掘力計劃第21期 - 螞蟻Ray: 大模型時代的AI計算基礎設施
8月12日,在掘力計劃系列活動第21場《解析大語言模型的訓練和應用》分享中,螞蟻(計算智能技術部)Ray團隊開源負責人,Ray開源社區Committer宋顧楊應邀作了題為《Ray: 大模型時代的AI計算基礎設施》的技術分享。
宋顧楊的分享主題:《Ray: 大模型時代的AI計算基礎設施》。Ray 這個分布式計算引擎框架,可能很多人都沒有聽說過 Ray 這個框架,主要是原因作為一個基礎設施,Ray 往往不以產品的形態出現,而是作為產品的支撐。
如果來說一些基于 Ray 來支撐的一些產品,大家肯定就耳熟能詳了,比如:OpenAI,OpenAI 在今年揭露了一些他們的 GPT 系列產品底層訓練所使用到的分布式計算框架,其中 Ray 框架就被他們重點指出了其所發揮的作用。
1. Ray 的演進
Ray 從誕生之初,其實是作為一款強化學習方面的框架被創造出來,隨著時代的不斷變化,Ray 也被加入了更多的功能,其定位也在慢慢發生改變,先來看一下 Ray 的發展歷程:
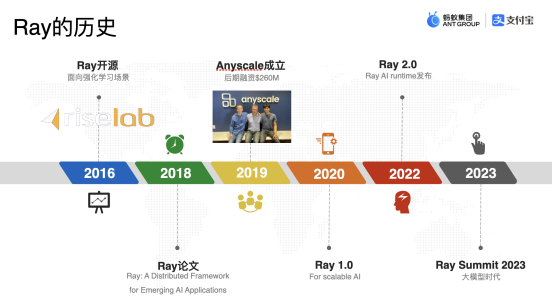
從誕生到現在,Ray 經歷了七年的發展,從一開始的強化學習方向到現在的AI方向,Ray 的團隊及其開源社區也做了很多的努力,其中宋顧楊所在的螞蟻集團從 2017 年就開始采用 Ray 框架作為支撐,并為 Ray 內核貢獻了超過 26% 的代碼,所以 Ray 框架其實在螞蟻的各個場景內都有涉及,并且螞蟻集團也為其發展也貢獻了不小的力量:
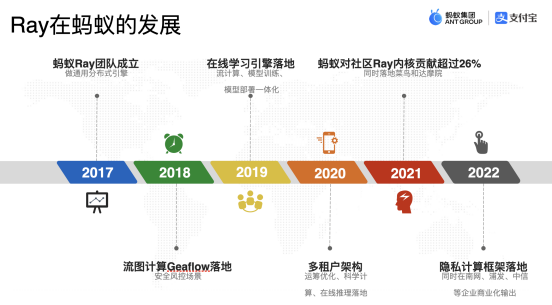
到目前為止,Ray 的定位就是一款面向 AI 的新一代 AI 計算框架,同時也是一款通用分布式計算框架。
Ray 在計算系統中解決的核心問題可以用一張圖來概括:
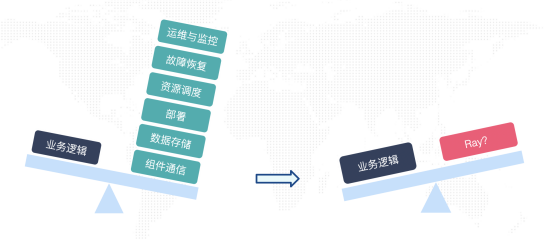
對于任何一個分布式系統研發團隊來講,他們會面臨一些很重復的問題,就是上圖右邊的這些問題,這些問題會耗費整個研發團隊很多不必要的經歷,Ray 來解決的就是這么一個問題,讓研發團隊更專注于自身的業務系統上而非通用問題上。
2. Ray 核心能力
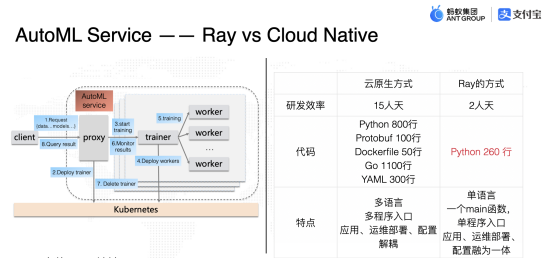
通過上面分享人給的例子圖,可以看出 Ray 對于整個計算任務有很強的優化,無論是從效率還是功能上,都遠遠超過傳統的云原生計算方式。
