像GPT-4一樣能看懂圖文,李飛飛等人的具身AI給機器人造了個多模態對話框
是時候給大模型造個身體了,這是多家頂級研究機構在今年的 ICML 大會上向社區傳遞的一個重要信號。
在這次大會上,谷歌打造的 PaLM-E 和斯坦福大學李飛飛教授、英偉達高級研究科學家 Linxi "Jim" Fan(范麟熙,師從李飛飛)參與打造的 VIMA 機器人智能體悉數亮相,展示了具身智能領域的頂尖研究成果。
 圖片
圖片
PaLM-E 誕生于今年 3 月份,是一個參數量達 5620 億的具身多模態語言模型,集成了參數量 540B 的 PaLM 和參數量 22B 的視覺 Transformer(ViT),是目前已知的最大的視覺 - 語言模型。利用這個大模型控制機器人,谷歌把具身智能玩出了新高度。它能讓機器人聽懂人類指令,并自動將其分解為若干步驟并執行,越來越貼近人類對于智能機器人的期待和想象(更多細節參見:《5620 億參數,最大多模態模型控制機器人,谷歌把具身智能玩出新高度》)。

VIMA 則誕生于 2022 年 10 月,是一個基于 Transformer 架構的(仿真)機器人智能體,由來自斯坦福大學、瑪卡萊斯特學院、英偉達、加州理工學院、清華大學、德克薩斯大學奧斯汀分校的多位研究者合作完成。論文一作 Yunfan Jiang 是斯坦福大學即將入學的計算機科學博士研究生,曾在英偉達實習,與 Linxi "Jim" Fan 等人合作。

- 論文地址:https://arxiv.org/pdf/2210.03094.pdf
- 論文主頁:https://vimalabs.github.io/
- Github 地址:https://github.com/vimalabs/VIMA
VIMA 智能體能像 GPT-4 一樣接受 Prompt 輸入,而且輸入可以是多模態的(文本、圖像、視頻或它們的混合),然后輸出動作,完成指定任務。
比如,我們可以要求它把積木按照圖片所示擺好再還原:

讓它按照視頻幀的順序完成一系列動作:

給出一些圖示讓它學習新概念:

通過圖文混合提示對它施加一些限制:

為什么要研發這樣的機器人智能體?作者在論文中寫道:
在 GPT-3 等大模型中,基于 Prompt 的學習為將自然語言理解任務傳達給通用模型提供了一種便捷靈活的接口。因此,他們設想,一臺通用機器人也應該具備類似的直觀且富有表現力的任務規范接口。
以家務機器人為例,我們可以通過簡單的自然語言指令要求機器人給我們拿一杯水。如果有更具體(但語言難以準確描述)的需求,我們可以把指令改為語言 + 圖像(給機器人指令的同時再給他一張參考圖像,比如某個水杯的照片)。如果需要機器人學習新技能,機器人應該能夠借助幾個視頻來自學、適應。需要與不熟悉的物體交互時,我們應該能通過幾張簡單的圖像示例來教會機器人新的基本概念。最后,為了確保安全部署,我們可以進一步指定視覺約束,如「不要進入房間」。
為了讓一個機器人智能體具備所有這些能力,作者在這項工作中做出了三個關鍵貢獻:
1、提出了一種新的多模態 prompting 形式,將各種各樣的機器人操作任務轉換為一個序列建模問題;
2、構建了一個大型基準,包含多樣化的任務,以系統評估智能體的可擴展性和泛化能力;
3、開發了一個支持多模態 prompt 的機器人智能體,能夠進行多任務學習和零樣本泛化。
他們從以下觀察開始:許多機器人操作任務可以通過語言、圖像、視頻的交織多模態 prompt 來描述(見圖 1)。例如在重新排列任務中,我們可以給機器人輸入以下圖文 prompt:「請重新排列物品,使其與 {某場景圖} 相一致」;在少樣本仿真中,prompt 可以寫成「遵循積木的運動軌跡:{視頻幀 1}, {視頻幀 2}, {視頻幀 3}, {視頻幀 4}」。
 圖片
圖片
多模態 prompt 不僅比單個模態有更強的表達能力,還為訓練通用型機器人提供了統一的序列 IO 接口。以前,不同的機器人操作任務需要不同的策略架構、目標函數、數據處理流程和訓練過程,導致孤立的機器人系統無法輕易地結合多樣的用例。相反,作者在論文中提出的多模態 prompt 接口使他們能夠利用最新的大型 Transformer 模型進展,開發可擴展的多任務機器人學習器。
為了系統評估使用多模態 prompt 的智能體,他們開發了一個名為 VIMA-BENCH 的新基準測試,該基準構建在 Ravens 模擬器上。他們提供了 17 個具有多模態 prompt 模板的代表性任務。每個任務可以通過不同紋理和桌面物體的各種組合進行程序化實例化,產生數千個實例。VIMA-BENCH 建立了一個四級協議,逐步評估智能體的泛化能力,如圖 2 所示。

