間可能具有逐點非線性。
CNN 架構(gòu)就是這種結(jié)構(gòu)的一個很好的例子。在這種情況下,簡單的等變層執(zhí)行卷積運算,CNN 被定義為多個卷積的組合。DeepSets 和許多 GNN 架構(gòu)都遵循類似的方法。有關(guān)更多信息,請參閱論文《Weisfeiler and Leman Go Neural: Higher-Order Graph Neural Networks》和《Invariant and Equivariant Graph Networks》。
當(dāng)目標(biāo)任務(wù)不變時,可以使用 MLP 在等變層之上添加一個不變層,如圖 3 所示。

圖 3:典型的等變架構(gòu)由幾個簡單的等變層組成,后面是不變層和全連接層。
在論文《Equivariant Architectures for Learning in Deep Weight Spaces》中,英偉達(dá)研究者遵循了這個思考。我們的主要目標(biāo)是為上面定義的權(quán)重空間對稱性識別簡單而有效的等變層。不幸的是,表征一般等變函數(shù)的空間可能具有挑戰(zhàn)性。與之前的一些研究(例如跨集合交互的深度模型)一樣,我們的目標(biāo)是表征所有線性等變層的空間。
因此,研究人員開發(fā)了一種新的方法來表征線性等變層,該方法基于如下觀察:權(quán)重空間 V 是表示每個權(quán)重矩陣 V=⊕Wi 的更簡單空間的串聯(lián)。(為簡潔起見,省略了偏差術(shù)語)。
這一觀察非常重要,因為它可以將任何線性層 L:V→V 寫入塊矩陣,其第 (i,j) 塊是 Wj 和 Wi Lij : Wj→Wi 之間的線性等變層。塊結(jié)構(gòu)如圖 4 所示。
但我們?nèi)绾尾拍苷业?Lij 的所有實例呢?論文中列出了所有可能的情況,并表明其中一些層已經(jīng)在之前的工作中得到了表征。例如,內(nèi)部層的 Lii 在跨集交互的深度模型中進(jìn)行了表征。
值得注意的是:在這種情況下,最通用的等變線性層是常見的,僅使用四個參數(shù)的深度集層的泛化。對于其他層,新研究提出基于簡單等變操作的參數(shù)化,例如池化、broadcasting 和小型全連接層,并表明它們可以表示所有線性等變層。
圖 4 展示了 L 的結(jié)構(gòu),它是特定權(quán)重空間之間的分塊矩陣。每種顏色代表不同類型的圖層。Lii 是紅色的。每個塊將一個特定的權(quán)重矩陣映射到另一個權(quán)重矩陣。該映射以依賴于網(wǎng)絡(luò)中權(quán)重矩陣的位置的方式參數(shù)化。

圖 4:線性等變層的塊結(jié)構(gòu)。
該層是通過獨立計算每個塊然后對每行的結(jié)果求和來實現(xiàn)的。英偉達(dá)在論文中涵蓋了一些額外的技術(shù)細(xì)節(jié),例如處理偏差項和支持多個輸入和輸出功能。
我們將這些層稱為深度權(quán)重空間層(DWS 層),并將由它們構(gòu)建的網(wǎng)絡(luò)稱為深度權(quán)重空間網(wǎng)絡(luò)(DWSNet)。我們在這里關(guān)注以 MLP 作為輸入的 DWSNet。
深度權(quán)重空間網(wǎng)絡(luò)的表達(dá)能力
如果我們把假設(shè)類限制為簡單等變函數(shù)的組合,可能會無意中損害等變網(wǎng)絡(luò)的表達(dá)能力,這在上面引用的圖神經(jīng)網(wǎng)絡(luò)文獻(xiàn)中得到了廣泛的研究。英偉達(dá)的論文表明,DWSNet 可以近似輸入網(wǎng)絡(luò)上的前饋操作,這是理解其表達(dá)能力的一步。隨后,新研究證明 DWS 網(wǎng)絡(luò)可以近似 MLP 函數(shù)空間中定義的某些「表現(xiàn)良好」的函數(shù)。
實驗
DWSNet 在兩個任務(wù)系列中進(jìn)行評估。首先采用代表數(shù)據(jù)的輸入網(wǎng)絡(luò),例如 INR。其次,采用代表標(biāo)準(zhǔn) I/O 映射(例如圖像分類)的輸入網(wǎng)絡(luò)。
實驗一:INR 分類
此配置根據(jù) INR 所代表的圖像對 INR 進(jìn)行分類。具體來說,它涉及訓(xùn)練 INR 來表示來自 MNIST 和 Fashion-MNIST 的圖像。任務(wù)是讓 DWSNet 使用這些 INR 的權(quán)重作為輸入來識別圖像內(nèi)容,例如 MNIST 中的數(shù)字。結(jié)果表明,英偉達(dá)提出的 DWSNet 架構(gòu)大大優(yōu)于其他基線。