Ray 能有這么大的提高,離不開它的一些核心設計點:
- 不綁定計算模式:把單機編程中的基本概念分布式化。
- 無狀態計算單元:通過簡單的注解就可以讓一個本地方法放到遠程機器上執行。
- 有狀態的計算單元:輕松將一個本地類部署到遠程機器上,類serverless。
- 分布式 Object:多節點之前 Object 傳輸,自動垃圾回收。
- 多語言和跨語言:Ray 支持 Java、Python、C++,并且可以做跨語言調用。
- 資源調度:注解聲明式任務需要分配的資源,比如 CPU,是否同一節點。
- 自動故障恢復:Ray 所有組件都具有自動恢復功能,用戶無需關心其底層細節,聲明其實現即可。
- 運行時環境依賴:針對不同的任務可以直接聲明不同的運行環境,比如需要一個帶 tensorflow 的 python 環境。
- 運維:完善的運維與監控功能與可視化頁面。
雖然實現了這么多強大的功能,Ray 的架構卻是非常的簡潔高效:
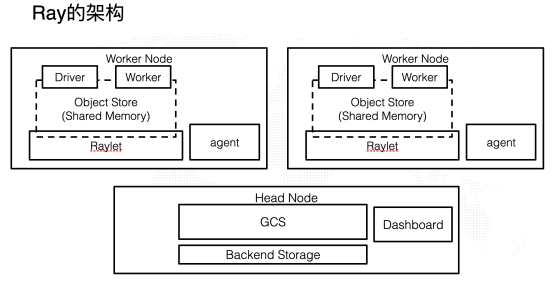
具體想要了解具體 Ray 的架構協作方式可以參考他們的官方文檔,在這里就不多做闡述了。
3. Ray 的開源生態與案例
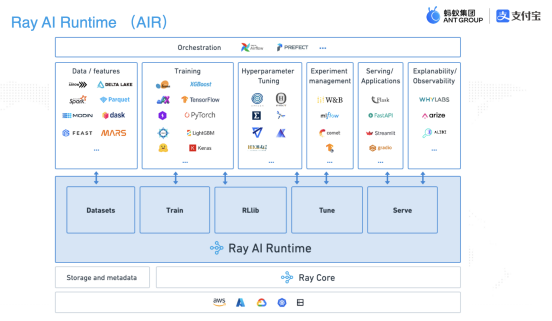
上圖就是 Ray 支持的 AI 生態的全景圖,幾乎涵蓋了市面上所有主流框架,也就是說,在 Ray 里面可以很方便的上面這些框架做集成。
通過這些框架集成,Ray 也可以將整個AI pipeline執行過程串聯成以下四個大步驟:
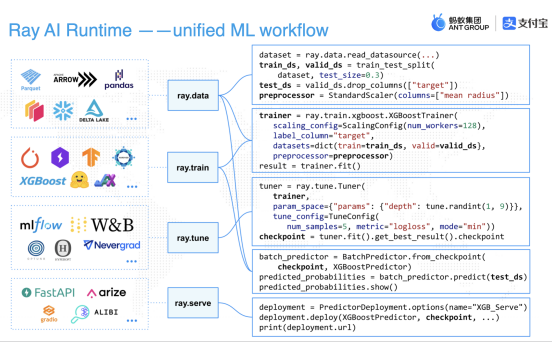
Data -> train -> tune -> serve,這四步涵蓋了所有分布式訓練的主要功能:
- 數據預處理。
- 深度學習。
- 深度調優。
- 在線推理。
在 Ray 中,你可以通過短短百行代碼完成以上所有步驟。
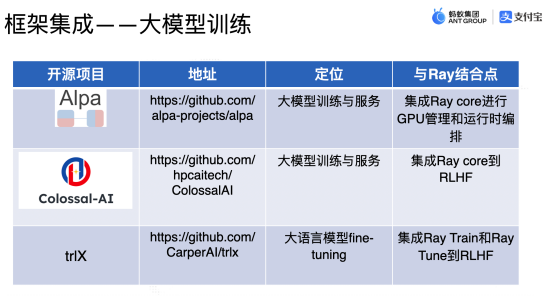
在開源大模型訓練方面,也有許多大型項目在使用 Ray:
在企業級應用方面,大家最耳熟能詳的應該就是 ChatGPT-4了:

除了 OpenAI 之外,還有許多來自全球各地的公司在深度使用 Ray:

最后,如果大家對 Ray 這個框架感興趣,可以去其官網了解關于它的更多內容~