該研究引入了 VIMA(VisuoMotor Attention agent)來從多模態 prompt 中學習機器人操作。模型架構遵循編碼器 - 解碼器 transformer 設計,這種設計在 NLP 中被證明是有效的并且是可擴展的。
為了證明 VIMA 具有可擴展性,該研究訓練了 7 個模型,參數范圍從 2M 到 200M 不等。結果表明本文方法優于其他設計方案,比如圖像 patch token、圖像感知器和僅解碼器條件化(decoder-only conditioning)。在四個零樣本泛化級別和所有模型容量上,VIMA 都獲得了一致的性能提升,有些情況下提升幅度很大,例如在相同的訓練數據量下,VIMA 任務成功率提高到最多 2.9 倍,在數據量減少 10 倍的情況下,VIMA 性能提高到 2.7 倍。
為了確保可復現性并促進社區未來的研究工作,該研究還開源了仿真環境、訓練數據集、算法代碼和預訓練模型的 checkpoint。
方法介紹
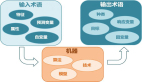
本文旨在構建一個機器人智能體,該智能體可以執行多模態 prompt 任務。本文提出的 VIMA 兼具多任務編碼器 - 解碼器架構以及以對象為中心的設計。VIMA 的架構圖如下:

VIMA 完整的演示流程:
具體到細節,首先是輸入 prompt,VIMA 包含 3 種格式:文本、包含單個對象的圖像、包含全場景的圖像。
- 對于輸入文本,該研究使用預訓練的 T5 tokenizer 和詞嵌入來獲取詞 token;
- 對于全場景圖像,該研究首先使用領域微調 Mask R-CNN 提取單個對象。每個對象通過 bounding box 和裁剪的圖像來表示,之后分別使用 bounding box 編碼器和 ViT 對它們進行編碼,從而得到對象 token;
- 對于單個對象的圖像,除了使用虛擬 bounding box,該研究以相同的方式獲得 token。
然后,該研究遵循 Tsimpoukelli 等人的做法,通過預訓練的 T5 編碼器對 prompt 進行編碼。由于 T5 已在大規模文本語料庫上進行了預訓練,因而 VIMA 繼承了語義理解能力和穩健性質。為了適應來自新模態的 token,該研究在非文本 token 和 T5 之間插入了 MLP(多層感知機)層。
接著是機器人控制器。如上圖 3 所示,機器人控制器(解碼器)通過在 prompt 序列 P 和軌跡歷史序列 H 之間使用一系列交叉注意力層來對其進行條件化。
該研究按照 Raffel 等人中的編碼器 - 解碼器約定,從 prompt 中計算關鍵鍵序列 K_P 和值序列 V_P,同時從軌跡歷史中查詢 Q_H。然后,每個交叉注意力層生成一個輸出序列 ,其中 d 是嵌入維度。為了將高層與輸入的軌跡歷史序列相連接,該研究還添加了殘差連接。
,其中 d 是嵌入維度。為了將高層與輸入的軌跡歷史序列相連接,該研究還添加了殘差連接。
研究中還用到了交叉注意力層,其具有三個優勢:1)加強與 prompt 的連接;2)保持原始 prompt token 的完整和深入流動;3)更好的計算效率。VIMA 解碼器由 L 個交替的交叉注意力層和自注意力層組成。最后,該研究遵循 Baker 等人的做法,將預測的動作 token 映射到機械臂離散姿態。
最后是訓練。該研究采用行為克隆(behavioral cloning)訓練模型。具體而言,對于一個包含 T 個步驟的軌跡,研究者需要優化函數 。整個訓練過程在一個離線數據集上進行,期間沒有訪問仿真器。為了使 VIMA 更具魯棒性,該研究采用了對象增強技術,即隨機注入 false-positive 檢測輸出。訓練完成后,該研究選擇模型 checkpoint 進行評估。
。整個訓練過程在一個離線數據集上進行,期間沒有訪問仿真器。為了使 VIMA 更具魯棒性,該研究采用了對象增強技術,即隨機注入 false-positive 檢測輸出。訓練完成后,該研究選擇模型 checkpoint 進行評估。
實驗
實驗旨在回答以下三個問題:
- 基于多模態 prompt,構建多任務的、基于 transformer 的機器人智能體的最佳方案是什么?
- 本文方法在模型容量和數據大小方面的縮放特性是什么?
- 不同的組件,如視覺 tokenizers、prompt 條件和 prompt 編碼,如何影響機器人的性能?
下圖(上部)比較了不同模型大小(參數范圍從 2M 到 200M)的性能,結果表明,VIMA 在性能上明顯優于其他方法。盡管像 VIMA-Gato 和 VIMA-Flamingo 這樣的模型在較大的模型大小下表現有所提升,但 VIMA 在所有模型大小上始終表現出優異的性能。
下圖(底部)固定模型大小為 92M,比較了不同數據集大小(0.1%、1%、10% 和完整數據)帶來的影響。結果表明,VIMA 具有極高的樣本效率,可以在數據為原來 1/10 的情況下實現與其他方法相當的性能。

對視覺 tokenizer 的消融研究:下圖比較了 VIMA-200M 模型在不同視覺 tokenizer 上的性能。結果表明,本文提出的對象 token 優于所有直接從原始像素學習的方法,此外,這種方法還優于 Object Perceiver 方法。

下圖表明,交叉注意力在低參數狀態和較難的泛化任務中特別有用。