高效構建 vivo 企業級網絡流量分析系統

一、概述
隨著網絡規模的快速發展,網絡狀況的良好與否已經直接關系到了企業的日常收益,故障中的每一秒都會導致大量的用戶流失與經濟虧損。每一家企業都在不斷完善自己的網絡監控手段,但在監控體系建設過程中,卻又不可避免的面臨以下難點:
- 網絡流量數據龐大:由于網絡流量的規模和復雜性都非常高,很難對大量的數據進行有效的監控和分析。
- 流量數據采集分析建設成本高昂:為獲取準確的流量數據,需要使用高效的數據采集技術和大容量的存儲設備,以及大量的開發資源,這使得監控成本直線上升
- 監控手段單一、缺乏擴展性:傳統的監控手段一般只能監控固定的幾個數據點,難以針對不同的網絡環境進行定制化和擴展。
- 難以快速定位和解決問題:由于網絡流量數據量大、變化頻繁,往往需要花費大量的時間和精力才能找出問題根源。
因此,如何利用盡可能低的監控成本快速發現網絡問題與定位異常流量已經成為大型企業內必須優先解決的問題,諸多網絡流量分析技術也同時應運而生。
sFlow技術就是這樣一種高效、靈活的解決方案。它可以通過流量采樣技術抽取數據包中的部分信息,從而實現對大量網絡流量數據進行持續監控。同時,sFlow技術還具有靈活的配置和擴展性,可以根據實際需求進行定制,并支持多種網絡設備和協議。這些優勢使得sFlow技術在現代網絡監控和管理中得到廣泛應用。
二、常見的網絡流量采集技術
主流的網絡流量采集主要分為全流量采集與采樣流量采集兩種。
2.1 全流量采集
全流量采集包括端口鏡像、分光設備等方式。在流量龐大的網絡中,使用端口鏡像方式不僅會導致全鏈路時延增加,而且會使吞吐量龐大情況下的網絡設備壓力激增。分光設備雖然可以降低鏈路時延,但同樣存在采購價格高昂的門檻。除此之外,由于大型企業內IDC規模龐大,由此導致的全流量數據量也會激增,想要完整的靠自研做好全流量數據分析,不僅需要一定的存儲計算資源,也需要一定的軟件開發周期,不利于項目的快速搭建成型。
2.2 采樣流量采集
在流量分析系統欠缺的情況下,使用采樣分析的優勢就體現出來了,相對于全流量,他部署成本低,數據分析代價小,很適合對異常流量的快速定位以及網絡內的趨勢占比分析。以下主要對比介紹sFlow與Netflow兩種采樣方式的優缺點。

