作者 | Rusell Kohn
編譯 | 言征
ChatGPT 等大型語言模型 (LLM) 已經改變了 AI 格局,了解其復雜性對于充分發揮其潛力至關重要。這篇短文將重點討論大語言模型中的Token限制和記憶。本文旨在讓諸位了解Token限制的重要性、LLM 中的內存概念,以及如何在這些限制內通過交互式界面和 API 以編程方式有效管理對話。
讓我們首先討論一個場景,其中用戶與 LLM 交互并體驗“Token限制和記憶”對對話的影響。
 圖片
圖片
提示:“一個戴著眼鏡、棕色頭發、穿著休閑毛衣的年輕人,坐在溫馨的房間里,在時尚的筆記本電腦上與 AI 語言模型進行交互,周圍漂浮著包含Token的語音氣泡。渲染風格現代且引人入勝。” 由 Russ Kohn 和 GPT4 提示。由 MidJourney 渲染。
一、了解Token和Token限制
1.Token和Token計數
Token是大語言模型文本的構建塊,長度范圍從一個字符到一個單詞。例如,短語“ChatGPT 太棒了!” 由 6 個 token 組成:[“Chat”、“G”、“PT”、“is”、“amazing”、“!”]。這是一個更復雜的例子:“人工智能很有趣(也很有挑戰性)!” 由 7 個標記組成:[“AI”、“is”、“fun”、“(”、“and”、“challenge”、“)!”]。

OpenAI tokenizer 實用程序的屏幕截圖,展示了Token計數的工作原理。
圖片來源:Russ Kohn 和 OpenAI。
注意:上圖中使用的工具來自 OpenAI,可從https://platform.openai.com/tokenizer 獲取。
2.Token限制
模型實現中的Token限制限制了單次交互中處理的Token數量,以確保高效的性能。例如,ChatGPT 3 有 4096 個Token限制,GPT4 (8K) 有 8000 個Token限制,GPT4 (32K) 有 32000 個Token限制。
二、記憶和對話歷史
Token計數在塑造大語言模型的記憶和對話歷史方面發揮著重要作用。將其視為與能夠記住聊天最后幾分鐘的朋友進行對話,使用Token計數來維護上下文并確保對話順利進行。然而,這種有限的內存會對用戶交互產生影響,例如需要重復關鍵信息來維護上下文。
1.背景很重要
上下文窗口從當前提示開始,并返回歷史記錄,直到超出Token計數。就大語言模型而言,之前的一切都從未發生過。當對話長度超過Token限制時,上下文窗口會發生變化,可能會丟失對話早期的關鍵內容。為了克服這一限制,用戶可以采用不同的技術,例如定期重復重要信息或使用更高級的策略。
 圖片
圖片
請注意,如果大語言模型不了解句子的開頭部分,其反應可能會有所不同。
2.聊天體驗:提示、完成和Token限制
參與大語言模型涉及提示(用戶輸入)和完成(模型生成的響應)的動態交換。例如,當你問“法國的首都是哪里?” (提示),大語言模型回答“法國的首都是巴黎”。(完成)。為了在Token限制內優化聊天體驗,平衡提示和完成至關重要。如果對話接近Token限制,您可能需要縮短或截斷文本以保持上下文并確保與大語言模型的無縫交互。
3.超過Token限制和潛在的解決方案
超過Token限制可能會導致不完整或無意義的響應,因為大語言模型會失去重要的背景。想象一下詢問埃菲爾鐵塔并收到有關比薩斜塔的回復,因為上下文窗口發生了變化。要處理Token限制問題,您可以截斷、省略或重新措辭文本以適應限制。一個好的策略是在達到限制之前通過創建摘要來結束當前的對話,然后用該摘要開始下一次對話。另一種策略是寫很長的提示,讓你嘗試一次性對話:向人工智能提供你所知道的一切,并讓它做出一個響應。如果您使用第三方提示管理器,它還可以幫助您管理對話、跟蹤Token限制和管理成本。
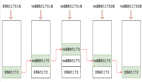
 圖片
圖片
該圖說明了處理大語言模型中Token限制問題的策略,包括截斷文本、總結對話和編寫長的一次性提示。
三、實際應用:管理內容創建中的Token限制
應用本文中討論的策略,我親身體驗了在大語言模型中管理Token限制和上下文的好處。在撰寫本文時,我遇到了前面討論的Token限制問題。對于感興趣的人,我使用了帶有 OpenAI API 的自定義 FileMaker Pro 解決方案,利用了可供 ChatGPT-Plus 訂閱者使用的 GPT-3.5-turbo (ChatGPT) 和 GPT-4 (8k) 模型。我首先精心設計提示來創建故事處理和大綱,然后進行修改。由于對話超出了 GPT-3.5-turbo 的Token限制,我切換到 GPT-4 并總結了開始新對話的目標。使用提示管理器幫助我按項目組織提示并高效工作,而無需依賴 OpenAI 網站。這種方法還有助于分離“元”提示,例如標題和 SEO 優化,來自那些幫助寫作過程的人。在整個過程中,我仔細審查和編輯了生成的內容,以確保質量和連貫性。這個實際示例演示了使用摘要、切換模型和使用提示管理器來管理Token限制的有效性。通過理解和應用這些策略,用戶可以在各種應用(例如內容創建和分析)中充分發揮 ChatGPT 等大語言模型的全部潛力。
四、結論
了解大型語言模型中的Token限制和記憶對于在各種應用程序(例如內容創建、聊天機器人和虛擬助手)中有效利用其功能至關重要。
通過掌握Token、Token計數、對話歷史記錄和上下文管理的概念,您可以優化與 ChatGPT 等 LLM 的交互。希望本文中討論的實用策略(包括管理Token限制和利用提示管理器)能夠讓你自信地暢游人工智能世界。有了這些知識,可以 大大提高探索人工智能未來所帶來的興奮度,并釋放大語言模型在技術、商業和生產力應用方面的更多潛力。
原文鏈接:https://medium.com/@russkohn/mastering-ai-token-limits-and-memory-ce920630349a