表 1:INR 分類。INR 的類別由它所代表的圖像定義(平均測試準(zhǔn)確度)。
重要的是,將 INR 分類到它們所代表的圖像類別比對底層圖像進(jìn)行分類更具挑戰(zhàn)性。在 MNIST 圖像上訓(xùn)練的 MLP 可以實現(xiàn)近乎完美的測試精度。然而,在 MNIST INR 上訓(xùn)練的 MLP 卻取得了較差的結(jié)果。
實驗 2:INR 的自監(jiān)督學(xué)習(xí)
這里的目標(biāo)是將神經(jīng)網(wǎng)絡(luò)(特別是 INR)嵌入到語義一致的低維空間中。這是一項很重要的任務(wù),因為良好的低維表示對于許多下游任務(wù)至關(guān)重要。
在這里的數(shù)據(jù)由適合 a\sin (bx) 形式的正弦波的 INR 組成,其中 a、b 從區(qū)間 [0,10] 上的均勻分布中采樣。由于數(shù)據(jù)由這兩個參數(shù)控制,因此密集表示應(yīng)該提取底層結(jié)構(gòu)。

圖 5:使用自監(jiān)督訓(xùn)練獲得的輸入 MLP 的 TSNE 嵌入。
類似 SimCLR 的訓(xùn)練過程和目標(biāo)用于通過添加高斯噪聲和隨機(jī)掩碼來從每個 INR 生成隨機(jī)視圖。圖 4 展示了所得空間的 2D TSNE 圖。英偉達(dá)提出的 DWSNet 方法很好地捕捉了數(shù)據(jù)的潛在特征,而與之對比的方法則比較困難。
實驗 3:使預(yù)訓(xùn)練網(wǎng)絡(luò)適應(yīng)新領(lǐng)域
該實驗展示了如何在不重訓(xùn)練的情況下使預(yù)訓(xùn)練 MLP 適應(yīng)新的數(shù)據(jù)分布(零樣本域適應(yīng))。給定圖像分類器的輸入權(quán)重,任務(wù)是將其權(quán)重變換為在新圖像分布(目標(biāo)域)上表現(xiàn)良好的一組新權(quán)重。
在測試時,DWSnet 接收一個分類器,并在一次前向傳遞中使其適應(yīng)新域。CIFAR10 數(shù)據(jù)集是源域,其損壞版本是目標(biāo)域(圖 6)。

圖 6:使用 DWSNet 進(jìn)行領(lǐng)域適應(yīng)。
結(jié)果如表 2 所示。請注意:在測試時,模型應(yīng)推廣到未見過的圖像分類器以及未見過的圖像。

表 2:使網(wǎng)絡(luò)適應(yīng)新領(lǐng)域。
未來研究方向
英偉達(dá)認(rèn)為,將學(xué)習(xí)技術(shù)應(yīng)用于深度權(quán)重空間的能力提供了許多新的研究方向。首先,尋找有效的數(shù)據(jù)增強(qiáng)方案來訓(xùn)練權(quán)重空間上的函數(shù)有可能會提高 DWSNet 的泛化能力。其次,研究如何將排列對稱性納入其他類型的輸入架構(gòu)和層,如 skip 連接或歸一化層也是很自然的思考。
最后,將 DWSNet 擴(kuò)展到現(xiàn)實世界的應(yīng)用程序,如形變、NeRF 編輯和模型修剪將很有用。可參看 ICML 2023 論文《Equivariant Architectures for Learning in Deep Weight Spaces》。