sFlow在流量監控上范圍更廣,在滿足硬件要求的IDC內部環境,使用sFlow進行采樣流量監測,可以有效降低網絡設備負載,并且提供實時流量監控手段,以應對突發網絡異常場景。
三、基于sFlow的系統設計
3.1 基礎設計
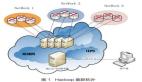
在滿足硬件條件的情況下,基于sFlow的基礎系統設計很簡單,使用sFlow agent + sFlow collector + sFlow analyser即可實現整個流程的數據閉環。
sFlow agent:通過enabled相關網絡設備上的sFlow能力,設定采樣比等參數并制定收集端相應地址,即可對端口收發流量進行采集。agent側更重要的反而是如何確定采集的網絡設備范圍,相對于無目的的全量網絡設備部署,針對邊界核心網絡設備進行部署更有意義,因為所有的對外流量最終都必須經過邊界網絡設備。在能更好監控外部流量異常的情況下,也能減輕數據存儲負擔。
sFlow collector:收集并解析agent側采集傳輸的 sFlow datagrams。
sFlow analyser:對格式化的數據進行可視化分析展示,以供網絡管理員進行有效觀測分析。
 圖片
圖片
3.2 開源+自研:架構進階
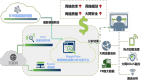
在確定了基本架構之后,如何進行組件選用與定制化功能擴充,開源解決方案elastiflow為我們提供了很好的示例,筆者基于開源進行了擴展,以滿足更多定制化功能。
sFlow agent:使用上報統一vip的形式進行端口流量采樣(官方規定的采樣比需是2^n),可以利用vip的LB能力進行負載均衡,使得sFlow報文均衡打到收集端固定端口。針對不同的網絡線路設定不同的采樣比,在降低數據存儲的同時也可以保證重要線路更高的精準性。
 圖片
圖片
sFlow collector:使用ELK套件進行數據收集與可視化分析是比較成熟的技術方案之一。因此,收集端我們使用logstash進行原生數據報文收集與解析。elastiflow的作者使用了logstash內原生的udp-sFlow報文解析組件進行數據解析,但筆者在實際測試中發現,雖然該方案能得到結構化更好的數據格式,但在數據解析的性能表現上很差,在數據量龐大的情況下會造成大量數據丟包現象,導致數據準確性下降。而sFlowtool由于底層是基于C語言來編寫的,在性能表現上很優異,單物理機(32c64g)即可達到10w+tps,雖然對sFlow報文解析后的數據結構化要弱一點,但可以在后續分析模塊對數據進行清洗與結構化構建。sFlowtool分析的數據示例如下所示。經由logstash的數據發送到kafka消息隊列中。
[root@server src]# ./sFlowtool -l
FLOW,10.0.0.254,0,0,00902773db08,001083265e00,0x0800,0,0,10.0.0.1,10.0.0.254,17,0x00,64,35690,161,0x00,143,125,80
FLOW后的字段釋義如下
agent_address
inputPort
outputPort
src_MAC
dst_MAC
ethernet_type
in_vlan
out_vlan
src_IP
dst_IP
IP_protocol
ip_tos
ip_ttl
udp_src_port OR tcp_src_port OR icmp_type
udp_dst_port OR tcp_dst_port OR icmp_code
tcp_flags
packet_size
IP_size
sampling_ratesFlow analyser:通過從kafka實時消費數據,將數據進行清洗結構化,并借助三方meta data,對解析后的數據進行軟件定義,以便于后續存儲與分析。
database+display:使用Elasticsearch+Kibana進行存儲與可視化展示,同時也可以利用mertic beat對logstash的采集性能進行監控。Kibana作為Bi類的數據可視化方案,提供了大部分可供免費使用的圖表及Dashboard,可以很好的進行可視化分析。
3.3 分析端軟件定義
擁有原生數據的情況下,我們已經能基于一些ip五元組等進行基本會話流量分析。但是流量數據所能體現的價值遠不止這些,利用企業內其他的cmdb等平臺,可以為我們的流量數據提供更大價值。
網絡設備維度:通過數據內的交換機地址,出入向端口,可以根據采集配置的交換機端口index,判斷該條流量出入向。也可基于網絡設備ip,賦予其通道,線路,以及設備名等等其他屬性。
ip維度:ip五元組提供了探索數據更高的可能,我們可以根據歸屬ip,判斷他的項目,部門等歸屬信息,也可反向關聯域名。這在對異常流量進行分析判斷時能夠快速定位到所屬業務方,很大程度提高了運維效率。
3.4 壓縮存儲與可視化自研
由于Elasticsearch本身的數據壓縮效果不夠理想,使得我們在進行長時間存儲數據時體量龐大臃腫。相應的,olap型數據庫Druid很好地解決了這個問題,數據采樣后經過分析端嚴格的結構化處理,可以在Druid內實現很好的數據壓縮。除此之外,Druid內嵌的數據預聚合能力也能更好的幫助我們對歷史數據進行降精處理,減少存儲壓力。切換存儲引擎后,也就意味著沒辦法再使用Kibana進行通用展示,使用自研的web服務框架也能夠應對靈活的需求場景,實現更多定制化的分析。
3.5 基于Celery設計的輕量流處理模型
雖然流量數據經過了采樣降精,但整體的數據量依然很龐大。高效快速的進行流處理,降低整體系統時延至30s內,能夠更快的幫助網絡管理人員發現問題,除卻利用傳統的流處理工具外,我們也可以使用Celery來構建一個輕量高效易擴展的分布式流處理集群。
 圖片
圖片
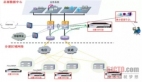
Celery是一個簡單、靈活且可靠的,處理大量消息的分布式系統,專注于實時處理的異步任務隊列,同時也支持任務調度。我們基于celery實時異步處理的特性,設計 celerybeat → watcher → producer → consumer 的消費鏈路來進行流處理。
celery beat:作為定時任務的觸發器,每1s向watcher隊列里派發一個新任務。
watcher worker:在隊列中拿到任務后,轉發給producer,并根據設置的隊列最大值,對producer隊列進行擁塞控制。
producer worker:在隊列中拿到任務后,從kafka中獲取采集的流量數據,按照batch size批量發送給consumer隊列,并根據設置的隊列最大值,對consumer隊列進行擁塞控制。
consumer worker:在隊列中拿到任務后,根據本地緩存/共享緩存內的業務信息,對采集數據進行數據清洗,打業務標簽等操作,并寫入另一kakfa或直接寫入database。
每一個角色以及節點可以通過Celery broker進行通信,實現分布式集群部署,針對consumer單元化操作,可以使用eventlet以協程方式啟動,以保證集群高并發消費。
四、應用場景
4.1 機房維度流量分析
通過基于網絡cmdb的ip匹配,對流量數據進行機房維度的匯總,可以得到機房整體的對外出入向流量分析,在IDC同外部交互時,整體流量的趨勢變化,是判斷帶寬占用程度的直接標準。

4.2 網絡線路信息關聯
通過對網絡設備基于ip+ifindex的邏輯信息映射,可以對核心通道線路做到聚合展示,在針對一些公網線路異常,專用線路帶寬打滿等異常問題時,通過觀察線路分析可以直接準確定位故障發生的第一時間點。

4.3 ip會話信息挖掘
雖然sflow只截取了報文的頭部信息而不包含數據包部分,但ip五元組本身也提供了極大的網絡流量分析價值。
利用會話信息,我們可以準確有效的定位異常流量的ip歸屬,通過ip+服務端口的,我們甚至可以定位具體產生流量異常的服務與進程,從而做出下一步決策。除此之外,ip也能同企業內CMDB產生聯動,定位到ip所屬資源的所在資源組,從而得到不同部門/行政組產生的流量占比分析,這同時也有利于在產生異常流量時第一時間感知到相關業務,并進行通知管控。

4.4 ip歸屬地分析
除了結合內部信息,通過運營商提供的歸屬地信息,我們可以查看ip訪問的來源,進行相關歸屬地分析與Dashboard制作。

五、總結
要實現對網絡全面、實時的監控分析必須依靠先進有效的網絡監控協議和技術來滿足業務日益增長的需求。基于sFlow的流量分析雖然在輕量化構建上有著很大的優勢,在面對異常流量時也能夠基于流量趨勢與分布占比做出快速反應。但sFlow本身的采樣卻不包含報文內數據包的信息,針對一些sql注入、數據安全等等網絡安全攻防問題,沒辦法提供準確定位與解決方案。因此,全流量分析也應是流量分析系統未來必不可少的一環,兩者相結合才能夠提供更全面、更精細化的流量監控,為數據中心的網絡安全保駕護航。
六、未來展望
雖然sFlow技術在網絡性能監控和管理領域中得到了廣泛應用,但在未來更大規模的網絡流量場景沖擊下,還需要具備更多的能力:
1.支持更多協議和應用:sFlow監控的思想不僅適用于網絡流量,還可以監控應用流量、虛擬化環境、云平臺等。未來,sFlow技術應該支持更多的協議和應用,以更好地適應新型網絡環境。
2.自適應流量采集技術:sFlow技術的流量采集技術是固定周期的,但是隨著網絡流量的變化,固定周期的采集可能無法準確反映網絡實時狀態。未來,sFlow監控技術應該支持自適應流量采集技術,能夠根據實際網絡流量變化自動調整采集周期。
3.便捷的管理功能:sFlow目前的配置更多依賴于網絡管理人員在交換機上進行配置,無法實現一鍵下發,自動發現,快速調整采樣比等等功能,未來更需要一個能夠便捷下發命令,熱加載配置變更的sFlow管理平臺。